Beyond Elk: Lightweight and Scalable Cloud-Native Log Monitoring
超越 ELK:轻量级和可扩展的云原生日志监控
本文探讨了在现代日志存储场景中,ELK 技术栈日益增长的局限性,并介绍了 GreptimeDB 作为下一代日志数据库,在架构和用户体验方面的优势。通过将 Vector 与 GreptimeDB 结合,我们展示了一个完整的管道——从日志收集和存储到解析和查询。
![![]() Yisong ShuiSoftware Engineer
Yisong ShuiSoftware Engineer

ELK 概览
在选择有限的年代,Elasticsearch 因其出色的全文搜索能力而成为日志存储和查询的首选解决方案。 后来,elastic.co 围绕 Elasticsearch 构建了 ELK 生态系统,提供了一个完整的收集、存储和分析生态系统。 之后添加的 beats 组件进一步改善了数据收集方面的不足,使数据收集更加灵活和轻量级。因此,ELK 已成为事实上的日志收集解决方案。
进入 2025 年,各种新的编程方法和部署范例正在被广泛采用。 与更现代的解决方案相比,Elasticsearch 相对较旧的技术和架构设计逐渐暴露出一些缺点:
1. 存储成本飙升:日志越多,成本越高
随着软件系统复杂性的增加,应用程序产生的日志量呈指数级增长。 为了排除根本原因,我们通常需要尽可能长时间地保留所有日志。 然而,Elasticsearch 在每行日志上构建索引以加速全文搜索,这意味着巨大的存储开销。
我们的测试发现,摄取 10GB 的日志数据导致 Elasticsearch 生成超过 10GB 的存储文件。 日志数据的长期存储大小已使存储成本成为替换 ELK 的主要原因。
2. 存储和计算耦合,造成严重的资源浪费
作为一个在云计算之前诞生的系统,Elasticsearch 自然使用本地磁盘存储并具有内置的数据复制机制。 结合上述大量数据,这意味着对高性能 SSD 的依赖性越来越高。
更糟糕的是,存储和计算资源是绑定在一起的:如果我们想扩展 CPU 以处理高并发,我们也要扩展磁盘; 反之亦然。 结果是我们为不使用的资源付费。
3. 渴求资源且容易出现 OOM
Elasticsearch 在 JVM 上运行,对硬件资源(尤其是内存)非常渴求。 关于“OOM 被杀死”的讨论在各种论坛中很常见。 在生产环境中,Elasticsearch 通常需要非常高规格的机器才能运行。
比较多个日志数据库,我们发现在相同的写入请求压力下,Elasticsearch 的硬件资源消耗是最高的(假设它可以处理该卷而不崩溃)。
4. 维护复杂,对云原生不友好
Elasticsearch 也因其高维护难度而臭名昭著。 启动单个节点可能很容易,但是当我们面对升级、扩展、故障恢复和备份等场景时,每一步都可能令人望而却步。 尝试使用 Kubernetes 自动化 Elasticsearch 集群几乎是不可能的。
虽然 ELK 曾经很流行,并且仍然是许多用户日志监控解决方案的选择,但以上分析清楚地表明,ELK 在满足高摄取量和长期存储以进行实时日志监控和数据分析的需求方面正逐渐落后。
我们需要一种更现代、低成本且易于操作的日志监控解决方案。
GreptimeDB 作为日志监控存储解决方案
GreptimeDB 是一个云原生数据库,专为可观测性数据而设计,非常适合指标收集、日志存储和实时监控。 它的架构针对高频时间戳数据摄取和查询进行了优化,例如指标、日志和事件。
作为云原生数据库,GreptimeDB 采用存储计算分离架构。 原生于 Kubernetes,它能够实现无缝的弹性伸缩,使其成为云环境的理想选择。 独立的资源伸缩可确保成本效益和高需求工作负载下的稳定性能——只需最少的人工干预。
与传统解决方案相比,GreptimeDB 的存储计算分离架构和云原生设计使其成为非常适合日志存储的现代时序数据库。 以下是它在实际使用中的核心优势:
1. 高压缩率,节省存储意味着节省资金
GreptimeDB 是一个列式数据库,它使用诸如游程编码和字典编码之类的方法来实现高数据压缩。
我们的测试发现,在相同的日志摄取量下,GreptimeDB 的存储文件大小约为 Elasticsearch 的 1/10——存储更多,占用更少。
2. 计算存储分离,进一步降低存储成本
GreptimeDB 从一开始就采用存储计算分离架构,将数据存储在对象存储中,既经济高效又可靠:
- 在 AWS 等云服务中,对象存储的价格通常低于块存储的一半。
- 存储可靠性由底层对象存储保证,从而避免了数据库本身实现数据复制和备份的复杂性。
- 没有容量限制,也没有耦合资源。 无需在扩展 CPU 时扩展磁盘,从而避免了资源浪费。
3. 轻量级,硬件要求更低
GreptimeDB 用 Rust 编写,消耗更少的系统资源并稳定运行,即使在低端硬件上也是如此。
在我们的测试中,在相同的摄取量下,Elasticsearch 的 CPU 和内存使用率是 GreptimeDB 的几倍。 对于日志系统,这意味着更少的 OOM 和更好的稳定性。
4. 云原生操作
得益于其云原生架构,GreptimeDB 在 Kubernetes 上的部署和维护体验非常流畅和简单。 部署后,它会自动执行维护操作,例如滚动更新、关闭、重新启动、资源更改和负载平衡,从而确保在最少或没有技术人员干预的情况下稳定运行。 对于运维团队来说,这提供了真正的便利性和易用性。
5. 用于加速查询的多种索引机制
GreptimeDB 提供了各种索引类型以适应不同的查询需求:
- 对于低基数数据(例如
k8s_pod_ip),可以使用倒排索引来加速过滤操作。 - 对于高基数文本(例如
trace_id),可以设置跳跃索引以提高精确查询的效率。 - 对于模糊文本搜索,可以设置全文索引以支持灵活的搜索。
通过灵活地组合索引,可以显着提高查询速度,同时减少构建和存储索引的开销。 更多详细的索引介绍可以在此文档中找到。
使用 Vector + GreptimeDB 作为日志监控解决方案
接下来,我们将演示如何使用 Vector 和 GreptimeDB 快速构建日志收集和存储解决方案。
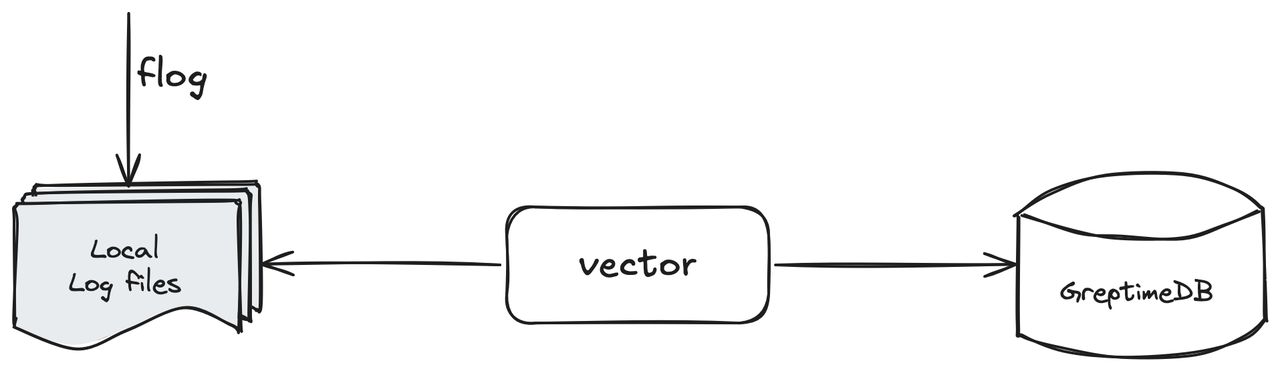 (图 1:Vector + GreptimeDB:日志监控解决方案)
(图 1:Vector + GreptimeDB:日志监控解决方案)
在这个简单的解决方案介绍中,我们使用:
- 使用 Flog 模拟本地日志文件;
- 使用 Vector 收集本地日志文件并将它们摄取到 GreptimeDB 实例中;
- 使用 GreptimeDB 的内置日志查看器或其他工具查看摄取的日志行。
模拟日志文件
我们使用 flog 来模拟生成一个持续输出的日志文件。 以下命令可以快速生成一个每秒写入一行日志的日志文件 log.txt:
在生产环境中,应用程序将使用日志记录库将日志打印到日志文件。 日志文件可能具有时间后缀,并且可以根据规则自动拆分和轮换。 对于一些流行的中间件,Vector 还集成了日志收集组件,例如 kubernetes logs:
执行 head -1 log.txt 以查看日志数据的样本:
shell
17.61.197.240 - nikolaus3107 [14/Apr/2025:21:11:44 +0800] "HEAD /envisioneer/efficient HTTP/1.0" 406 5946
部署 GreptimeDB 实例
我们需要部署一个 GreptimeDB 实例。 虽然本文使用独立实例作为示例,但数据摄取 API 对于独立实例和集群实例都是相同的。 在生产环境中,首选集群部署,可以在本文档中参考。
安装 GreptimeDB 相对简单,不同的安装方法可以在 此文档 中参考。 为了方便在各种环境中重现,我们使用 Docker 启动 GreptimeDB 数据库: shell
docker run -p 127.0.0.1:4000-4003:4000-4003 \
--name greptime --rm \
greptime/greptimedb:v0.14.0-nightly-20250407 standalone start \
--http-addr 0.0.0.0:4000 \
--rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
然后通过执行 curl 127.0.0.1:4000/health; 来验证数据库是否已成功启动; 我们还可以通过执行 mysql -h127.0.0.1 -P4002 来使用 MySQL 兼容的客户端连接到数据库进行确认。
使用 Vector 收集日志
我们需要先安装 Vector,可以参考此官方文档。 建议使用系统的 包管理器 进行安装以方便起见。 安装后,我们可以通过运行 vector --version 来验证安装。 在本文中,我们将通过在本地启动 Vector 来收集日志数据。 对于生产环境中的 Vector 部署,我们可以参考 此博客。
Vector 配置介绍
接下来,我们需要编写收集日志所需的 Vector 配置。 示例如下: toml
# config.toml
[sources.file_input]
type = "file"
include = [ "<path_to_log_dir>/log.txt" ]
data_dir = "<data_dir>"
[sinks.greptime_sink]
type = "greptimedb_logs"
inputs = [ "file_input" ]
compression = "gzip"
dbname = "public"
endpoint = "http://127.0.0.1:4000"
pipeline_name = "greptime_identity"
table = "app_log"
让我们仔细看看这个配置: toml
[sources.file_input]
type = "file"
include = [ "<path_to_log_dir>/log.txt" ]
data_dir = "<data_dir>"
ignore_checkpoints = true
这是 Vector 的 文件源。 Source 是 Vector 的数据输入,可以从各种适配的来源收集数据。 我们通过 type = "file" 指定使用 File Source,并且 include 选项用于配置文件位置(include 可以使用通配符来配置多个日志文件,请参阅文档)。 最后,我们需要配置 data_dir 以指定元数据目录。 Vector 的 data_dir 的默认路径是 /var/lib/vector/:
toml
[sinks.greptime_sink]
type = "greptimedb_logs"
inputs = [ "file_input" ]
compression = "gzip"
dbname = "public"
endpoint = "http://127.0.0.1:4000"
pipeline_name = "greptime_identity"
table = "app_log"
这是 GreptimeDB 日志 sink。 Sink 是 Vector 的数据输出,将数据发送到适配的输出端。 我们通过 type = "greptimedb_logs" 指定使用 GreptimeDB 日志输出,并且 inputs 指定使用上面的文件源。 此处的配置仅指定 GreptimeDB 的连接参数:
compression指定发送数据的压缩选项;dbname指定要摄取到的数据库; 在这里,我们将摄取到默认的public数据库;endpoint指定 GreptimeDB 实例的 HTTP 地址。 在上面,我们使用docker启动了 GreptimeDB 实例并将数据库的 4000 端口绑定到127.0.0.1;pipeline_name指定日志摄取的 pipeline。 Pipeline 是 GreptimeDB 内置的用于预处理文本数据的机制。 在这里我们使用greptime_identity,它不处理原始数据,而是直接将输入的 JSON 数据存储在数据库中的单独列中;table指定要将数据摄取到哪个数据库表。 如果此表不存在,则将自动创建它。
将日志摄取到 GreptimeDB
配置完成后,我们可以将文件中的日志数据摄取到 GreptimeDB。 运行以下命令以使用该配置启动 Vector: shell
vector -c <path_to_config_file>
如果我们看到以下日志并且没有看到任何 ERROR,我们可以确认 Vector 已开始将数据摄取到 GreptimeDB:
shell
2025-04-15T06:53:17.864603Z INFO vector::topology::builder: Healthcheck passed.
在 GreptimeDB 中查询数据
接下来,我们可以通过查询 GreptimeDB 来验证数据是否已摄取。 使用 MySQL 兼容的客户端通过运行 mysql -h127.0.0.1 -P4002 连接到数据库。
首先,执行 show tables 以检查表是否已成功创建:
shell
+---------+
| Tables |
+---------+
| app_log |
| numbers |
+---------+
2 rows in set (0.018 sec)
然后执行 select * from app_log limit 2; 以观察数据:
shell
+----------------------------+------------------------+-----------+------------------------------------------------------------------------------------------------------------------+-------------+--------------------------------+
| greptime_timestamp | file | host | message | source_type | timestamp |
+----------------------------+------------------------+-----------+------------------------------------------------------------------------------------------------------------------+-------------+--------------------------------+
| 2025-04-15 07:02:37.136667 | <path_to_file>/log.txt | some_host | 17.61.197.240 - nikolaus3107 [14/Apr/2025:21:11:44 +0800] "HEAD /envisioneer/efficient HTTP/1.0" 406 5946 | file | 2025-04-15T07:02:36.116847265Z |
| 2025-04-15 07:02:37.136674 | <path_to_file>/log.txt | some_host | 56.87.252.7 - - [14/Apr/2025:21:11:45 +0800] "PATCH /bricks-and-clicks/transition/interfaces HTTP/1.1" 416 15579 | file | 2025-04-15T07:02:36.116864203Z |
+----------------------------+------------------------+-----------+------------------------------------------------------------------------------------------------------------------+-------------+--------------------------------+
2 rows in set (0.032 sec)
我们可以看到,除了存储模拟日志的 message 列外,还有几个额外的列:
greptime_timestamp:由于我们使用了greptime_identity并且没有指定时间索引列(我们可以在greptime_identity模式下手动指定索引列,请参阅 文档),GreptimeDB 使用日志到达服务器的时间戳并将其设置为时间索引列。 通常,我们更希望将时间索引设置为实际的日志生成时间,以便更准确地还原事件序列;file、host、source_type、timestamp:细心的读者可能已经注意到,这些是 Vector 自动附加的运行时上下文信息。 如果不手动删除,Vector 默认会在输出时包含此上下文信息。
通过 log-query 查看数据
GreptimeDB 附带一个仪表板控制台,允许我们快速执行数据查询和操作。 在浏览器中输入 http://127.0.0.1:4000/dashboard/#/dashboard/log-query 以快速打开日志查询页面:
 (图 2:访问 Log-Query 页面)
单击 Table 下拉菜单,我们可以看到刚刚创建的
(图 2:访问 Log-Query 页面)
单击 Table 下拉菜单,我们可以看到刚刚创建的 app_log 表。 单击以选择 app_log 表,然后单击上面的 run 按钮以在 log-query 中查看刚刚摄取的日志数据:
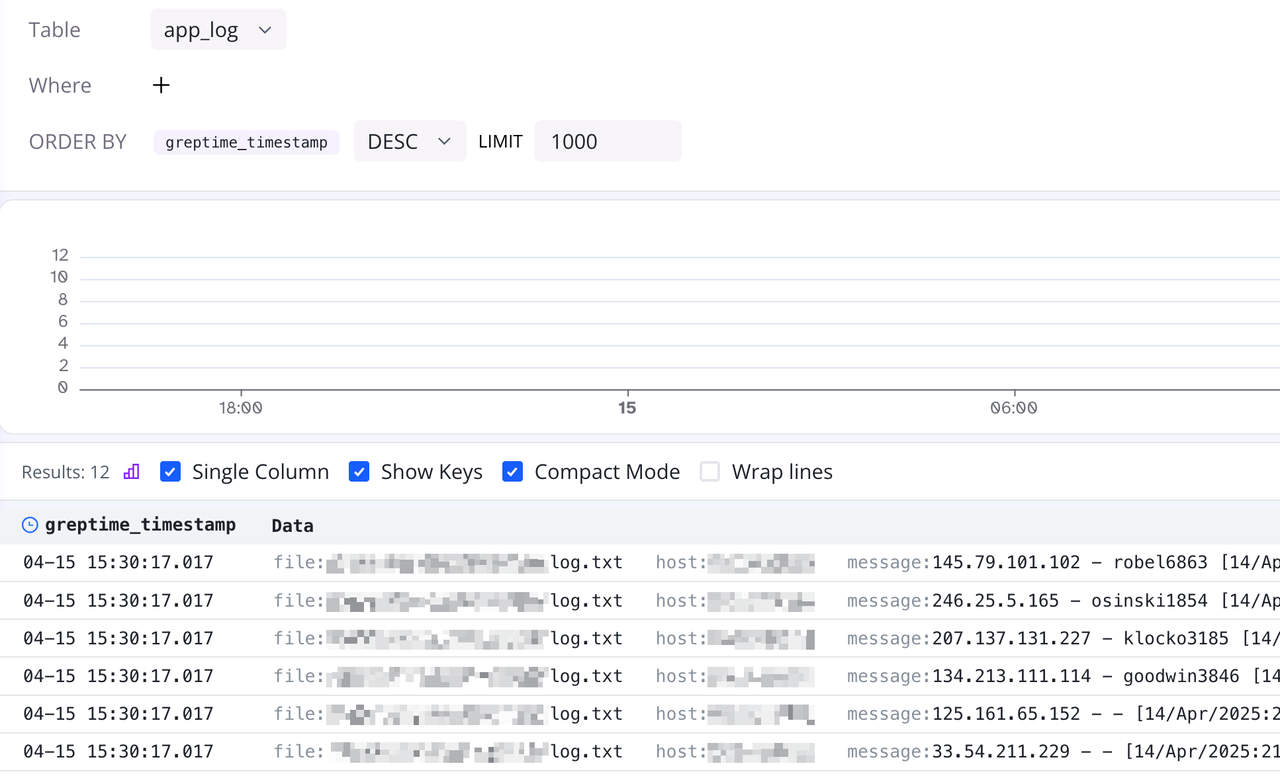 (图 3:查看摄取的数据)
(图 3:查看摄取的数据)
使用 Pipeline 解析日志
在上一节中,我们成功运行 Vector 从文件收集日志数据并将其摄取到 GreptimeDB 中。 但是,我们将整个日志行作为数据库中的单个列摄取。 这样,如果我们需要过滤某种类型的日志,我们只能依赖 LIKE 模糊查询,这不仅效率低下,而且不利于后续分析。
在生产环境中,日志通常通过 ETL 步骤进行预处理,将文本分解为结构化字段,然后再进入数据库。 上述 GreptimeDB 内置 Pipeline 机制在此处提供帮助。
接下来,我们将演示如何通过 Pipeline 解析日志文本以提高日志的使用效率。
Pipeline 配置
首先,在使用 Pipeline 之前,我们需要编写配置并将其保存到数据库中,以便 GreptimeDB 在运行时调用。 Pipeline 是基于输入的文本数据编写的。 以输入的 mock 日志文本为例,编写以下 Pipeline 配置:
yaml
# pipeline.yaml
processors:
- dissect:
fields:
- message
patterns:
- '%{client_ip} - %{user_identifier} [%{timestamp}] "%{http_method} %{request_uri} %{http_version}" %{status_code} %{response_size}'
ignore_missing: true
- date:
fields:
- timestamp
formats:
- '%d/%b/%Y:%H:%M:%S %z'
timezone: 'Asia/Shanghai'
ignore_missing: true
transform:
- fields:
- client_ip
- user_identifier
type: string
index: skipping
- fields:
- http_method
- http_version
type: string
index: inverted
- fields:
- request_uri
type: string
index: fulltext
- fields:
- status_code
type: int32
- fields:
- response_size
type: int64
- fields:
- timestamp
type: time
index: timestamp
Pipeline 主要由 processors 和 transform 组成。 前者处理数据,后者将处理后的字段转换为数据库识别的数据类型。 下面我们介绍 Pipeline 配置的每个部分:
yaml
processors:
- dissect:
fields:
- message
patterns:
- '%{client_ip} - %{user_identifier} [%{timestamp}] "%{http_method} %{request_uri} %{http_version}" %{status_code} %{response_size}'
ignore_missing: true
- date:
fields:
- timestamp
formats:
- '%d/%b/%Y:%H:%M:%S %z'
timezone: 'Asia/Shanghai'
ignore_missing: true
首先,使用 dissect processor 从长文本中提取字段。 可以基于空格提取诸如 client_ip 和 user_identifier 之类的字段。 然后使用 date processor 将时间文本转换为 timestamp 数据类型,使用解析格式和时区:
yaml
transform:
- fields:
- client_ip
- user_identifier
type: string
index: skipping
- fields:
- http_method
- http_version
type: string
index: inverted
- fields:
- request_uri
type: string
index: fulltext
- fields:
- status_code
type: int32
- fields:
- response_size
type: int64
- fields:
- timestamp
type: time
index: timestamp
接下来,使用 transform 将解析后的字段保存到数据库。
transform的语法很简单,只需组合相应的字段和类型即可;- 请注意,我们通过
index:向每个字段添加索引;- 同样,在
timestamp字段上指定index: timestamp,这意味着此字段被设置为时间索引列。
我们使用以下命令将 Pipeline 配置上传到数据库,将其命名为 app_log 并保存:
shell
curl -s -XPOST 'http://127.0.0.1:4000/v1/events/pipelines/app_log' -F 'file=@pipeline.yaml'
成功执行后,将返回以下 HTTP 响应: json
{
"pipelines": [
{
"name": "app_log",
"version": "2025-04-15 07:53:51.914557113"
}
],
"execution_time_ms": 8
}
我们还可以通过执行 select name from greptime_private.pipelines; 在 MySQL 兼容的客户端中确认:
更多详细的 Pipeline 配置选项可以在 官方文档 中找到。
注意:
- GreptimeDB 仪表板还提供 Pipeline 在线调试工具,我们可以使用此页面进行测试和调试。
- 我们还可以尝试利用 AI 进行 Pipeline 配置 😛(上面的 Pipeline 配置由 AI 生成)
更新 Vector 写入配置
要使用我们的自定义 Pipeline 配置,我们需要稍微修改 Vector 配置: toml
# config.toml
[sources.file_input]
type = "file"
include = [ "<path_to_log_dir>/log.txt" ]
data_dir = "<data_dir>"
ignore_checkpoints = true
[sinks.greptime_sink]
type = "greptimedb_logs"
inputs = [ "file_input" ]
compression = "gzip"
dbname = "public"
endpoint = "http://127.0.0.1:4000"
pipeline_name = "app_log"
table = "app_log_2"
- 在 File Source 中添加
ignore_checkpoints = true以允许 Vector 每次运行时重新读取同一文件(这仅用于调试示例); - 修改
pipeline_name = "app_log"以使用我们刚刚上传的 Pipeline 配置; - 修改
table = "app_log_2"以将新的日志数据保存到另一个表,避免与之前的app_log table冲突。
然后运行 vector -c <path_to_config_file> 以重写日志数据。
在 GreptimeDB 中查询数据
在 MySQL 兼容的客户端中运行 show tables 以查看是否已成功创建 app_log_2 表:
toml
+-----------+
| Tables |
+-----------+
| app_log |
| app_log_2 |
| numbers |
+-----------+
3 rows in set (0.008 sec)
我们可以运行 show index from app_log_2 以观察字段和索引:
sql
+-----------+------------+----------------+--------------+-----------------+-----------+-------------+----------+--------+------+----------------------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-----------+------------+----------------+--------------+-----------------+-----------+-------------+----------+--------+------+----------------------------+---------+---------------+---------+------------+
| app_log_2 | 1 | SKIPPING INDEX | 1 | client_ip | A | NULL | NULL | NULL | YES | greptime-bloom-filter-v1 | | | YES | NULL |
| app_log_2 | 1 | INVERTED INDEX | 3 | http_method | A | NULL | NULL | NULL | YES | greptime-inverted-index-v1 | | | YES | NULL |
| app_log_2 | 1 | INVERTED INDEX | 4 | http_version | A | NULL | NULL | NULL | YES | greptime-inverted-index-v1 | | | YES | NULL |
| app_log_2 | 1 | FULLTEXT INDEX | 5 | request_uri | A | NULL | NULL | NULL | YES | greptime-fulltext-index-v1 | | | YES | NULL |
| app_log_2 | 1 | TIME INDEX | 1 | timestamp | A | NULL | NULL | NULL | NO | | | | YES | NULL |
| app_log_2 | 1 | SKIPPING INDEX | 2 | user_identifier | A | NULL | NULL | NULL | YES | greptime-bloom-filter-v1 | | | YES | NULL |
+-----------+------------+----------------+--------------+-----------------+-----------+-------------+----------+--------+------+----------------------------+---------+---------------+---------+------------+
6 rows in set (0.05 sec)
我们可以看到,每个字段的索引也已正确创建。
然后使用 select * from app_log_2 limit 2 查看以下结果:
toml
+---------------+-----------------+-------------+------------------------------------------+--------------+-------------+---------------+---------------------+
| client_ip | user_identifier | http_method | request_uri | http_version | status_code | response_size | timestamp |
+---------------+-----------------+-------------+------------------------------------------+--------------+-------------+---------------+---------------------+
| 17.61.197.240 | nikolaus3107 | HEAD | /envisioneer/efficient | HTTP/1.0 | 406 | 5946 | 2025-04-14 13:11:44 |
| 56.87.252.7 | - | PATCH | /bricks-and-clicks/transition/interfaces | HTTP/1.1 | 416 | 15579 | 2025-04-14 13:11:45 |
+---------------+-----------------+-------------+------------------------------------------+--------------+-------------+---------------+---------------------+
2 rows in set (0.008 sec)
如此处所示,与原始日志行是单个列相比,现在日志被拆分为不同的字段,并以具有语义数据类型的单独列保存。 现在,我们可以通过诸如 where client_id = '17.61.197.240' 之类的条件对日志执行更精确的搜索查询,这不仅提高了查询的准确性,而且提高了查询效率。
通过 log-query 查看数据
同样,我们可以在 http://127.0.0.1:4000/dashboard/#/dashboard/log-query 查看 app_log_2 表中的数据,如下所示:
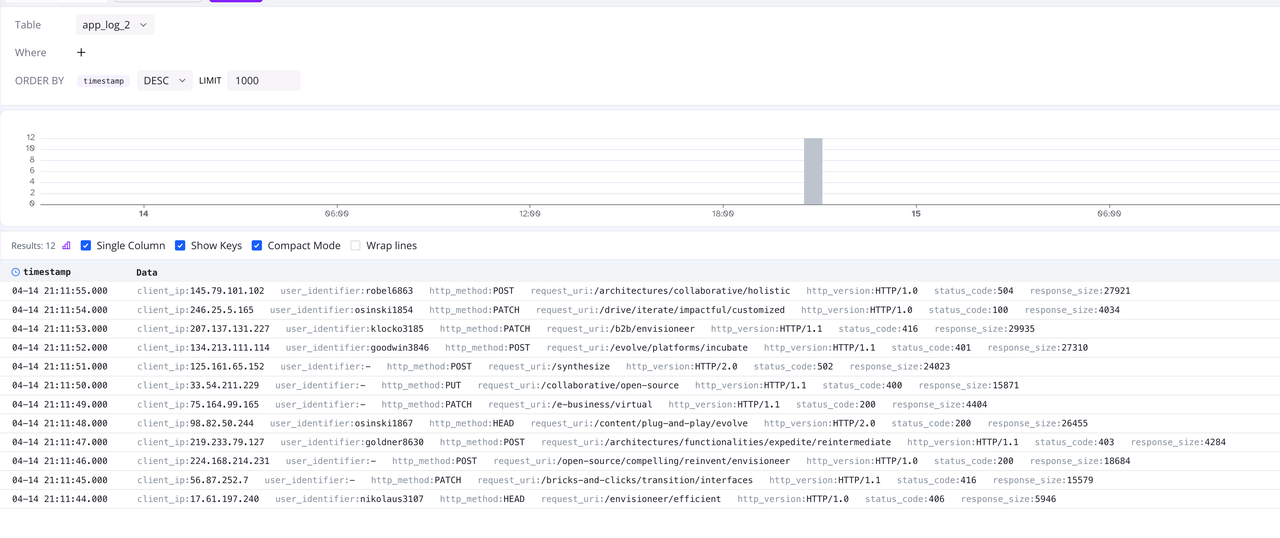 (图 4:查看 app_log_2 图表中的数据)
现在字段已拆分,我们可以通过
(图 4:查看 app_log_2 图表中的数据)
现在字段已拆分,我们可以通过 log-query 中的 Where 条件快速过滤数据,例如:
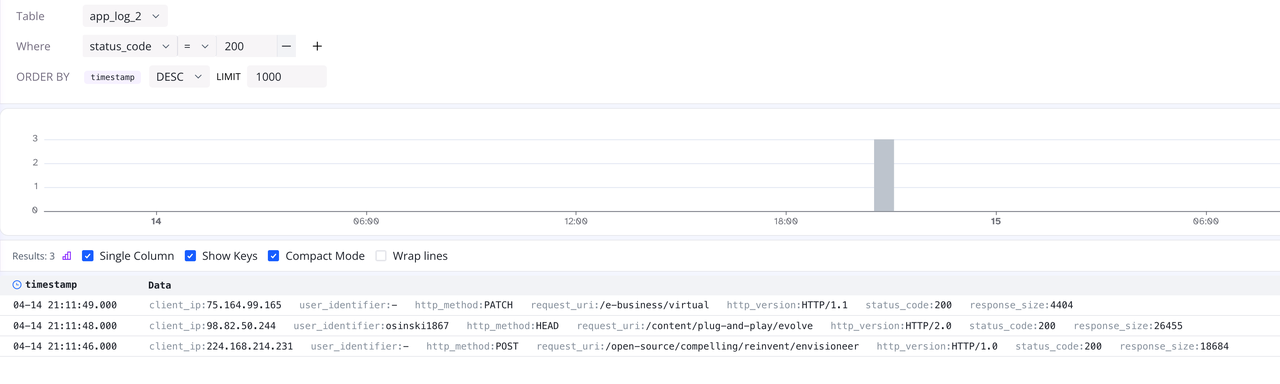 (图 5:快速过滤数据)
(图 5:快速过滤数据)
总结
本文探讨了日志存储解决方案,解释了 ELK 技术栈在当前情况下的缺点,并介绍了 GreptimeDB 作为下一代日志存储解决方案,它在架构和用户体验方面具有优势。 通过 Vector + GreptimeDB 的组合,我们演示了从日志收集到存储、解析和查询的完整过程。
在查询部分,我们演示了使用 MySQL 兼容的客户端和 GreptimeDB 的内置 log-query 工具进行数据检索。 作为开源、高度兼容的时序数据库,GreptimeDB 还支持与 Grafana 等可视化工具的无缝集成,使用户能够轻松地可视化和分析其数据。
如果您对日志处理和存储感兴趣,请随时修改本文中提供的配置,以探索更灵活和高效的日志存储解决方案。
关于 Greptime
GreptimeDB 是一个开源的云原生数据库,专为实时可观测性而构建。 它用 Rust 构建并针对云原生环境进行了优化,可为指标、日志和跟踪提供统一的存储和处理,从而以任何规模提供从边缘到云的亚秒级洞察。
- GreptimeDB OSS – 用于中小型可观测性和 IoT 用例的开源数据库,非常适合个人项目或开发/测试环境。
- GreptimeDB Enterprise – 具有增强的安全性、高可用性和企业级支持的强大可观测性数据库。
- GreptimeCloud – 一种完全托管的无服务器 DBaaS,具有弹性伸缩和零运营开销。 专为需要开箱即用的速度、灵活性和易用性的团队而构建。
🚀 我们欢迎贡献者——从标记为 good first issue 的问题开始,并与我们的社区建立联系。 ⭐ GitHub | 🌐 网站 | 📚 文档 💬 Slack | 🐦 Twitter | 💼 LinkedIn
加入我们的社区
获取最新更新并与其他用户讨论。
加入我们的开发者社区
GreptimeDB 是开源的。 在 Twitter 上关注我们,为我们的 GitHub 仓库加星,并在 Slack 上加入我们的开发者社区!
![]() GitHub
GitHub
![]() YouTube
YouTube
![]() Twitter
Twitter
![]() Slack
Slack
订阅我们的新闻通讯
获取有关 GreptimeDB 的最新日期和新闻。
链接
![]() Greptime #30
440 N. Wolfe Road
Sunnyvale, CA 94085
English
English
简体中文
Greptime #30
440 N. Wolfe Road
Sunnyvale, CA 94085
English
English
简体中文
产品
资源
- 文档
- 博客
- GreptimePlay
- 下载
- [Docker 仓库](https://greptime.c