兆芯的 KX-7000 处理器分析

Zhaoxin 是一家中国的 x86 CPU 设计公司。 KaiXian KX-7000 是 Zhaoxin 最新的 CPU,采用了一种名为 “世纪大道” 的新架构。“世纪大道” 是上海的一条路,Zhaoxin 沿用了以上海地标命名架构的惯例。Zhaoxin 值得关注,因为它是由 VIA Technologies 和上海市政府合资成立的。它继承了 VIA 的 x86-64 授权,并且享有强大的政府支持。这是一个强大的组合,因为 Zhaoxin 的核心旨在利用强大的 x86-64 软件生态系统。
x86-64 兼容性只是其中一部分,因为性能也很重要。Zhaoxin 之前的 LuJiaZui,在 KX-6640MA 中实现,显然不足以处理现代应用程序。LuJiaZui 是一个 2-wide 核心,时钟速度低于 3 GHz,并且重排序能力仅略高于 Intel 1997 年的 Pentium II。Century Avenue 旨在解决这个性能问题。
核心概览
Century Avenue 是一个 4-wide、支持 AVX2 的核心,其乱序执行窗口与 2010 年代初的 Intel CPU 相当。除了使核心更宽、延迟容忍度更高之外,Zhaoxin 还致力于提高时钟速度。KX-7000 的运行频率为 3.2 GHz,明显快于 KX-6640MA 的 2.6 GHz。Zhaoxin 的网站声称 KX-7000 可以达到 3.5-3.7 GHz,但我从未见过该芯片的时钟频率超过 3.2 GHz。

KX-7000 有八个 Century Avenue 核心,并使用类似于单 CCD AMD Ryzen 桌面部件的小芯片设置。所有八个核心都位于一个 die 上,并共享 32 MB 的 L3 缓存。第二个 IO die 连接到 DRAM 和其他 IO。Zhaoxin 没有说明他们使用的工艺节点。Techpowerup 和 Wccftech 建议它使用未指定的 16nm 节点。
前端
在前端,指令从 64 KB 16-way 指令缓存中提取。指令缓存每个周期可以提供 16 个字节,并馈送一个 4-wide 解码器。Century Avenue 使用了一种完全传统的前端设置,没有循环缓冲区或 op 缓存。因此,如果平均指令长度超过 4 个字节,指令缓存带宽可能会限制前端吞吐量。

当代码溢出 L1i 时,前端带宽急剧下降,这与 2010 年代西方设计形成了另一个对比。例如,Skylake 可以以每个周期超过 12 字节的速度从 L2 运行代码,足以以 4 字节指令实现 >3 IPC。如果代码溢出到 L3 中,Century Avenue 会遭受进一步的损失,此时前端带宽会降至每个周期 4 字节以下。

一个 4096 条目的分支目标缓冲区 (BTB) 提供分支目标,并在采取分支后创建两个流水线气泡。即使分支远少于 4K,采取分支的延迟也会随着测试溢出 L1i 而跳跃。BTB 很可能与 L1i 相关联,因此不能用于在 L1i 丢失后进行长距离预取。

Century Avenue 的分支性能让人想起像 VIA 的 Nano 这样的旧核心。与 LuJiaZui 相比,放弃零气泡分支能力是一种倒退,LuJiaZui 可以从一个小的 16 条目的 L0 BTB 中做到这一点。也许 Zhaoxin 认为他们无法在 Century Avenue 的 3 GHz+ 时钟速度目标下实现零气泡分支。然而,十多年前的 Intel 和 AMD CPU 在更高的时钟速度下具有更快的分支目标缓存。

就 Century Avenue 而言,方向预测器与其前代产品相比,具有大大改进的模式识别能力。当给出重复的 taken 和 not-taken 分支模式时,KX-7000 的处理方式有点像 Intel 的 Sunny Cove。

返回行为很像 LuJiaZui。调用 + 返回对享有合理的延迟,直到它们超过四层深度。更远处的拐点表明存在二级返回堆栈,大约有 32 个条目。如果存在二级返回堆栈,则它的速度相当慢,每个调用 + 返回对的成本为 14 个周期。Bulldozer 显示出更典型的行为。在溢出 24 个条目的返回堆栈之前,调用 + 返回对的速度很快。

Century Avenue 的前端旨在以最小的复杂性提供每个周期最多四个指令。如果调整得当,传统提取和解码设置可能会很好,但 Century Avenue 的前端存在一些明显的弱点。由于 VEX 前缀,AVX2 代码中的平均指令长度可能会超过 4 个字节。AMD 通过在 10h CPU 中将 L1i 带宽增加到 32B/cycle 来解决这个问题。Intel 在 Sandy Bridge 中引入 op 缓存之前,在 Core 2 中使用了循环缓冲区(同时保持 16B/cycle L1i 带宽)。任何一种方法都可以,但 Century Avenue 都没有这样做。Century Avenue 也没有实现分支融合,AMD 和 Intel 已经使用该技术十多年了。一个 [add, add, cmp, jz] 序列的执行速度低于 3 IPC。
缺乏复杂性也延伸到了分支目标缓存。具有有效 3 周期延迟的单级 BTB 在今天感觉很原始,尤其是当它与指令缓存相关联时。与之前一样,解耦 BTB 不是唯一的方法。Apple 的 M1 似乎也具有与 L1i 耦合的 BTB,但它通过巨大的 192 KB L1i 进行补偿。Century Avenue 的 64 KB L1i 大于许多 x86-64 核心上的 32 KB 指令缓存,但它并没有像 Apple 那样强行解决大型代码占用空间的问题。公平地说,对于 Zhaoxin 来说,Bulldozer 也将 64 KB L1i 与较差的 L2 代码带宽结合在一起。但是,我不认为在任何 2024 年后的核心上,特别是运行频率低于 4 GHz 的核心上,3 周期 taken 分支延迟有很好的理由。
重命名和分配
来自前端的微指令被分配到后端跟踪结构中,这些结构执行乱序执行所需的簿记。寄存器分配与寄存器重命名齐头并进,寄存器重命名通过在指令写入寄存器时分配一个新的物理寄存器来打破错误的依赖关系。重命名/分配阶段也是执行其他优化并向后端公开更多并行性的便捷位置。
Century Avenue 识别零化习惯用法,例如用自身 XOR 寄存器,并且可以告诉后端此类指令是独立的。然而,此类 XOR 仍然限制为每个周期三个,这表明它们使用 ALU 端口。即使结果始终为零,重命名器也会分配一个物理寄存器来保存结果。移动消除也有效,但它也限制为每个周期三个。
乱序执行
Zhaoxin 切换到基于物理寄存器文件 (PRF) 的执行方案,从而远离 LuJiaZui 的基于 ROB 的设置。单独的寄存器文件减少了核心内的数据传输,并让设计人员能够独立于寄存器文件容量来扩展 ROB 大小。这两者都是优于 LuJiaZui 的显着优势,并且有助于 Century Avenue 具有数倍的重排序能力。凭借 192 条目的 ROB,Century Avenue 具有与 Intel 的 Haswell、AMD 的 Zen 和 Centaur 的 CNS 相当的理论乱序窗口。LuJiaZui 的 48 条目 ROB 根本无法比拟。

重排序缓冲区大小仅限制后端可以搜索到停顿指令之前的距离。实际上,重排序容量受到核心首先耗尽的任何资源(无论是寄存器文件、内存排序队列还是其他结构)的限制。Century Avenue 的寄存器文件比 Haswell 或 Zen 的小,但核心可以保持合理数量的分支和内存操作处于活动状态。
Century Avenue 具有半统一调度器设置,从而摆脱了 LuJiaZui 的分布式方案。ALU、内存和 FP/vector 操作各自都有一个超过 40 个条目的大型调度器。分支似乎有自己的调度器,但可能没有专用的端口。我无法在同一周期内执行 not-taken 跳转以及三个整数加法。无论如何,尽管 Century Avenue 具有更多的执行端口,但其调度队列少于其前代产品。这使得调整调度器大小变得更容易,因为自由度更少。

通常,统一调度器可以使用比分布式调度器更少的总条目来实现类似的性能。统一调度队列中的条目可以容纳调度器任何端口的挂起微指令。这减少了单个队列填满并阻止更多传入指令的可能性,即使调度器条目在其他队列中可用。凭借多个大型多端口调度器,Century Avenue 比 Haswell、Centaur CNS 甚至 Skylake 具有更多的调度器容量。
执行单元
三个 ALU 管道生成标量整数运算的结果。因此,Century Avenue 加入了 Arm 的 Neoverse N1 和 Intel 的 Sandy Bridge,在一个整体 4-wide 核心中拥有三个 ALU 端口。Century Avenue 的两个 ALU 管道具有整数乘法器。64 位整数乘法的延迟仅为两个周期,从而为核心提供了出色的整数乘法性能。
Century Avenue 的 FP/vector 方面出奇地强大。FP/vector 单元似乎有四个管道,所有管道都可以执行 128 位向量整数加法。浮点运算以每个周期两个的速度执行。令人惊讶的是,即使对于 256 位向量 FMA 指令,该速率也适用。因此,Century Avenue 匹配了 Haswell 的每周期 FLOP 计数。浮点延迟是正常的,FP 加法和乘法的延迟为 3 个周期,融合乘加的延迟为 5 个周期。向量整数加法的延迟为单周期。

然而,Century Avenue 的其余执行引擎对 AVX2 并不那么热情。对于我测试的所有常见情况,在 256 位向量上运行的指令被分解为两个 128 位微指令。256 位 FP 加法占用两个 ROB 条目、两个调度器槽,并且结果消耗两个寄存器文件条目。在内存方面,256 位加载和存储分别占用两个加载队列或两个存储队列条目。Zhaoxin 的 AVX2 方法与 Zen 4 的 AVX-512 策略相反:AMD 在很大程度上保持了与上一代相同的执行吞吐量,但是,其 512 位寄存器文件条目使其可以保持更多的工作处于活动状态并更好地为这些执行单元提供服务。Century Avenue 的方法是首先提高执行吞吐量,然后再考虑如何为其提供服务。
核心内存子系统
内存访问从一对地址生成单元 (AGU) 开始,这些单元计算虚拟地址。AGU 由 48 个调度器条目馈送,这些条目可以是 48 个条目的统一调度器或两个 24 个条目的队列。
来自 AGU 的 48 位虚拟地址然后转换为 46 位物理地址。数据侧地址转换缓存在 96 个条目、6-way 组相联数据 TLB 中。2 MB 页面使用单独的 32 个条目、4-way DTLB。Century Avenue 不通过 CPUID 报告 L2 TLB 容量,并且 DTLB 丢失会增加 ~20 个周期的延迟。对于具有二级 TLB 的核心来说,这高于正常水平,除了 Bulldozer 之外。

除了地址转换之外,加载/存储单元还必须处理内存依赖关系。Century Avenue 似乎使用虚拟地址执行初始依赖关系检查,因为加载对偏移 4 KB 的存储具有错误的依赖关系。对于真正的依赖关系,Century Avenue 可以执行延迟为 5 个周期的存储转发。与许多其他核心一样,部分重叠会导致快速转发失败。在这种情况下,Century Avenue 会产生 22 个周期的惩罚,这并不离谱。对于独立的访问,Century Avenue 可以执行 Core 2 样式的内存消歧。这使加载可以在具有未知地址的存储之前执行,从而提高了内存管道利用率。
跨越缓存行边界的“未对齐”加载和存储需要 12-13 个周期,与现代核心相比,这是一个沉重的惩罚。例如,Skylake 几乎不会因未对齐的加载而受到任何惩罚,并且只需一个周期的惩罚即可处理未对齐的存储。如果加载依赖于未对齐的存储,Century Avenue 将面临最重的惩罚(>42 个周期)。
核心私有缓存
Century Avenue 具有一个 32 KB、8-way 组相联数据缓存,具有一对 128 位端口和 4 个周期的加载到使用延迟。只有一个端口处理存储,因此 256 位存储在两个周期内执行。因此,Century Avenue 的 L1D 带宽类似于 Sandy Bridge,即使其 FMA 功能可能需要更高的带宽。当 Intel 首次推出具有 Haswell 的 2×256 位 FMA 执行时,他们的工程师将 L1D 带宽增加到每个周期 2×256 位加载和一个 256 位存储。

L2 延迟在 15 个周期时令人印象深刻。例如,Skylake-X 具有更大的 2 MB L2,并且在更高的时钟速度下以 14 个周期的延迟运行。
共享缓存和系统架构
Century Avenue 的系统架构已经过彻底修改,以提高核心数量的可扩展性。KX-7000 采用三级缓存设置,与 AMD、Arm 和 Intel 的高性能设计保持一致。核心私有的 L2 缓存有助于将 L1 丢失与高 L3 延迟隔离开来。因此,L3 延迟变得不那么关键,这使得可以在更多核心之间共享更大的 L3。与 LuJiaZui 相比,Century Avenue 将 L3 容量增加了八倍,从 4 MB 增加到 32 MB。八个 Century Avenue 核心共享 L3,而四个 LuJiaZui 核心共享 4 MB L2。结合小芯片设置,KX-7000 的构建方式非常类似于单 CCD Zen 3 桌面部件。

与 AMD 最近的设计不同,L3 延迟很差,超过 27 ns,或超过 80 个核心周期。带宽也不算太大,仅略高于每个周期 8 个字节。读取-修改-写入模式将带宽增加到每个周期 11.5 字节。这两个数字都不令人印象深刻。Skylake 可以使用只读模式从 L3 平均每个周期 15 个字节,而最近的 AMD 设计可以实现两倍的带宽。
![]()
KX-7000 确实享有良好的带宽扩展,但低时钟速度与低每核心带宽相结合意味着最终数据并不令人印象深刻。只读模式达到 215 GB/s,而读取-修改-写入模式可以超过 300 GB/s。相比之下,Zen 2 CCD 享有两倍以上的 L3 带宽。

KX-7000 确实比 Intel 的 Skylake-X 具有更多的 L3 带宽,至少在使用匹配的线程数进行测试时是这样。但是,Skylake-X 具有更大的 1 MB L2 缓存,可以将核心与较差的 L3 性能隔离。Skylake-X 也是一个面向服务器的部件,其中单线程性能不太重要。在客户端方面,Bulldozer 具有相似的 L3 延迟,但使用更大的 2 MB 来避免击中它。
DRAM 访问
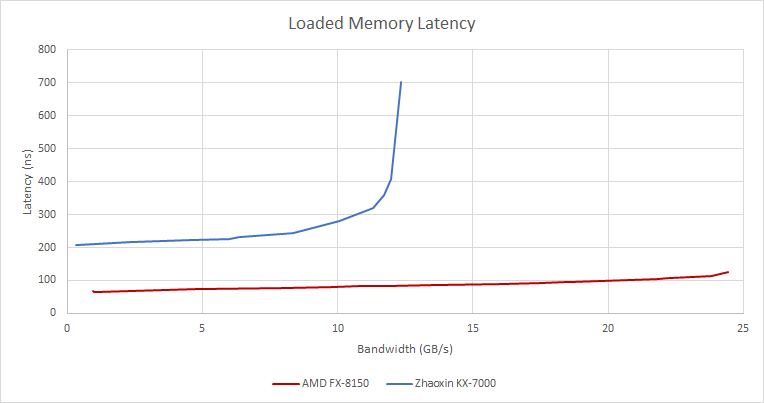
DRAM 性能很差,即使在使用 2 MB 页面来最大限度地减少地址转换延迟时,延迟也超过 200 ns。使用 4 KB 页面时,延迟超过 240 ns,两种情况下都使用 1 GB 数组。KX-7000 的 DRAM 带宽情况很复杂。首先,尽管使用了具有 2666 MT/s JEDEC 和 4000 MT/s XMP 配置文件 的 DIMM,但内存控制器只能训练到 1600 MT/s。因此,理论带宽限制为 25.6 GB/s。但是,测量的读取带宽根本无法接近,甚至难以超过 12 GB/s。

混合写入会增加可实现的带宽。读取-修改-写入模式达到 20 GB/s 以上,而非时序写入达到 23.35 GB/s。后一个数字接近理论值,表明 Zhaoxin 的跨 die 链接具有足够的带宽来饱和内存控制器。读取带宽可能受到延迟的限制。与写入不同,写入的数据被移交,读取只有在数据返回时才能完成。维持高读取带宽需要保持足够的内存请求处于活动状态以隐藏延迟。

通常,加载更多核心可以让内存子系统保持更多请求处于活动状态,因为每个核心都有自己的 L1 和 L2 丢失队列。然而,一旦带宽测试加载了超过两个核心,KX-7000 的读取带宽就会突然停止扩展。这表明所有核心共享的队列没有足够的条目来隐藏延迟,从而导致低读取带宽。
[ ](https://chipsandcheese.com/p/<https:/
](https://chipsandcheese.com/p/<https:/