理解与应用:Bloom Filter (布隆过滤器)
Bloom Filter
2025年5月1日 18:35 标签:Go
创建 Bloom Filter 的最初动机是高效的集合成员判断,它采用一种概率方法,能够显著减少拒绝那些不在特定集合中的元素所需的时间和空间。
该数据结构由 Burton Bloom 在 1970年的一篇论文 中提出,标题为 "Space/Time Trade-offs in Hash Coding with Allowable Errors"。这是一篇值得阅读的好论文。
为什么要使用 Bloom Filter?
假设我们将一些信息存储在磁盘上,并且想要检查某个文件是否包含某个特定的条目。从磁盘读取数据非常耗时,所以我们希望尽可能地减少读取操作。Bloom Filter 是一种数据结构,它实现了一个具有概率特性的缓存:
- 如果缓存说某个 key 不存在于特定文件中,那么可以 100% 确定我们不应该读取该文件。
- 如果缓存说某个 key _存在_于文件中,那么存在很小的概率这是一个假阳性(实际上该 key 并不在那里)。在这种情况下,我们只需像往常一样读取文件。
在大多数查询 "这个 key 是否在这个文件中?" 的答案都是否定时,Bloom Filter 可以显著地加速系统 [1]。 此外,概率性质(存在假阳性)使得 Bloom Filter 非常快速并且占用非常少的空间。以下是 Bloom 论文中的引言:
将要介绍的新的哈希编码方法适用于待测试消息绝大多数不属于给定集合的应用。 对于这些应用,适合将对测试消息进行分类为给定集合的非成员所需的平均时间视为一个时间单位(称为_reject time_)。
Bloom Filter 的工作原理
Bloom Filter 是一种特殊的 hash table with open addressing。 它是一个位数组(长度通常表示为 m),以及固定数量 (k) 的哈希函数。 我们假设每个哈希函数都可以接受任意的字节序列,并将其哈希为 [0, m-1] 范围内的整数。Bloom Filter 支持两种操作:
插入一个元素:使用 k 个哈希函数对元素进行哈希,并将底层数组中相应的位设置为 1。
测试一个元素是否为成员:使用 k 个哈希函数对元素进行哈希。 如果任何一个哈希函数结果对应的位是 0,则可以确定地返回 "false"。 如果所有位都是 1,则返回 "true" - 并且存在很小的假阳性概率。
以下是 Bloom 论文中的描述:
哈希区域被视为 N 个单独的可寻址位,地址为 0 到 N - 1。 假设哈希区域中的所有位首先设置为 0。 接下来,要存储的集合中的每个消息都被哈希编码为多个不同的位地址,例如 a1, a2, . . . , ad。 最后,将 a1 到 ad 寻址的所有 d 位设置为 1。 为了测试新消息,以与存储消息相同的方式生成 d 位地址序列,例如 a'1, a'2, ... a'd。 如果所有 d 位都是 1,则接受新消息。 如果这些位中的任何一位为零,则拒绝该消息。
希望现在很清楚为什么这种数据结构本质上是概率性的:不同的元素可能哈希到相同的数字,因此当我们测试某个 X 时,其所有哈希都指向由其他数据哈希打开的位。 请阅读 Math 附录,了解 Bloom Filter 背后的数学原理,以及如何计算(并针对特定情况设计)假阳性率。
这是一个例子:
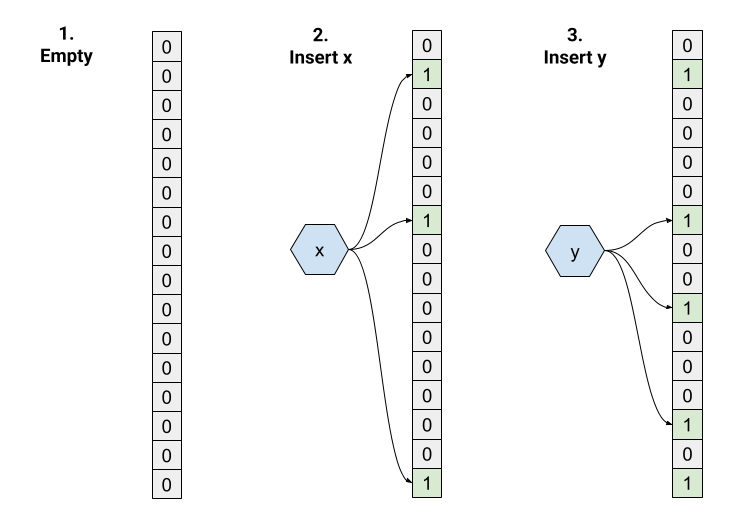
- 我们从一个空的 Bloom Filter 开始,其中
m=16和k=3。 所有位初始化为 0。 - 插入 "x"。 三个哈希函数返回索引 1、6、15,因此数组中的这些位设置为 1。
- 插入 "y"。 哈希函数返回索引 6、9 和 13,因此数组中的这些位设置为 1。 请注意,位 6 同时为 "x" 和 "y" 设置,这没问题。
接下来,让我们看一些成员资格测试:
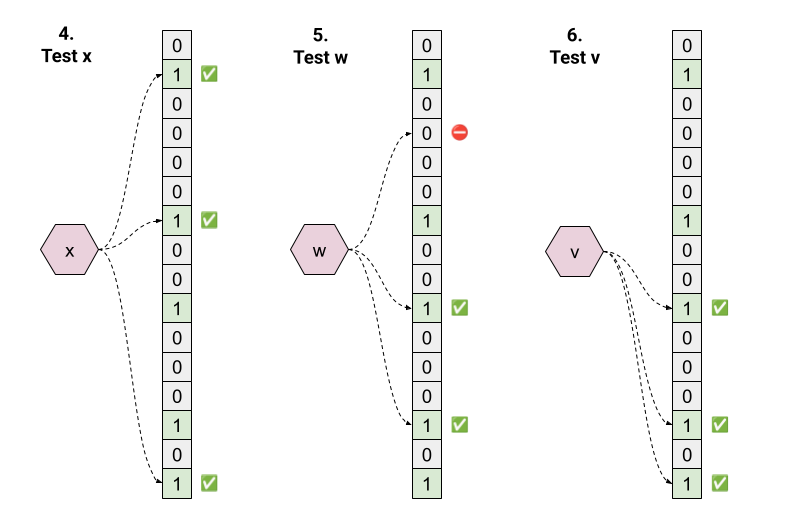
- 测试 "x"。 哈希函数返回 1、6、15; 数组中所有这些位都是 1,所以答案是 "true"。 这是一个真阳性。
- 测试 "w"。 哈希函数返回 3、9、13。 由于位置 3 处的位是 0,因此答案是 "false"。
- 测试 "v"。 哈希函数返回 9、13、15; 数组中所有这些位都是 1,所以答案是 "true"。 这是一个假阳性。
请注意,通过反证法很容易证明,Bloom Filter 的测试操作返回的所有 "false" 答案都是真阴性。
实现
以下是 Go 中 Bloom Filter 的一个简单实现:
// New creates a new BloomFilter with capacity m, using k hash functions.
// You can calculate m and k from the number of elements you expect the
// filter to hold and the desired error rate using CalculateParams.
funcNew(muint64,kuint64)*BloomFilter{
return&BloomFilter{
m:m,
k:k,
bitset:newBitset(m),
seed1:maphash.MakeSeed(),
seed2:maphash.MakeSeed(),
}
}
typeBloomFilterstruct{
muint64
kuint64
bitset[]uint64
// seeds for the double hashing scheme.
seed1,seed2maphash.Seed
}
// Insert a data item into the bloom filter.
func(bf*BloomFilter)Insert(data[]byte){
h1:=maphash.Bytes(bf.seed1,data)
h2:=maphash.Bytes(bf.seed2,data)
fori:=rangebf.k{
loc:=(h1+i*h2)%bf.m
bitsetSet(bf.bitset,loc)
}
}
// Test if the given data item is in the bloom filter. If Test returns false,
// it's guaranteed that data was never added to the filter. If it returns true,
// there's an eps probability of this being a false positive. eps depends on
// the parameters the filter was created with (see CalculateParams).
func(bf*BloomFilter)Test(data[]byte)bool{
h1:=maphash.Bytes(bf.seed1,data)
h2:=maphash.Bytes(bf.seed2,data)
fori:=rangebf.k{
loc:=(h1+i*h2)%bf.m
if!bitsetTest(bf.bitset,loc){
returnfalse
}
}
returntrue
}
bitsetSet 和 bitsetTest 函数可以在完整的代码仓库中找到。
此实现使用 double hashing,仅通过两个哈希函数生成 k 个不同的哈希函数。
代码还提到了 CalculateParams 函数:
// CalculateParams calculates optimal parameters for a Bloom filter that's
// intended to contain n elements with error (false positive) rate eps.
funcCalculateParams(nuint64,epsfloat64)(muint64,kuint64){
// The formulae we derived are:
// (m/n) = -ln(eps)/(ln(2)*ln(2))
// k = (m/n)ln(2)
ln2:=math.Log(2)
mdivn:=-math.Log(eps)/(ln2*ln2)
m=uint64(math.Ceil(float64(n)*mdivn))
k=uint64(math.Ceil(mdivn*ln2))
return
}
您需要阅读 Math 附录才能理解其工作原理。
实用性
让我们看一个现实的 Bloom Filter 及其性能的实际例子。 假设我们想要存储大约 10 亿个元素,并且假阳性率为 1%(这意味着如果过滤器为测试返回 "true",则有 99% 的几率该元素之前已添加到过滤器)。 使用这些要求,我们可以调用 CalculateParams 来获取 Bloom Filter 参数:
CalculateParams(1000000000, 0.01) ===> (9585058378 7)
这意味着 m 大约是 96 亿(位),k 是 7。换句话说,我们的 Bloom Filter 需要大约 1.2 GB 的空间来缓存十亿个元素(可以是任意大小)的成员资格测试。 此外,查找速度非常快 - 只是 7 次哈希函数的应用。 恒定的查找成本特别有吸引力,因为它不取决于实际插入的元素数量,也不取决于数据的任何特定模式(即,没有渐近成本更高的最坏情况)。
在我的机器上,使用上面显示的 Go 实现进行基准测试,我得到每个查找大约 ~30 纳秒。 请注意,这是我可以想到的最简单的 Go 实现 - 这里没有任何优化; 我确信可以通过使用更优化的哈希实现(例如)将其提高至少 2 倍。
现在想象一下,即使文件包含用于快速查找的适当索引,确定数据是否存在于具有 10 亿个条目的文件中需要多长时间。 仅仅要求操作系统读取文件的前几个 KiB 以获取索引将比 30 纳秒花费更长的时间。
回想一下,Bloom Filter 最适合于 "待测试消息的绝大多数不属于给定集合" 的情况。 此外,即使数据存在于文件中,假阳性也仅在 1% 的时间内发生。 因此,我们必须去磁盘只是为了发现数据不存在的次数只是总访问次数的很小一部分。
代码
此帖子的完整代码以及测试可在 GitHub 上找到。
附录:Bloom Filter 背后的数学原理
符号提醒:
- m:集合的大小(以位为单位)
- n:插入到过滤器中的 key 的数量
- k:用于插入/测试每个 key 的哈希函数的数量
对于集合中的特定位,假设我们的哈希函数随机分布 key,则它未被特定哈希函数设置的概率为:
\[p_0=1-\frac{1}{m}\]
并且它未被我们的 k 个哈希函数中的任何一个设置的概率为:
\[p_0=\left ( 1-\frac{1}{m}\right )^k=\left( \left ( 1-\frac{1}{m}\right )^m\right)^\frac{k}{m}\]
构造最后一个公式是为了使用 e^x 的近似值对于足够大的 m (请参见 此帖子中的附录) 来写:
\[p_0\approx e^{-\frac{k}{m}}\]
插入 n 个元素后,它为 0 的概率为:
\[p_0\approx e^{-\frac{kn}{m}}\]
这意味着它为 1 的概率为:
\[p_1\approx 1-e^{-\frac{kn}{m}}\]
回顾:这是在将 n 位插入大小为 m 的集合中且具有 k 个不同哈希函数之后,任何给定位为 1 的概率。
假设我们的哈希函数之间是独立的(这不是很严格,但在实践中是一个合理的假设),让我们计算假阳性率。 假设我们有一个不在集合中的新 key,并且我们正在尝试通过使用我们的 k 个哈希函数对其进行哈希来检查其成员资格。 假阳性率是所有哈希都落在已设置为 1 的位上的概率:
\[p_{fp}\approx\left ( 1-e^{-\frac{kn}{m}} \right )^k\approx \varepsilon\]
这也称为过滤器的_错误率_,或 \varepsilon。 为了获得最佳(最小)假阳性率,让我们最小化 \varepsilon。 由于对数函数是单调递增的,因此最小化 \ln(\varepsilon) 会更方便:
\[ln(\varepsilon)=\ln\left ( 1-e^{-\frac{kn}{m}} \right )^k=k\cdot \ln\left ( 1-e^{-\frac{kn}{m}} \right )\]
我们将计算 w.r.t. k 的导数并将其设置为 0:
\[\begin{aligned} \frac{d}{dk}ln(\varepsilon)&=\frac{d}{dk}k\cdot \ln\left ( 1-e^{-\frac{kn}{m}} \right )\\ &=\ln\left ( 1-e^{-\frac{kn}{m}} \right ) + k\frac{e^{-\frac{kn}{m}}\cdot \frac{n}{m}}{1-e^{-\frac{kn}{m}}} \end{aligned}\]
替换变量 t=e^{-\frac{kn}{m}} 并使用更多微积分和代数,我们可以发现:
\[k= \frac{m}{n}\cdot \ln(2)\]
一个数值例子:如果我们有一个包含 100 万位的集合,并且我们期望插入大约 100,000 个元素,则最佳哈希函数数为:
\[k= 10\cdot \ln(2)= 6.93 \approx 7\]
但是,针对某个错误率进行优化并相应地设置过滤器参数更有用。 让我们假设我们将使用 k 的这个最佳值。 将 k= \frac{m}{n}\cdot \ln(2) 替换为上面 \varepsilon 的等式:
\[\begin{aligned} \varepsilon&\approx \left ( 1-e^{-\frac{n}{m}\cdot{\frac{m}{n}\cdot \ln 2}} \right )^{\frac{m}{n}\cdot \ln 2}\\ &\approx \left ( 1-e^{-\ln 2} \right )^{\frac{m}{n}\cdot \ln 2}\\ &\approx \left ( \frac{1}{2} \right )^{\frac{m}{n}\cdot \ln 2}\\ \end{aligned}\]
如果我们使用之前的数值示例,其中 \frac{m}{n}=10,则具有最佳 k 的错误率将为 0.5^{6.93}\approx 0.8%。
通常发生的情况是,我们心中有一个错误率,并且我们想计算每个元素要分配多少位。 让我们使用先前的等式,并尝试使用对数将其中的 \frac{m}{n} 隔离:
\[\ln \varepsilon\approx \frac{m}{n}\cdot \ln 2 \cdot \ln 2^{-1}=-\frac{m}{n}\ln^2(2)\]
然后:
\[\frac{m}{n}\approx -\frac{\ln \varepsilon}{\ln^2(2)}\]
最终的数值示例:假设我们希望错误(假阳性)率为 1%。 这意味着我们的集合应该有:
\[\frac{m}{n}\approx -\frac{\ln 0.01}{\ln^2 (2)}=9.58\]
... 每个元素的位数。 因此,如果我们期望大约有 100,000 个元素,则用于过滤器的位集应至少包含 958,000 位。 并且,如先前计算的那样,我们应该使用 k=7 个哈希函数来实现此最佳错误率。
[1]| 因此,Bloom Filter 在数据存储系统中非常常见。 这是 关于 Cassandra 的讨论,但还有很多其他的。 ---|--- 如有意见,请给我发送电子邮件。 © 2003-2025 Eli Bendersky 回到顶部