Phi-4 Reasoning Models
一年回顾:Phi 小语言模型在 AI 领域取得重大进展
[正文内容]
Microsoft 通过发布最新的模型,即 Phi-4-reasoning、Phi-4-reasoning-plus 和 Phi-4-mini-reasoning,持续为对话式 AI 添砖加瓦。
AI 的新纪元
一年前,Microsoft 通过在 Azure AI Foundry 上发布 Phi-3,向客户介绍了小型语言模型(SLM)。此举利用了对 SLM 的研究,扩展了可供客户使用的高效 AI 模型和工具的范围。
今天,我们很高兴推出 Phi-4-reasoning、Phi-4-reasoning-plus 和 Phi-4-mini-reasoning——这标志着小型语言模型的新纪元,并再次重新定义了小型高效 AI 的可能性。

Azure AI Foundry
找到满足您业务需求的理想模型,然后在项目中进行调整和自定义,以实现您的所有 AI 目标。
推理模型:前进的下一步
推理模型经过训练,可以利用推理时扩展来执行复杂的任务,这些任务需要多步骤分解和内部反思。 它们擅长数学推理,并且正在成为具有复杂多方面任务的代理应用程序的骨干。 这种能力通常只在大型前沿模型中才能找到。 Phi 推理模型引入了一个新的小型语言模型类别。 通过使用提炼、强化学习和高质量的数据,这些模型可以平衡大小和性能。 它们足够小,可以用于低延迟环境,但又保持了强大的推理能力,可以与更大的模型相媲美。 这种混合使甚至资源有限的设备也可以有效地执行复杂的推理任务。
Phi-4-mini-reasoning
Phi-4-mini-reasoning旨在满足对紧凑型推理模型的需求。 这种基于transformer的语言模型经过优化,可用于数学推理,可在计算或延迟受限的环境中提供高质量、逐步的问题解决。 Phi-4-mini-reasoning使用由Deepseek-R1模型生成的合成数据进行微调,从而平衡了效率和高级推理能力。 它非常适合教育应用程序、嵌入式辅导以及在边缘或移动系统上的轻量级部署,并且经过了超过一百万个不同的数学问题的训练,这些问题涵盖了从初中到博士学位的多个难度级别。 今天就在Azure AI Foundry或HuggingFace上试用该模型。
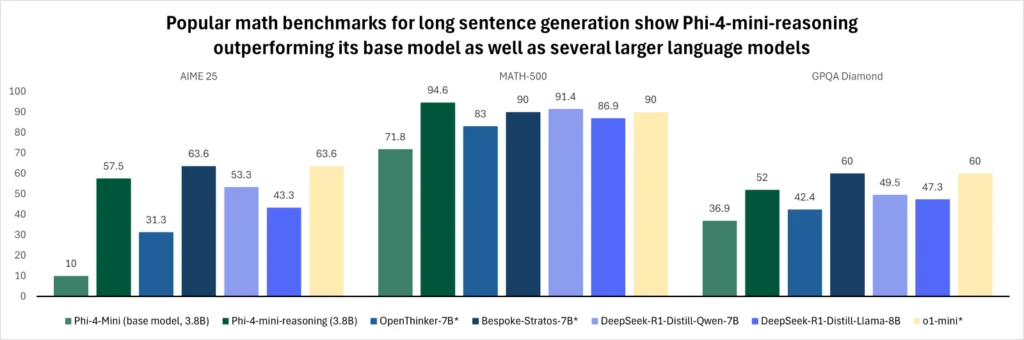 图 1. 该图比较了各种模型在流行的数学基准测试中针对长句子生成的性能。 在每次评估中,Phi-4-mini-reasoning在长句子生成方面的表现均优于其基础模型,并且优于像OpenThinker-7B*,Llama-3.2-3B-instruct, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama -8B, 和 Bespoke-Stratos-7B* 这样更大的模型。 Phi-4-mini-reasoning在数学基准测试中与OpenAI o1-mini*相当,在Math-500和GPQA Diamond评估中超过了该模型的性能。 如上所示,具有 3.8B 个参数的 Phi-4-mini-reasoning 的性能优于两倍以上的模型。
图 1. 该图比较了各种模型在流行的数学基准测试中针对长句子生成的性能。 在每次评估中,Phi-4-mini-reasoning在长句子生成方面的表现均优于其基础模型,并且优于像OpenThinker-7B*,Llama-3.2-3B-instruct, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama -8B, 和 Bespoke-Stratos-7B* 这样更大的模型。 Phi-4-mini-reasoning在数学基准测试中与OpenAI o1-mini*相当,在Math-500和GPQA Diamond评估中超过了该模型的性能。 如上所示,具有 3.8B 个参数的 Phi-4-mini-reasoning 的性能优于两倍以上的模型。
有关该模型的更多信息,请阅读技术报告,该报告提供了更多定量见解。
Phi-4-reasoning 和 Phi-4-reasoning-plus
Phi-4-reasoning 是一个 140 亿参数的开放权重推理模型,在复杂的推理任务上可以与更大的模型相媲美。 Phi-4-reasoning 通过对 Phi-4 进行监督微调,并使用来自 OpenAI o3-mini 仔细策划的推理演示进行训练,从而生成详细的推理链,从而有效地利用额外的推理时计算。 该模型表明,细致的数据策划和高质量的合成数据集使较小的模型能够与较大的模型竞争。 该模型现已在 Azure AI Foundry 和 HuggingFace 上提供。
Phi-4-reasoning-plus 在 Phi-4-reasoning 功能的基础上构建,通过强化学习进一步训练,以利用更多的推理时计算(使用比 Phi-4-reasoning 多 1.5 倍的 token),从而提供更高的准确性。 该模型即将登陆 Azure AI Foundry,但今天已在 HuggingFace 上提供。
尽管它们的尺寸明显较小,但两种模型在大多数基准测试中都优于 OpenAI o1-mini 和 DeepSeek-R1-Distill-Llama-70B,包括数学推理和博士学位的科学问题。 它们在 AIME 2025 测试(美国数学奥林匹克竞赛的 2025 年资格赛)中实现了优于完整 DeepSeek-R1 模型(具有 6710 亿个参数)的性能。
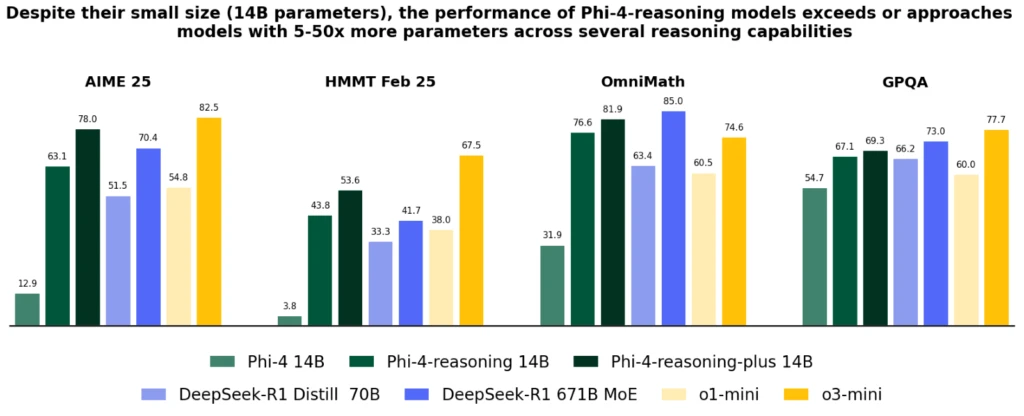 图 2. Phi-4-reasoning 在涵盖数学和科学推理的代表性推理基准测试中的性能。 我们展示了 Phi-4 通过 Phi-4-reasoning (SFT) 和 Phi-4-reasoning-plus (SFT+RL) 进行的以推理为中心的后期训练所带来的性能提升,以及来自两个模型系列的代表性基线:来自 DeepSeek 的开放权重模型,包括 DeepSeek R1 (671B Mixture-of-Experts) 及其精炼的密集变体 DeepSeek-R1 Distill Llama 70B,以及 OpenAI 的专有前沿模型 o1-mini 和 o3-mini。 Phi-4-reasoning 和 Phi-4-reasoning-plus 一致地优于基础模型 Phi-4,优势明显,超过了 DeepSeek-R1 Distill Llama 70B(大 5 倍),并在性能上与更大的模型(如 Deepseek-R1)相比具有竞争力。
图 2. Phi-4-reasoning 在涵盖数学和科学推理的代表性推理基准测试中的性能。 我们展示了 Phi-4 通过 Phi-4-reasoning (SFT) 和 Phi-4-reasoning-plus (SFT+RL) 进行的以推理为中心的后期训练所带来的性能提升,以及来自两个模型系列的代表性基线:来自 DeepSeek 的开放权重模型,包括 DeepSeek R1 (671B Mixture-of-Experts) 及其精炼的密集变体 DeepSeek-R1 Distill Llama 70B,以及 OpenAI 的专有前沿模型 o1-mini 和 o3-mini。 Phi-4-reasoning 和 Phi-4-reasoning-plus 一致地优于基础模型 Phi-4,优势明显,超过了 DeepSeek-R1 Distill Llama 70B(大 5 倍),并在性能上与更大的模型(如 Deepseek-R1)相比具有竞争力。
 图 3. 模型在通用基准测试中的准确性,包括:长输入上下文 QA (FlenQA)、指令跟随 (IFEval)、编码 (HumanEvalPlus)、知识和语言理解 (MMLUPro)、安全检测 (ToxiGen) 和其他一般技能 (ArenaHard 和 PhiBench)。
图 3. 模型在通用基准测试中的准确性,包括:长输入上下文 QA (FlenQA)、指令跟随 (IFEval)、编码 (HumanEvalPlus)、知识和语言理解 (MMLUPro)、安全检测 (ToxiGen) 和其他一般技能 (ArenaHard 和 PhiBench)。
Phi-4-reasoning 模型与 Phi-4 相比有了重大改进,在各种推理和一般能力(包括数学、编码、算法问题解决和计划)方面超越了更大的模型(如 DeepSeek-R1-Distill-70B),并接近 Deep-Seek-R1。 技术报告通过各种推理任务提供了这些改进的大量定量证据。
Phi 推理模型的实际应用
Phi 在过去一年中的演变不断突破质量与尺寸的界限,并通过新增系列来满足不同的需求。 在 Windows 11 设备的范围内,这些模型可以在 CPU 和 GPU 上本地运行。
随着 Windows 致力于创建一种新型 PC,Phi 模型已成为 Copilot+ PC 的组成部分,并具有 NPU 优化的 Phi Silica 变体。 Phi 的这种高效且由 OS 管理的版本旨在预加载到内存中,并具有极快的首个 token 响应时间和节能的 token 吞吐量,因此可以与其他在 PC 上运行的应用程序同时调用。
它用于核心体验,例如 Click to Do,为屏幕上的任何内容提供有用的文本智能工具,并可用作 developer APIs,以便轻松集成到应用程序中——已在诸如 Outlook 之类的多个生产力应用程序中使用,以离线提供其 Copilot 摘要功能。 这些小而强大的模型已经过优化和集成,可以在我们的 PC 生态系统的众多应用程序中使用。 Phi-4-reasoning 和 Phi-4-mini-reasoning 模型利用了 Phi Silica 的低位优化,并且很快将在 Copilot+ PC NPU 上运行。
安全性和 Microsoft 的负责任 AI 方法
在 Microsoft,负责任的 AI 是一项基本原则,指导着 AI 系统(包括我们的 Phi 模型)的开发和部署。 Phi 模型的开发符合 Microsoft AI 原则:问责制、透明度、公平性、可靠性和安全性、隐私和安全性以及包容性。
Phi 系列模型采用了强大的安全后期训练方法,结合了监督微调 (SFT)、直接偏好优化 (DPO) 和来自人类反馈的强化学习 (RLHF) 技术。 这些方法利用各种数据集,包括侧重于有用性和无害性的公开可用数据集,以及各种与安全相关的问题和答案。 虽然 Phi 系列模型旨在有效地执行各种任务,但重要的是要承认所有 AI 模型都可能存在局限性。 为了更好地了解这些局限性以及解决这些局限性所采取的措施,请参阅下面的模型卡,其中提供了有关负责任的 AI 实践和指南的详细信息。