NASA 如何使用图技术和 LLM 构建人员知识图谱
How NASA is Using Graph Technology and LLMs to Build a People Knowledge Graph
By Sabika Tasneem 10 min read April 24, 2025
有没有想过 NASA 如何识别其顶级专家,组建高效团队,并为未来的技能做规划? 答案就在他们的人员图谱中!
这是一个利用图数据库和大型语言模型 (LLMs) 改造 NASA 人员分析的创新举措。
错过了社区讨论? 观看完整的 NASA x Memgraph 社区讨论点播,更深入地了解他们的架构、实时演示和专家问答。
Introduction
本次社区讨论由 NASA 的 People Analytics team 成员主导,他们是人员知识图谱开发的幕后功臣:
- David Meza , Branch Chief of People Analytics and Head of Analytics for Human Capital at NASA
- Madison Ostermann , Data Scientist and Data Engineer
- Katherine Knott , Data Scientist
他们分享了如何结合图数据库、大型语言模型 (LLMs) 和安全的 AWS 基础设施,将整个机构的人员、项目和技能联系起来。
最终形成了一个由图驱动的系统,能够进行主题专家发现、项目相似性分析,并生成实时组织洞察,所有这些都可以通过 Cypher 查询和由 GraphRAG 驱动的聊天机器人界面访问。
以下是会话期间分享的关键技术要点和实时演示的分解:
Talking Point 1: Why NASA Needed a People Knowledge Graph
传统关系数据库中的人员数据非常混乱,充斥着行、列和连接操作。
它并不适合像 NASA 这样的大型组织中存在的复杂关系。
图数据库则颠覆了这一点。它们不是将数据扁平化到电子表格中,而是将人员与技能、项目甚至他们的职业道路联系起来,从而能够回答以下问题:
- “在 NASA 的各个中心,谁参与过高度相似的 AI 项目?”
- “哪些员工具有 AI/ML 跨学科专业知识?”
- “我们需要填补哪些技能缺口?”
NASA 使用 Memgraph 实时处理所有这些,让他们的团队能够无缝地查询和遍历多跳关系。
Talking Point 2: Infrastructure and Deployment
整个解决方案在 NASA 安全的内部 AWS 云上运行。
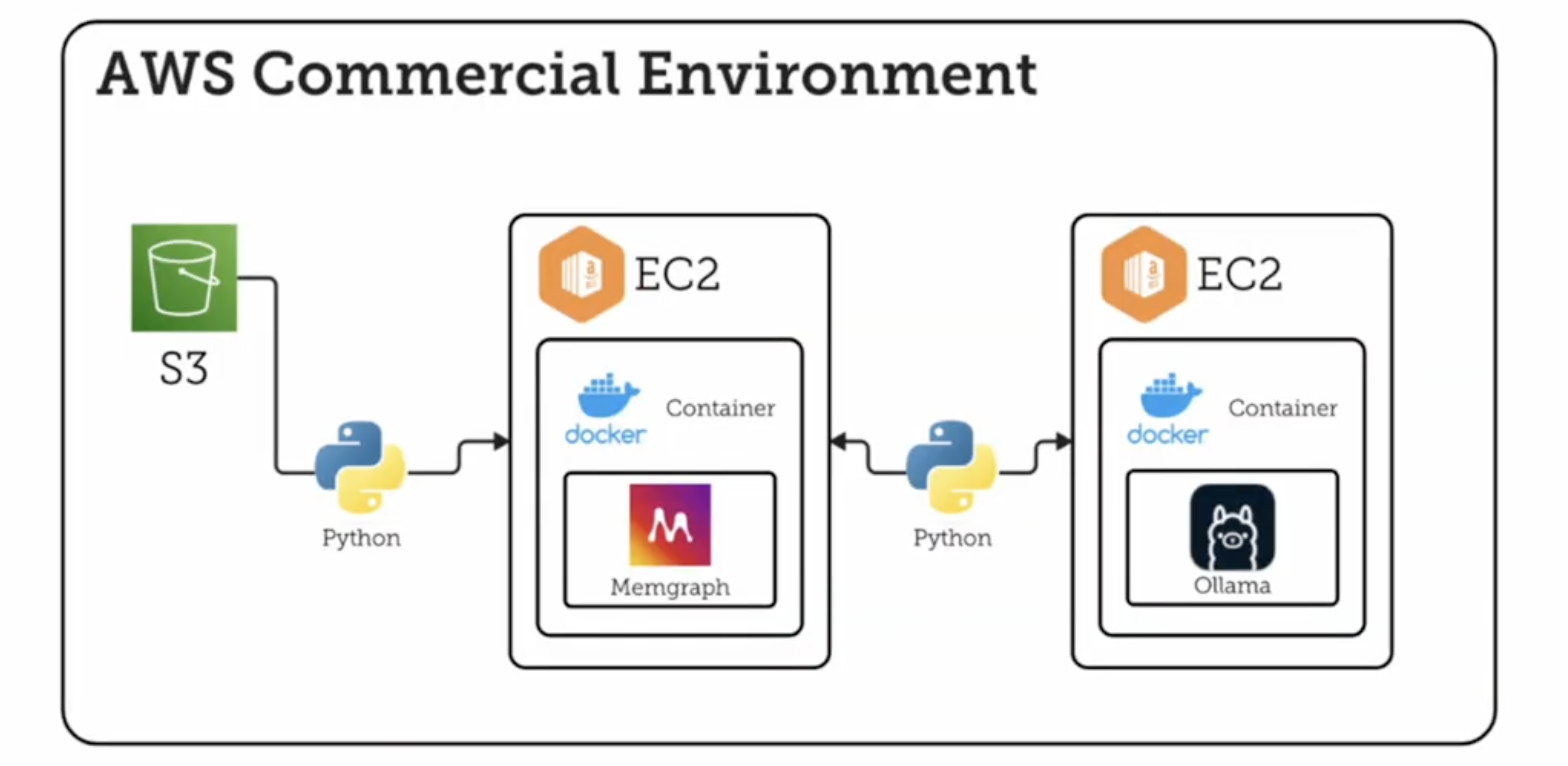
关键组件包括:
- 在 EC2 实例上的 Docker 中运行的 Memgraph。
- 部署在 EC2 中的 On-prem LLM server (Olama),用于技能提取和聊天机器人查询。
- AWS S3 buckets,用于存储结构化和非结构化数据。如果您需要从 S3 迁移,请 查看此链接!
- GQLAlchemy,用于使用 Cypher 将数据从 S3 导入 Memgraph。
Memgraph 的企业许可证 允许 NASA 将数据分段到多个数据库中,从而保证个人身份信息 (PII) 的安全和隔离。
Talking Point 3: Data Ingestion and Skill Extraction
该团队使用 from gqlalchemy import Memgraph 将来自多个来源的数据导入 Memgraph:
- 来自 NASA 内部 Personnel Data Warehouse 的人员数据
- 来自 AI Use Case Registry 的 AI/ML 项目数据
- 从团队简历中提取的技能
对于 AI/ML 项目数据,计算项目描述之间的余弦相似度,以创建项目之间的关系,并将相似度作为属性。
此外,使用 Ollama 处理简历数据,以提取技能,而无需手动标记的数据集。 然后将这些技能作为节点链接到图中的员工。
Talking Point 4: Graph Schema and Modeling
NASA 构建了一个带有标签的属性图,其节点包括:
- Employees
- Position Title
- Occupation Series
- Pay Grades
- Organizations (MISO - Mission Support Enterprise Organization)
- Centers
- Projects (带有相关描述,设置为 Node 属性(非结构化文本))
- Level of Education
- University attended
- Instructional Program Major
- Extracted Skills
所有节点都被标记为 "Entity",以支持向量索引和 GraphRAG(图检索增强生成)。
Talking Point 5: Live People Graph Demo Highlights
在社区讨论中,该团队展示了在示例数据集(带有匿名 PII)上运行的真实 Cypher 查询,以回答 NASA 的以下类型的问题:
- Subject Matter Experts Finder Question:旨在识别在特定领域或任务关键能力方面具有专业知识的员工。
- Leadership Report-Out Descriptive Questions:旨在通过分析劳动力构成、能力分布和组织动态,为领导层提供高级指标。
- Project Overlap Questions:旨在检测基于相似度分数的近乎重复的项目。
他们还预览了一个基于 RAG 的聊天机器人,允许用户使用自然语言查询图。
想亲眼看看这些实时查询的运行情况吗? 立即观看社区讨论中的完整演示!
Talking Point 6: LLM-Powered RAG Pipeline
基于 RAG 的聊天机器人由 NASA 构建在图之上。 以下是它的工作原理概述:
- LLM 从 问题中提取关键信息。
- Modified Pivot Search 在每个关键信息片段上分别执行,而不是一起执行 - 返回多个相关节点。
- 还对这些多个相关节点进行了 Relevance expansion:
- 从每个相关节点开始,并进行所需数量的跳跃
- 返回开始节点、结束节点以及它们之间的关系信息
- 这些被称为“context triplets”
- GraphRAG 向 Ollama 提供这些 “context triplets” 和原始问题,以 生成针对用户查询的上下文感知响应。
Embedding 直接存储在 Memgraph 中,并使用余弦相似度进行索引。 该系统仍在完善中,计划测试重新排序和改进 embedding 模型。
Talking Point 7: Limitations and What’s Next
该项目每天都在不断发展和改进。 当前图有大约 27K 个节点和 230K 条边,并计划进行大幅扩展。 未来的工作包括:
- 提高数据质量和消除歧义(例如,将 "JS" 映射到 "JavaScript")
- 自动化数据管道
- 扩展图以包括员工的学习目标、首选项目类型和技能分类
- 通过模型上下文协议 (MCP) 提高 Cypher 生成和 RAG 准确性
NASA 的最终目标是将人员图谱扩展到超过 500,000 个节点和数百万条边。
Q &A
我们整理了来自社区讨论问答环节的问题和答案。
请注意,为了简洁起见,我们略作了释义。 有关完整详细信息,请观看整个视频。
-
您是如何将非结构化文本转换为关键字分类的?
- Madison: 在 LLM 之前,该团队使用带有 spaCy 模型的自定义命名实体识别,这需要手动标记的训练数据集,并且劳动强度很大。 LLM 使信息提取变得更加可行。
-
您是在开始之前定义了图关系(模式),还是在进行过程中定义的?
- Madison: 我们从对人员如何与其属性和工作相关联的直观理解开始。 David: 知识图谱具有灵活性; 您不需要预先制定完整的模式。 我们从已知关系开始,并在探索数据时添加了潜在关系。 项目相似性等关系是动态添加的。 Madison: 是的,相似性关系是在添加初始数据后,根据对现有数据的分析形成的。
-
是什么让您选择 Memgraph 而不是 Neo4j 等其他设置?
- David: 我从事这项工作已经超过 10 年了,并且从那时起我就一直在关注各种不同的图数据库。 我在 2015 年使用 Neo4j 时,它还是一个命令行界面。 为了确保每个人都明白,我更喜欢带有标签的属性图,而不是 RDF。 因此,这自然而然地让我更倾向于 Neo4j 作为当时的主要图数据库。 最重要的是,对于 Neo4j 来说,成本非常高。 我将非常坦率地说,我也告诉了 Neo 团队同样的事情。 我无法在当前的环境中负担得起。 几年前,我到处寻找,然后发现了 Memgraph。 Memgraph 使用 Cypher,就像 Neo4j 一样。 Memgraph 在 Python 中执行操作,而 Neo4j 仅在 Java 中执行操作。 因此,有很多好处在于,我知道我可以利用相同的工具,而无需重新学习大量知识,因为我们在 Neo4j 中已经做了很多工作。 然后 Memgraph 向我展示了成本。 这让我有时间能够做到这一点。 它完成了我们在标签属性图中所做的一切。 因此,我们能够转向一种更具成本效益的工具,而且我们不必经历巨大的学习曲线,因为我们已经在使用我们已经学到的相同功能。 此外,我的团队一半是 Python,一半是 R,因此 Python 方面可以轻松地进入并复制我们需要做的事情。 因此,更多的是关于过渡的便利性和成本。
-
您是如何创建与余弦相似度和其他相似度相关的关系的?
- Madison: 我们迭代了项目节点,比较了其描述的 embedding,并根据余弦相似度阈值创建了项目之间的关系。
-
您提到使用模型来生成 embedding。 您是否将这些存储在 Memgraph 中以进行相似性搜索?
- Madison: 是的,embedding 作为节点属性存储在 Memgraph 中,我们使用这些属性上的 向量搜索 索引来查找相似节点并促进模糊搜索。
-
您是否还在关系上存储数据属性,例如相关技能的熟练程度或经验年限? 您是否在遍历中使用它?
- Madison: 我们有一些关系属性,但需要更多实验来量化经验之类的事情。 虽然 RAG 考虑了关系属性,但它们还不是主要重点,但我们看到了它们的潜力。
-
您如何处理数据重复和歧义,例如来自不同来源(如简历)的技能名称(如“JavaScript”和“JS”)的变体?
- David: LLM 通过理解 “JavaScript” 和 “JS” 等变体来提供帮助。 我们还可以使用 RAG 环境中的提示工程和上下文感知来指导 LLM 将同义词映射到一致的表示形式。
- Madison: 虽然 LLM 会提供帮助,但我们在评估提取的技能时,还会将语义相似性纳入到准确性指标中,以考虑这些变体。
-
当您将所有数据加载到 Memgraph 时,您预计在节点和关系方面会达到什么规模? 数据量是多少?
- David: 我们当前的数据库大约有 27,000 个节点和 230,000 条边,其中包括大约 18,000 个员工节点,但这并不详尽。 Madison: 我们希望随着添加更多数据而扩大规模。 David: 以前的一个类似项目轻松处理了大约 500,000 个节点和 150 万到 200 万个关系,这仍然被认为是小图规模。
Further Reading
- Blog post: Building GenAI Applications with Memgraph: Easy Integration with GPT and Llama
- Vector Search Tutorial: Building a Movie Similarity Search Engine with Vector Search in Memgraph
- Hands-On GraphRAG Notebook: Build Your Own RAG-Powered Knowledge Graph
- Webinar Recording: Optimizing Insulin Management: The Role of GraphRAG in Patient Care
- Webinar Recording: Cedars-Sinai: Using Graph Databases for Knowledge-Aware Automated Machine Learning
- Webinar recording: Microchip Optimizes LLM Chatbot with RAG and a Knowledge Graph
- Whitepaper: Enhancing LLM Chatbot Efficiency with GraphRAG (GenAI/LLMs)
Memgraph Academy
如果您是 GraphRAG 新手,我们建议您查看我们主题专家提供的几个简短易懂的课程。 免费。 从以下开始:
在 Discord 上加入我们!
查找其他使用 Memgraph 实时执行图分析的开发人员。