与 ChatGPT o3 共同设计稀疏音乐编解码器
akuz.me/nko
🎛️ 一天内使用 ChatGPT o3 共同设计稀疏音乐编解码器 — 我的迷你 Pied Piper
- Sat 26 April 2025
- Experiments
- akuz
多年来,我一直想构建一个超密集型电子音乐压缩器:仅保留真正重要的循环和相位提示,然后完美地重新合成音轨。然而,晚上和周末的时间永远不够用来设计模型、编写数学公式和处理 PyTorch。最近,我打开了运行新 o3 模型的 ChatGPT,并将其视为设计伙伴。如果我们能够保持对话的专注,也许我们可以在一个时间段内勾勒出整个想法并制作原型。
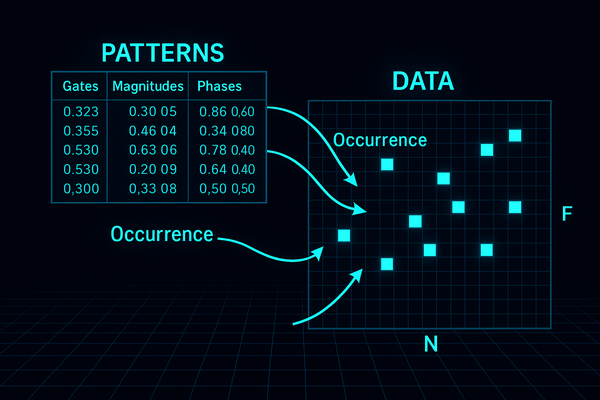
共同设计生成模型
我们首先确定数据应该是什么样子。我想要一个相位感知的频谱图——𝐹 × 𝑁 网格上的复数——从一些可重用的模式和一个稀疏的出现列表重建。我提出了细节;o3 回复了方程式。我们将 3 × 3 窗口换成了 5 × 5,移除了全局增益,然后重新引入了每次出现的幅度,并用双线性插值代替了硬钳位,以便梯度可以流动。经过几次迭代,我们冻结了一个检查点:单位归一化模式、编码为相位的分数偏移、通过两个复数而不是固定索引定位的事件。 o3 用 LaTeX 排版了整个公式,我将其编译成了一个简洁的 PDF。

实现和调试第一个学习循环
然后,o3 生成了一个干净的 repo:用于模式、事件、可微分 lattice writer 和训练脚本的单独模块。第一次运行显示损失下降,但每个模式仍然为零。在聊天中,我们追踪到问题的原因是硬门,它在梯度到达幅度之前使幅度静音;用软权重替换 mask 立即解决了问题,并且模式开始发展非零幅度和相位。为了可见性,我们添加了一个简单的 ASCII 热图,该热图直接在终端中打印目标频谱图、重建及其差异。
用于调试的 ASCII 图示
我将数据(复数网格)初始化为一个波浪形模式(幅度 的 ASCII 表示):

仅使用 4 个模式的 5000 个事件,该算法能够压缩大约 1/3 的数据(显然可以增加事件的数量,但我决定保留此结果,以便它显示此压缩如何受到算法约束的限制,即模式的大小和数量以及事件的数量):

下面的 ASCII 图示显示了算法未描述的数据部分,这是由于模式和事件的数量有限。

一个工作日之后...
到了晚上,该模型可以使用小字典和远少于像素的事件来重建合成测试网格。没有大量的设计文档,也没有周末的编码马拉松——只有一整天与 AI 伙伴的迭代对话。接下来的步骤很明确:将代码推送到 GitHub,在真实的电子音乐轨道上进行训练,并测量我们可以将比特率降低到多低。
此原型有何不同
关键细节是事件未绑定到 lattice。每个中心都存储为两个单位复数,它们的相位映射到连续坐标,因此模式可以放置在任何位置——甚至在网格单元之间——而梯度仍然流动。因此,单个模式可以在任意偏移处重用,而不是为每次移位克隆。第一个实验表明,相位参数化放置可以将密集频谱图转换为一组稀疏的无网格构建块,从而为极其紧凑的音乐压缩打开了大门。
结论
与 ChatGPT o3 合作感觉就像与一位总是醒着的科研同事配对:每个问题都立即得到解答,每次编辑都当场编译,并且障碍在几分钟而不是几个月内消除。一个在我的“总有一天”笔记本中存在多年的实验——设计一个无网格的、相位感知的音乐压缩器——在经过一天的对话和迭代编码后,从草图变成了运行原型。如此快速地将长期存在的想法转化为有形的结果既令人振奋,又让我们得以一窥近期的研究将会是什么样子。激动人心的时刻! 请在此处查看 GitHub 仓库 这里。