Monkeys.zip 项目的幕后制作
Monkeys.zip 的幕后制作 (第一部分)
2025年5月1日
自 Monkeys.zip 发布 以来已经一个月了。在这段时间里,我们收集了超过 11,000 只 monkeys,它们已经写了超过 60 亿个单词 —— 完成了莎士比亚作品中超过 75% 的单词。 事实上,它们最近完成了 每一个四字母单词的写作!

虽然最初的热潮已经消退,但 monkeys 仍然像以往一样努力地打字,我想现在是时候谈谈我是如何构建这个网站的了。 如果你对这部分不感兴趣,请查看第二部分,我在其中详细介绍了 monkey 的名字!
技术栈
| 后端 & 数据库: | Supabase | |---|---| | 前端库: | LitHTML | | 3D 库: | Three.JS | | 博客: | Astro |
这是一个相对较短的技术列表 —— 因为我倾向于在我自己的 side projects 中尽可能多地从头开始构建,这出于一种固执。 例如,在这个项目中,我创建了一个名为 StateFarm 的状态管理库。 它很糟糕,不要使用它。
模拟架构
更有趣的是后端模拟是如何组合在一起的 —— 它构建为一个松散耦合的 pipeline,包含四个主要步骤:
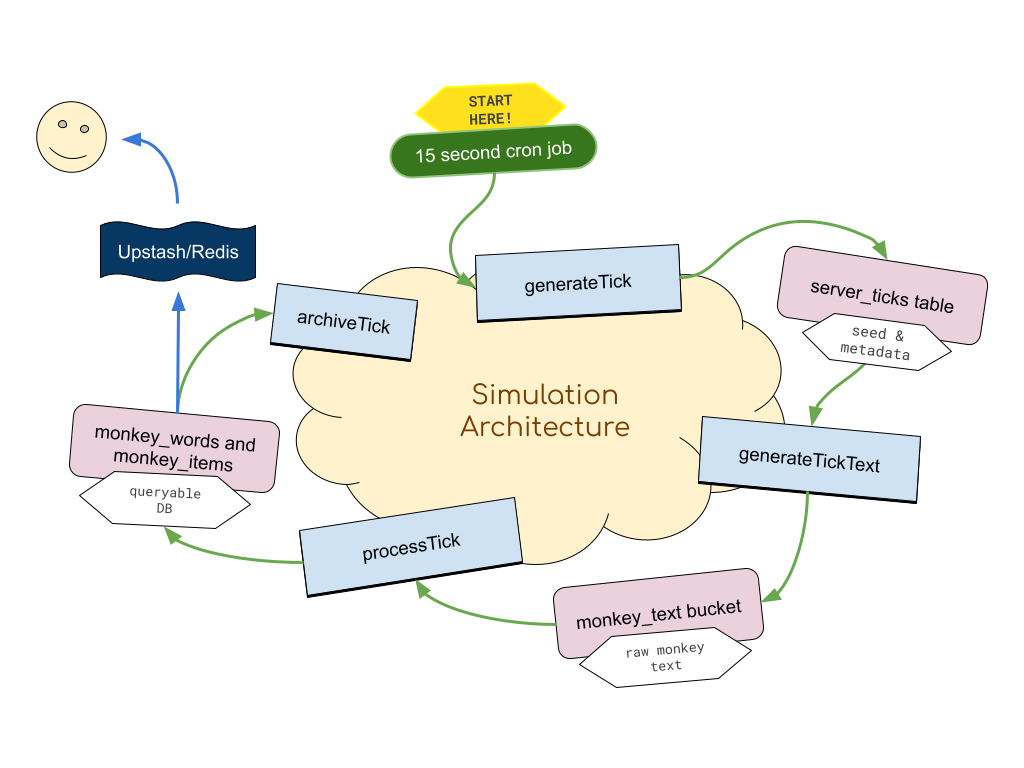
Ticks
第一个重要的设计决策来自于 Ticks 的概念。 后端以 15 秒 的批次生成数据。 上述 pipeline 每 15 秒运行一次,生成 15 秒的 monkey 文本。 选择此间隔长度是为了在减少每个步骤的运行时间、使错误更容易重试和恢复、将 DB 负载分散到更小的块中,同时减少服务器 <——> 客户端带宽和请求之间进行权衡。
第一步 (generateTick)
每 15 秒,一个 cronjob 调用一个 generateTick 函数 —— 它只有一个 job —— 就是在 ticks 表中放入一个新的 tick 行。
| Tick ID | 开始时间 | Seed | 状态 | |---|---|---|---| | 1234 | 04:13:25 | wn9837xw9873v | NEW |
这就是它所做的全部! 保持这一步骤如此简单和万无一失对于后续步骤的可靠性至关重要。 如果它们失败了,或者发生了巨大的数据丢失,只要我们在此表中有一个条目,一切都可以根据需要重建或重试。
第二步 (generateTickText)
当一个新的 tick 被添加到这个表时,generateTickText 通过 WebHook 被调用。 这个函数的工作是为每个 monkey 生成该 15 秒 tick 的文本。
我们使用 sfc32 根据 seed 确定性地生成随机数,seed 是 tick seed 与 monkey seed 的合并。 这种策略允许一个非常确定性的随机 monkey 文本生成器,可以在服务器端和客户端执行。
note
我为此挣扎了一段时间,在内部争论我是否应该以更随机的方式只在服务器上生成文本。 对于数据来说,感觉更具有哲学上的纯粹性是 “真正” 随机的。 缺点是增加了带宽(每个 monkey 发送 150 字节,而不是 24 字节 seed)。
从技术上讲,由于 鸽巢原理,monkey-tick-seeds 的数量远少于 15 秒 monkey 阐述的数量。 但是,一旦我们耗尽现有空间(它提供 2^128 个状态并将持续数十年),我们就可以着手引入更大的随机空间
生成文本后,我们将其放入 Storage bucket 中。 这不是绝对必要的,但我喜欢这种透明度。 为了调试或调查的目的,能够浏览 monkeys 编写的所有文本而无需重新生成它们是一件好事。
第三步 (processTick)
当文本被放入 Storage 时,另一个 WebHook 被调用,它梳理文本并搜索与字典的匹配项。 它构建了一个巨大的批处理更新,用于我们数据库中的多个 Table。
monkey_words- 每个 monkey 编写的每个(有效)单词的真实来源word_counts_cache- 更快地查找给定单词(例如,“monkey” 出现了 100 次)monkey_items- 任何 monkey 获得的物品都会被授予到此表
第四步 (Archive)
最近添加了一个单独的清理脚本,该脚本在 cron job 上运行 —— 其目的是从 monkey_words 表中存档旧的短单词,并将它们放入 monkey_words_archived 表中 —— 这大大加快了 monkey_words 的读取速度(它在数十亿行时开始变慢)。
其他后端事项
monkeys 的网格被标记为 64x64 的 chunks —— 除了为在应用程序中滚动浏览 monkeys 时创建最小查询大小之外,几乎没有其他价值 —— 并且允许我在 Redis 中缓存这些 chunks。 在正常流量期间,从 Redis 获取缓存结果实际上比仅查询 DB 慢(超过 100 毫秒)—— 但在应用程序受到 reddit 冲击的早期,能够在不需要数据库响应的情况下渲染 monkeys 是一件救命稻草。
仍然有很多优化工作要做。 既然我们正在进入这个项目的“收益递减”部分,我很乐意加快 monkey 的打字速度,以便我们可以开始处理 6 个和 7 个字母的单词,但这将需要进一步的架构更改。 我主要考虑购买一个具有大量 RAM 的自定义 VPS,并在内存中完成所有操作以提高速度。