深入探索 DOS 游戏如何通过让游戏无法通关进行防盗版
揭秘《The Games: Winter Challenge》的防盗版机制
最近,我重新发现了老游戏《The Games: Winter Challenge》,这是一款由 MindSpan 开发、Accolade 于 1991 年为 DOS 和 Sega Genesis 平台发行的冬季奥运会体育游戏。我小时候玩的是 DOS 版本,所以当我不经意间想起它时,怀旧和好奇心驱使我再次深入挖掘它。

如今我已成为一名计算机科学家,我更感兴趣的是它在底层是如何运作的,而不是重新玩它(尽管再次听到那标志性的音乐也很有趣)。小时候,我花了无数时间玩跳台滑雪项目,试图达到梦寐以求的 100 米大关,但从未成功。我决心不仅要弄清楚是否有可能实现,还要找出理论上的最佳成绩是多少。幸运的是,游戏具有重播系统,可以让你保存和重看过去的尝试,这为创建 TAS(工具辅助速通)和制作完美重播文件,并将游戏推向极限提供了绝佳的机会。
我最初的攻击计划很简单:找到游戏副本,在 Ghidra 中打开它,反汇编以找出跳台滑雪的工作原理,并根据发现的机制进行优化。事实证明,这个计划的每一步都比预期的要复杂得多,并且在过程中产生了更多需要解答的问题,从而开启了一个探索 90 年代早期视频游戏开发复杂性的兔子洞。本文将带你一起踏上这段发现之旅,了解基于 DOS 的程序是如何工作的,视频游戏开发者是如何绕过硬件限制的,早期防盗版是如何工作的,以及 GOG 如何(截至 2025 年 3 月)向你出售一个损坏的游戏版本。
盘点 - 版本混乱和防盗版绕过
该游戏有多个版本,包括 1991 年的原始版本,1992 年(欧洲)和 1996 年(美国)与其续作《Summer Challenge》的两个捆绑版本,以及 2020 年 GOG 基于 DOSBox 模拟器的捆绑版本。虽然我童年时代的原始软盘可能埋在某个地方,但由于缺乏软盘驱动器来读取它们,如今它们的用处有限,所以我上网搜索了这款游戏。多亏了 Internet Archive 托管的原始媒体的各种版本,以及从 GOG 购买它,获取这些不同的版本并不太困难。
原始游戏使用密码轮进行防盗版。密码轮是当时一种典型的防盗版方法:它们是一组物理磁盘,彼此滑动,你与包含游戏的软盘一起获得它们。在启动时,游戏会要求你将它们旋转到特定配置,从而显示你需要输入到游戏中才能使其工作的代码。对于那些不像我一样老,以前从未见过密码轮的人,可以使用此游戏的 交互式在线版本。
正如预期的那样,1991 年的原始版本会在你尝试玩任何项目时要求提供此代码,如果你连续两次回答不正确,则会将你踢出游戏。
附带调查 1: 密码轮检查是如何实现的?

GOG 版本不会要求你提供代码,并且让你无需代码即可进行游戏,因此他们可能已删除了防盗版功能,而不是分发密码轮。非常有趣的是,GOG 上对该游戏的讨论中,有很多人抱怨该游戏“破解不当”,因此无法正常工作。对某些行为的描述,例如你无法将跳台滑雪的着陆距离超过一定距离,或者你总是在速度滑冰的最后一圈中撞车,实际上与我小时候玩游戏的记忆产生了共鸣,这意味着我们当时也有一个破解不佳的版本,或者这与防盗版无关,而游戏只是有漏洞。
附带调查 2: 是否有影响游戏玩法的隐藏防盗版措施?
1996 年美国版实际上附带了一个单独的破解程序,可能是官方认可的:在主 WINTER.EXE 旁边,它有一个 WINTER.COM,大小仅为 879 字节,该文件在执行时会从游戏中删除密码轮检查,否则游戏仍会要求提供密码轮。
但是版本混乱并未就此结束。在搜索不同版本时,我还发现了该游戏的其他版本,通常以在浏览器中加载到 DOSBox 中的在线可玩镜像的形式存在。这些都不需要密码轮,虽然有些基于 1996 年美国版,但另一些则使用了完全不同的破解程序,由 90 年代初期的不同发布小组创建。
为了完成这种混乱局面,原始游戏实际上提供了一个选项,可以将游戏安装到磁盘上,而不是从软盘上玩,其中包括其自己的一系列谜团。安装的工作方式不像你可能期望的那样,只是将文件从软盘复制到磁盘上。相反,它实际上每次都会创建一个全新的 WINTER.EXE 可执行文件。在安装过程中,你可以选择不同的选项,包括要支持的图形模式,以及“快速加载”模式,根据手册,该模式以占用额外的硬盘空间为代价,使游戏的加载速度更快,并且每个选项组合都会为你创建一个不同的可执行文件。
附带调查 3: 这些不同版本的可执行文件是如何创建的,它们有何不同?
因此,盘点并比较所有不同的已获取版本,存在很多不同的二进制文件:
- 游戏的原始软盘版本
- 安装到硬盘时游戏的六个不同版本,用于“快速加载”和 EGA 和 VGA 图形模式中的一个或两个的每个组合
- 游戏的 GOG 版本,该版本基于已安装的 VGA+EGA 快速加载版本,并修改了单个字节
- 来源不明的已破解二进制文件,该文件基于已安装的 VGA 快速加载版本,并修改了单个字节
此外,还有三个不同的独立破解程序:
- 官方
WINTER.COM破解程序(879 字节),该破解程序与未经修改的软盘版本一起在 1996 年美国版中提供 - 发布小组“The Humble Guys”于 1991 年 10 月 17 日(在游戏发布后几天内)发布的
WG.COM破解程序(366 字节) - 发布小组“Razor1911”于 1991 年 10 月 17 日(与另一个破解程序同一天!)发布的
WINTER.COM破解程序(291 字节)
附带调查 4: 单个破解程序如何工作,它们是否使用不同的机制?
打开二进制文件 - 混淆和内存限制
因此,为了从某个地方开始,我在 Ghidra 中加载了软盘版本,并且立即感到不知所措。它只设法分析了初始代码的一小部分,其中大部分代码仍然是二进制 blob。在 IDA 中打开同一文件显示了几乎相同的画面,但是 IDA 还提供了随附的警告:它认为该二进制文件可能已打包,并且在代码末尾之后有很多未使用的字节。我认为该二进制文件必须以某种方式打包或混淆,并且初始代码的一小部分是解压缩其余二进制文件的例程。
因此,我开始逆向工程解压缩例程,并在二进制文件中发现了一个可疑字符串,该字符串嵌套在汇编代码之间:FAB。
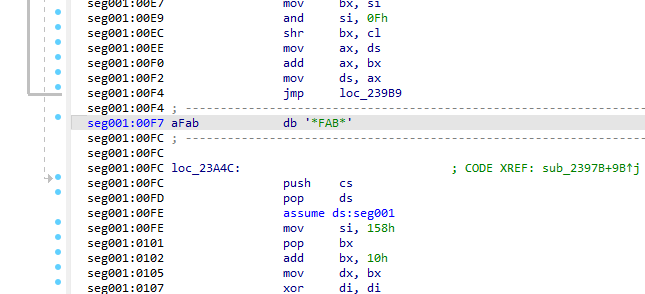
事实证明,“FAB”代表 Fabrice Bellard,除了是 FFmpeg 和 QEMU 等广泛使用的程序的原始开发者之外,还是可执行文件压缩实用程序 LZEXE 的创建者,该实用程序于 1990 年开发。幸运的是,LZEXE 的内部工作原理已得到广泛记录和理解。我不会在这里详细介绍压缩的工作原理,如果你想深入研究,Scott Smitelli 和 Sam Russell 撰写了很棒的现有文章。我们只想解压缩二进制文件以获得好的内容,并且有很多现有的解压缩实用程序可用,包括来自同一时代的 Mitugu Kurizono 的 UNLZEXE。打包和解压缩是其自身的军备竞赛缩影,具有用于防止解压缩的保护器,以及更复杂的解压缩器来执行解压缩,但是幸运的是,此游戏没有采用其他解压缩保护。
生成的解压缩二进制文件立即带来了两个惊喜:首先,它的大小仅为 168kB,比原始可执行文件小得多,尽管提取可能会使其大小增长,其次,解压缩的结果在所有不同游戏版本中都是相同的。这为我们提供了有关游戏结构的一个提示:它包含一个业务逻辑块,这就是我们已经解压缩并在版本之间相同的,然后它包含一些资源,例如精灵和声音,这些资源已包含在可执行文件中,并在运行时从中加载。此假设得到了以下事实的支持:只要将提取的二进制文件放置在原始 WINTER.EXE 二进制文件旁边以从中加载资源,它实际上仍然可以正常工作。
但是对于二进制文件的两个已破解版本而言,这也有些令人惊讶,我本以为那些破解版本会包含修改后的业务逻辑,以便于跳过密码轮检查。在反汇编器中打开新的提取的二进制文件后,该谜团的答案很快变得显而易见。四处查找后,我们发现对 int 3fh 的可疑中断调用。
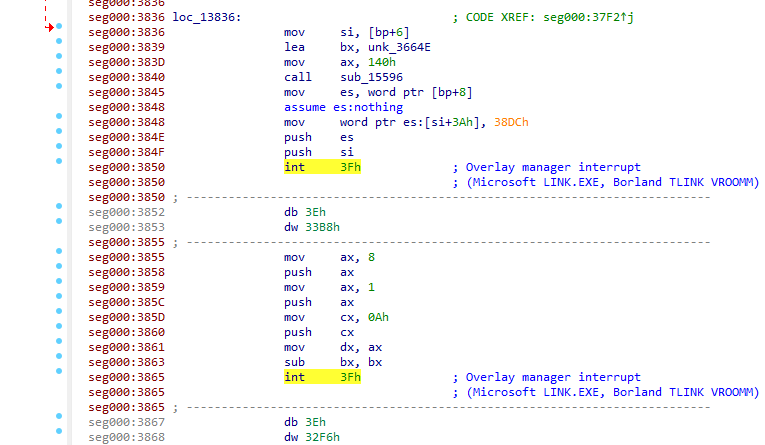
侧边栏:中断
中断 是 DOS 程序过去与操作系统进行通信的主要方式,类似于今天的 syscall。每当程序想要与自身代码之外的任何事物交互时,它都会调用中断并要求 DOS 为其执行该任务,从而暂时将控制权交还给操作系统,并在完成后恢复。从将文本打印到屏幕,从磁盘读取和写入文件到分配堆内存,都通过 DOS 提供的主要中断
int 21h完成。其他中断存在,例如用于鼠标交互的int 33h,但值得注意的是,int 3fh不是 DOS 提供的中断之一。在底层,中断的路由由 中断向量表 处理,该表包含每个中断的地址,该地址是从调用中断时执行的例程的地址。程序可以修改此表(使用中断)以添加其自己的自定义中断,并且int 3fh可能会以这种方式使用用户定义的。
IDA 为这些调用提供了一个有用的注释,即此中断通常用于调用“Overlay manager”。
侧边栏:覆盖
覆盖 是一种用于在运行时加载其他代码段的技术,其中多个此类段(称为覆盖)可以在内存中的同一位置换出。这在当时的程序中用于节省 RAM 使用量非常有用:DOS 仅允许程序使用最多 640kB 的内存(又名 Conventional memory),并且大型应用程序本身可能已经太大,无法将其所有代码都放入该限制中,甚至没有考虑到任何数据。覆盖用于规避此限制:通过将程序代码分解为多个覆盖,程序只需要将当前操作所需的任何覆盖加载到内存中。其他覆盖在需要时从磁盘加载,替换先前的覆盖,从而使程序具有复杂的功能,同时占用较小的内存。加载和管理覆盖是覆盖管理器的责任,覆盖管理器是一种库,用于跟踪何时需要哪些覆盖,并相应地加载和卸载它们。
事实证明,该游戏是用 C 编写的,并使用 Microsoft C 编译器版本 6 编译的,如二进制文件中嵌入的字符串 MS Run-Time Library - Copyright (c) 1990, Microsoft Corp 所示。查阅编译器的手册,该编译器的链接器确实原生支持覆盖,并且默认情况下会将自己的覆盖管理器安装为 int 3fh,因此这是我对如何创建此结构的第一个怀疑。
总而言之,这不是一个好消息。这意味着解压缩的二进制文件实际上并不是存在的所有业务逻辑,并且还有更多代码段,可能位于与可执行文件一起打包的资源中。反汇编程序不了解这些覆盖,无法检测它们或自动反汇编它们,因此理解业务逻辑的工作将比计划的手动得多。为了进一步发展,我们需要找到并提取所有这些覆盖,以获得游戏代码的完整画面。
通过找到在程序开始时安装中断 3fh 的位置,我们可以标识覆盖管理器例程,该例程在每次需要覆盖时都会被调用。
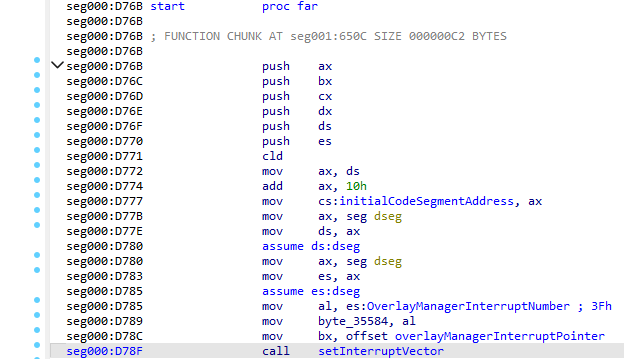
根据有关 Microsoft 覆盖管理器如何工作的文档,每次中断调用之后都有 3 个字节,一个字节用于所需覆盖的索引号,两个字节用于该覆盖内的 16 位地址。然后调用中断,就像函数调用一样:加载覆盖,调用给定地址的函数,然后在中断调用之后直接返回控制流。实际上,中断是函数调用的字面替换:链接器会将通常需要 5 个字节的远调用指令(1 字节操作码,2 字节地址偏移量,2 字节地址段)替换为中断的 5 个字节(2 字节操作码,1 字节覆盖索引,2 字节地址偏移量)。
但是,好消息到此为止。根据文档,每个覆盖都应附加到主程序,包括其自己的 MZ header,但这并不是我们在二进制文件中发现的内容。更糟糕的是,当使用 DOSBox 的调试器单步执行中断调用时,在二进制文件中找不到已加载的代码。此外,与典型的覆盖不同,它们实际上并不占用内存中的相同空间,而是为每个覆盖动态分配新内存,并在使用后释放分配的内存。这很有用,因为它允许同时加载多个覆盖,但这也意味着此游戏实际上并没有使用 Microsoft C 中的覆盖机制,而是使用了看起来像是定制的覆盖管理实现。
提取资源
静态地逆向工程覆盖管理器例程原来是一项非常耗时的努力,但是幸运的是,仍然有一些提示可以帮助我们采取一些捷径。DOS 模拟器 DOSBox-X 是 DOSBox 的一个分支,具有其他有用的调试功能,包括记录所有文件 IO 和所有 int 21h 中断。在游戏启动时观察这些中断,可以发现游戏正在二进制文件中搜索特定位置,这些位置恰好位于主程序的字节之后,然后读取许多 22 字节的块。
...
4201235 DEBUG FILES:Seeking to 82944 bytes from position type (0) in WINTER.EXE
4201290 DEBUG FILES:Reading 2 bytes from WINTER.EXE
4201353 DEBUG FILES:Seeking to 82495 bytes from position type (0) in WINTER.EXE
4201408 DEBUG FILES:Reading 2 bytes from WINTER.EXE
4201475 DEBUG FILES:Seeking to 82497 bytes from position type (0) in WINTER.EXE
4201530 DEBUG FILES:Reading 2 bytes from WINTER.EXE
4204681 DEBUG FILES:Seeking to 82499 bytes from position type (0) in WINTER.EXE
4204735 DEBUG FILES:Reading 22 bytes from WINTER.EXE
4204855 DEBUG FILES:Reading 22 bytes from WINTER.EXE
4204975 DEBUG FILES:Reading 22 bytes from WINTER.EXE
4205095 DEBUG FILES:Reading 22 bytes from WINTER.EXE
4205215 DEBUG FILES:Reading 22 bytes from WINTER.EXE
4205335 DEBUG FILES:Reading 22 bytes from WINTER.EXE
4205455 DEBUG FILES:Reading 22 bytes from WINTER.EXE
...
这些很可能是资源的开始,并且在检查该位置的二进制文件时,我们发现该节以拼出 MB 的两个字节开头,类似于可执行文件本身以 MZ 魔数开头的方式。在反汇编中查找此魔数会将我们直接带到解析嵌入资源结构的例程。
seg000:6D83 sub ax, ax ; sets ax to 0
seg000:6D85 push ax ; push argument 3 for fseek: 0 = seek relative to start of file
seg000:6D86 push winter_exe_overlay_start_index_hi ; push argument 2 for fseek: the offset to seek to
seg000:6D8A push winter_exe_overlay_start_index_lo ; it's a 4 byte value and pushed in two halves
seg000:6D8E push winter_exe_file_handle ; push argument 1 for fseek: the file handle of WINTER.EXE which was opened earlier
seg000:6D92 call fseek ; seek to the start of the resource section in the WINTER.EXE file
seg000:6D97 add sp, 8 ; clear the arguments for fseek from the stack again
seg000:6D9A push cs ; the function read_2_bytes_from_winter_exe is a far function, but we're making in near call, so we need to push the segment onto the stack manually
seg000:6D9B call near ptr read_2_bytes_from_winter_exe ; read the next two bytes from the file
seg000:6D9E cmp ax, 424Dh ; check if if contains the "MB" magic number
seg000:6DA1 jz short mb_marker_found ; jump if found
seg000:6DA3 push winter_exe_file_handle ; if not found, close file and return
seg000:6DA7 call fclose
seg000:6DAC add sp, 2
seg000:6DAF mov winter_exe_file_handle, 0
seg000:6DB5 jmp short done
seg000:6DB5 ; ---------------------------------------------------------------------------
seg000:6DB8 mb_marker_found:
seg000:6DB8 sub ax, ax ; sets ax to 0
seg000:6DBA push ax ; push argument 3 for fseek: 0 = seek relative to start of file
seg000:6DBB mov ax, winter_exe_overlay_start_index_lo ; load overlay start index and add 2 to it
seg000:6DBE mov dx, winter_exe_overlay_start_index_hi
seg000:6DC2 add ax, 2
seg000:6DC5 adc dx, 0
seg000:6DC8 push dx ; push argument 2 for fseek: the offset to seek to
seg000:6DC9 push ax
seg000:6DCA push winter_exe_file_handle ; push argument 1 for fseek: the file handle of WINTER.EXE which was opened earlier
seg000:6DCE call fseek ; seek to the next two bytes after the MB marker
seg000:6DD3 add sp, 8 ; clear the arguments for fseek from the stack again
seg000:6DD6 push cs
seg000:6DD7 call near ptr read_2_bytes_from_winter_exe ; read the next two bytes from the file
seg000:6DDA mov resource_chunk_count, ax ; next two bytes indicate the number of resources
seg000:6DDD done:
....
侧边栏:16 位架构和段
该程序以及当时的所有 DOS 程序都是为 16 位架构构建的,而今天的计算机使用的是 64 位架构。这意味着 CPU 中的所有寄存器只能容纳 16 位值,包括任何指针。由于 16 位寄存器只能具有 2^16 = 65536 个不同的值,因此它只能寻址 64kB 的内存。即使在当时,这也有点太少了,因此为了能够寻址更多的内存,指针通常由两部分组成,即段和偏移量。 段 是内存块,最大大小为 64kB,通常被分配不同的角色:通常有一个或多个代码段,其中包含程序代码,一个数据段,其中包含程序存储的任何数据的工作内存,以及一个堆栈段,其中包含放置在堆栈上的值。这些段可以被视为内存的独立部分,并且要与来自另一个段的内容进行交互,你需要一个远指针,该指针由段和该段中的偏移量组成,而要引用段中的内容,则使用仅使用偏移量的近指针就足够了。 在底层,内存仍然是一个线性块,并且远指针的最终内存地址只是
segment * 16 + offset。这意味着段在技术上可以重叠,不同的段-偏移量对指向相同的物理地址,但是按照惯例,选择将它们设置为不同的块。
所有资源都以一个简单的标头结构制成表格,每个条目 22 字节。每个条目包含两个 4 字节的数字,指示数据的长度和它们在文件中的位置偏移量。剩余的字节包含一个以 0 结尾的字符串,该字符串拼出资源的名称(0 终止符之后的任何字节都是垃圾)。但是,此名称通过将 0x60 添加到所有字节进行混淆,因此它们不会显示在二进制文件的任何字符串分析中。通过解密名称,我们可以了解到这些额外的二进制 blob 包含图像、网格、音乐和 SFX 文件等资产,以及扩展名为 COD 和 REL 的文件对形式的代码覆盖。
4D 42 ; "MB" = magic number
F2 00 ; 242 = number of resources
4A 5C 00 00 10 57 01 00 B4 A9 B4 AC A5 8E AD B3 A8 00 (81 9F A2 01) ; Resource TITLE.MSH start 15710 end 1b35a length 5c4a
26 24 00 00 5A B3 01 00 B4 A9 B4 AC A5 8E AD A7 B3 00 (81 9F A2 01) ; Resource TITLE.MGS start 1b35a end 1d780 length 2426
9E D4 00 00 80 D7 01 00 B4 A9 B4 AC A5 8E AD B0 A9 00 (81 9F A2 01) ; Resource TITLE.MPI start 1d780 end 2ac1e length d49e
00 03 00 00 1E AC 02 00 B4 A9 B4 AC A5 B0 A1 AC 8E A2 A9 AE 00 (01) ; Resource TITLEPAL.BIN start 2ac1e end 2af1e length 300
2E 4A 00 00 1E AF 02 00 B4 A9 B4 AC A5 92 8E AD B3 A8 00 (AE 00 01) ; Resource TITLE2.MSH start 2af1e end 2f94c length 4a2e
56 1B 00 00 4C F9 02 00 B4 A9 B4 AC A5 92 8E AD A7 B3 00 (AE 00 01) ; Resource TITLE2.MGS start 2f94c end 314a2 length 1b56
44 CC 00 00 A2 14 03 00 A2 A1 A3 AB A4 B2 AF B0 8E AD B0 A9 00 (01) ; Resource BACKDROP.MPI start 314a2 end 3e0e6 length cc44
92 65 00 00 E6 E0 03 00 A9 B3 8E AD B3 A8 00 (B0 8E AD B0 A9 00 01) ; Resource IS.MSH start 3e0e6 end 44678 length 6592
CC 18 00 00 78 46 04 00 A9 B3 8E AD A7 B3 00 (B0 8E AD B0 A9 00 01) ; Resource IS.MGS start 44678 end 45f44 length 18cc
D8 88 00 00 44 5F 04 00 B4 A1 BF AF B0 A5 AE 8E AD A7 B3 00 (00 01) ; Resource TA_OPEN.MGS start 45f44 end 4e81c length 88d8
D8 73 00 00 1C E8 04 00 B4 A1 BF AF B0 A5 AE 8E AD B3 A8 00 (00 01) ; Resource TA_OPEN.MSH start 4e81c end 55bf4 length 73d8
00 07 00 00 F4 5B 05 00 A5 B6 B4 A1 B7 A1 B2 A4 8E AD A7 B3 00 (01) ; Resource EVTAWARD.MGS start 55bf4 end 562f4 length 700
22 24 00 00 F4 62 05 00 A5 B6 B4 A1 B7 A1 B2 A4 8E AD B3 A8 00 (01) ; Resource EVTAWARD.MSH start 562f4 end 58716 length 2422
CC 56 00 00 16 87 05 00 A9 B3 A1 B5 B8 8E AD B3 A8 00 (B3 A8 00 01) ; Resource ISAUX.MSH start 58716 end 5dde2 length 56cc
32 25 00 00 E2 DD 05 00 A9 B3 A1 B5 B8 8E AD A7 B3 00 (B3 A8 00 01) ; Resource ISAUX.MGS start 5dde2 end 60314 length 2532
...
64 27 00 00 96 AF 12 00 AF B6 AC 91 8E A3 AF A4 00 (B3 00 AE 00 01) ; Resource OVL1.COD start 12af96 end 12d6fa length 2764
6E 03 00 00 FA D6 12 00 AF B6 AC 91 8E B2 A5 AC 00 (B3 00 AE 00 01) ; Resource OVL1.REL start 12d6fa end 12da68 length 36e
35 02 00 00 68 DA 12 00 AF B6 AC 91 95 8E B0 A3 AF 00 (00 AE 00 01) ; Resource OVL15.PCO start 12da68 end 12dc9d length 235
11 00 00 00 9E DC 12 00 AF B6 AC 91 95 8E B0 B2 A5 00 (00 AE 00 01) ; Resource OVL15.PRE start 12dc9e end 12dcaf length 11
...
一个有趣的观察模式是,文件名之后的垃圾数据是来自先前名称的剩余内容,这表明在写入条目时,它对所有名称都使用了相同的缓冲区。
仅从名称来看,我们可以假设 COD 文件包含实际的机器代码,而 REL 文件包含一些重定位数据。
侧边栏:重定位
重定位 是一个概念,它使代码能够实现位置独立性:当程序加载到内存中时,它可能不会每次都加载到相同的地址。但是,程序的部分通过地址引用其他部分(例如,函数调用),并且为了使这些部分能够继续工作,无论在内存中的实际位置如何,都需要修改它们。为了实现这一点,所有地址都被写入到二进制文件中,就好像该程序位于内存地址 0 一样,并且与段值相对应的所有位置都放入一个称为重定位表的长列表中。对于主程序,这由 DOS 处理:可执行文件的 MZ 标头包含一个重定位表,该表包含代码中需要更新的地址。在将程序复制到内存中的某个偏移量之后,DOS 会遍历此列表,并将所选偏移量添加到其包含的每个地址,从而使所有远指针再次指向正确的位置。 加载这些代码覆盖时,也会存在相同的重定位问题,并且
REL文件可能包含促进其正确重定位所需的必要信息。
在查看已安装游戏的不同版本时,我们可以看到它们捆绑在一起的资源确实不同。这最终解决了我们的第一个附带谜团:
附带调查 3 已完成! 根据所选的图形模式,会包含更多或更少的资源,并且每个资源都可以采用两种变体,即未压缩版本(例如
TITLE.MGS)和压缩版本(例如TITLE.PMG),通过将P前置到其扩展名来指示。安装的“快速加载”版本捆绑了未压缩的资源,而软盘版本包含打包版本,从而在运行时加载资产的速度与它们在磁盘上占用的空间大小之间进行权衡。
现在很难想象,但是硬盘空间在当时是一个严重的问题,并且未压缩的资产占用的额外千字节可能很重要。
但是,即使在快速加载版本中,似乎并非所有资产都实际上未压缩。具体来说,即使在那里,一些代码覆盖也保持打包状态,大概是为了即使在安装期间选择了快速加载,也可以使它们保持混淆状态。但是,通过反汇编,我们已经知道现在在何处加载资源,因此使用带有适当断点的调试器,我们也可以轻松地从程序内存中转储这些资源的未压缩版本,而无需了解资源的压缩实际是如何工作的。(如果你仍然好奇压缩的工作原理,我最终确实对其进行了反汇编,发现它是 DEFLATE 压缩的一种非常复杂的自定义变体。你可以在 此处 找到它的 JS 重新实现。)
方便的是,游戏还为我们提供了一种相当简单的方法来检查我们是否正确提取了所有资源。事实证明,游戏对于尝试从中加载资源的位置更加灵活,不仅检查二进制文件中的嵌入式资源,还检查同名的各个文件,在根文件夹或名为“ART”的子文件夹中。只要可以在这些位置中的任何一个找到资源,它就会使用它。因此,通过编写一个程序将所有这些资源提取到它们自己的文件中,并将它们放置在 ART 子文件夹中,然后手动修改二进制文件以删除所有嵌入式资源,我们可以使游戏改为使用我们提取的资产。这样做并运行游戏,它确实仍然可以工作,从而确认我们提取的资源是准确的,并且我们没有丢失来自二进制文件的任何其他内容。
合并所有覆盖
因此,现在我们终于拥有了组成游戏业务逻辑的所有代码,但是它们分布在 17 个文件中,即主可执行文件和 16 个覆盖中,这使得它们非常难以使用。我们想要的是一个包含所有代码的单个二进制文件,从而使其更易于分析。为了实现这一点,我们可以尝试将覆盖嵌入到二进制文件中,本质上是撤消覆盖并将它们全部并排一次性加载。甚至更多,这样做可以使我们撤消将函数调用替换为覆盖中断的操作,从而完全消除 int 3fh,并使常见反汇编程序的自动分析更加准确。如今可用 RAM 显然不再是一个问题,但是我们仍然需要保持在 DOS 施加的 640kB 限制内。幸运的是,所有覆盖加起来的大小仅约为 100kB,因此与 168kB 的主二进制文件一起,它仍然应该有足够的空间来根据需要加载资产,特别是由于不再需要保留堆空间来加载覆盖。
不幸的是,实际上融合二进制文件并不那么容易。我的第一个想法只是将所有覆盖连接到内存中的主二进制文件上,并烘焙重定位以使它们全部连接,可悲的是这不会起作用,因为堆栈以及动态内存分配的工作方式。主二进制文件以一种所有代码段都放在最前面,然后是数据段,其中包含程序使用的所有工作内存,最后是堆栈段的方式进行