对齐并非免费午餐:模型升级如何让你的置信度信号失效
![]() Products
Products
Autonomous InvestigationsPolicy Management & Real-time Regulations DatabaseAI Threat Hunting
Solutions
Industry
Content PlatformsMarketplacesFinancial Services
Use Case
Trust & SafetyPhysical SafetyInsider Threat
Resources
Resources
BlogContact
Featured
Intrinsic is becoming Variance
Products
Products
Autonomous InvestigationsPolicy Management & Real-time Regulations DatabaseAI Threat Hunting
Solutions
Industry
Content PlatformsMarketplacesFinancial Services
Use Case
Trust & SafetyPhysical SafetyInsider Threat
Resources
Resources
BlogContact
Featured
Intrinsic is becoming Variance →
Company
Company
AboutCareers
Join Variance
→
Company
Company
AboutCareers
Join Variance
 View open positions→
Login
Get Started
→
Date
April 29, 2025
Authors
Michael Lin
Share
Engineering
View open positions→
Login
Get Started
→
Date
April 29, 2025
Authors
Michael Lin
Share
Engineering
对齐并非免费午餐:模型升级如何让你的置信度信号失效

扁平化的校准曲线
在大型语言模型(LLM)的训练后处理中,当模型遇到违反其训练后安全准则的内容时,可能会出现行为偏差。正如OpenAI的GPT-4系统卡片中所提到的,模型校准很少能在训练后幸存,导致模型即使在错误时也表现得非常自信。¹ 在我们的使用场景中,我们经常看到这种行为会导致语言模型的输出偏向违规内容,从而导致在使用LLM驱动的内容审核系统中,人工审核人员浪费审核时间。
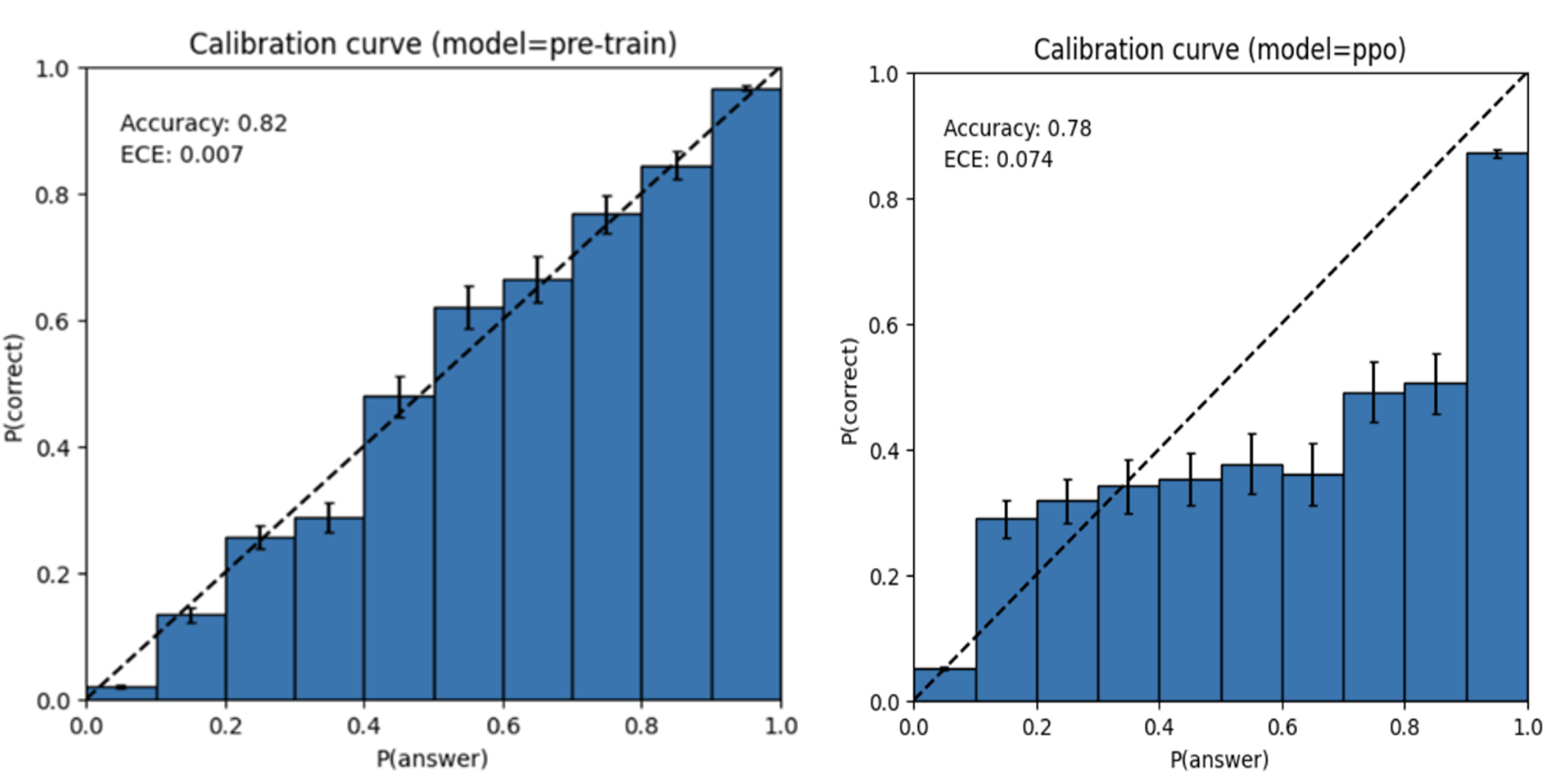 预训练与后偏好优化校准曲线
预训练与后偏好优化校准曲线
GPT-4o 上的有效信号
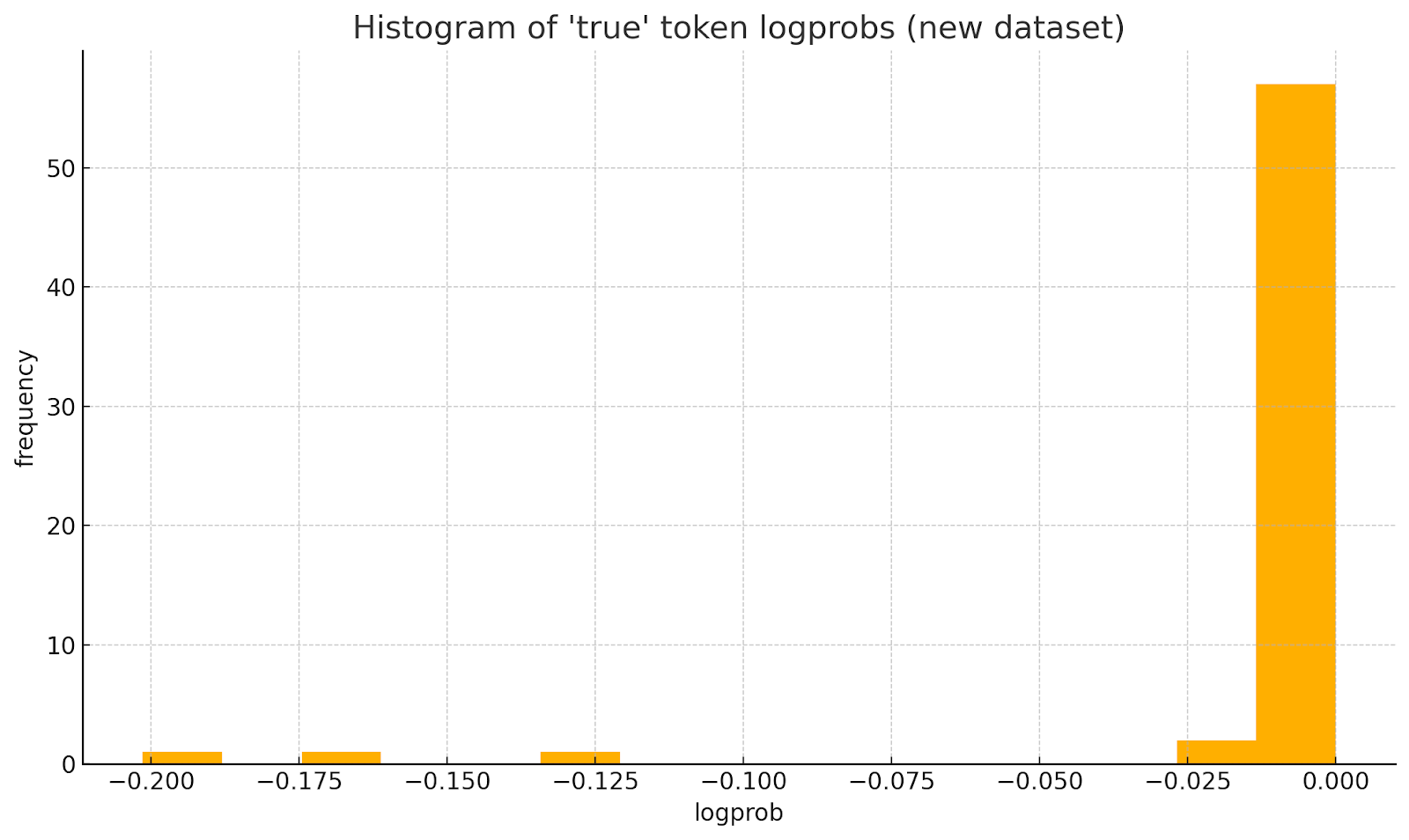
以下是从针对 GPT-4o 的误报黄金数据集中采样的 log probs 直方图。我们可以看到,几乎所有输出的 log p≈0 nats(概率 ≈ 1),表明此数据集中存在真实的违规行为。
但是,此数据集中存在一些异常值,几乎所有这些异常值都对应于我们在数据集中观察到的行为模式,即我们的模型会偏离正式的基础策略定义,或者内容或策略违规中出现幻觉。
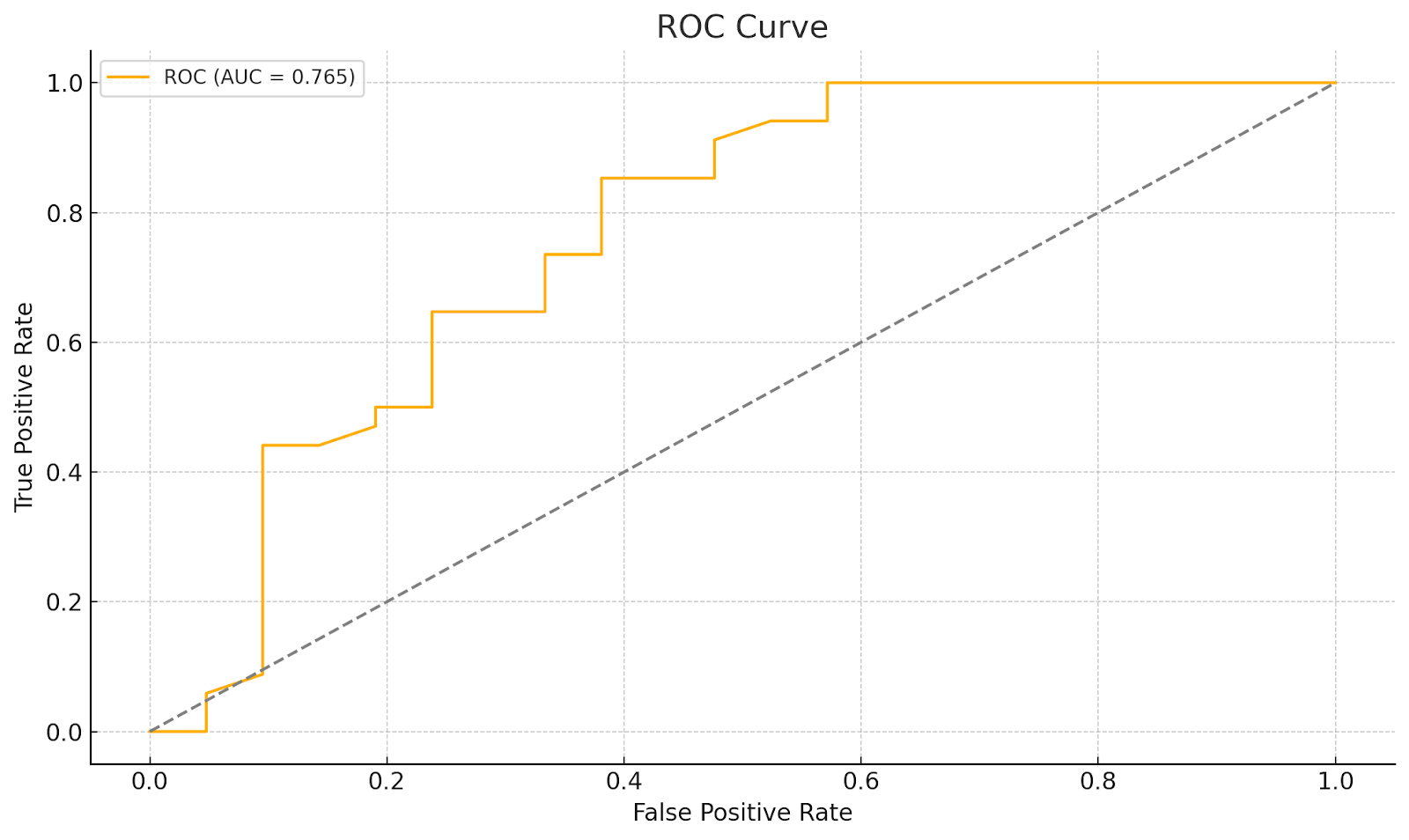 GPT-4o 中的功能性置信度信号
GPT-4o 中的功能性置信度信号
这产生了一个功能性足够的 ROC 曲线,有助于校准我们的模型以忽略这些输出,并执行诸如标记内容以供审核或抑制输出(可能为虚假输出)之类的任务。
升级导致的不确定性消失
然而,我们发现,在切换到 GPT-4.1-mini 之后,此信号消失了。尽管我们仍然能够测量结构化输出中其他 token 的 log probs,但每个 token 都 100% 确信它应该在此数据集中返回 true,这完全破坏了我们的信号。
为什么同一模型家族的较小版本会抹去如此多的信息? 可能是由于对 4-1 mini 进行的大量知识蒸馏,以便进行二元决策(例如在结构化输出中输出布尔字段),因此该维度完全崩溃了:学生被教导发出正确的答案并忽略熵。 这导致没有可用的置信度信号。
我们尝试了几种其他方法来恢复丢失的不确定性信号,但都失败了:
- 熵差分假设:我们测量了内容数组与思维链均值之间的熵,其理论是幻觉违规会更加冗长/不那么自信。 实际上,我们无法在此处找到信号。
- Span 一致性检查:我们分析了 span log-probs 的标准偏差,希望在真/假案例之间找到差异。 实际上,两个类的 σ≈0.018(相同)。
- Perplexity 分析:我们计算了所有样本的 token 级别 perplexity 平均值。 实际上,我们发现每个样本(安全或不安全)的指标都相似。
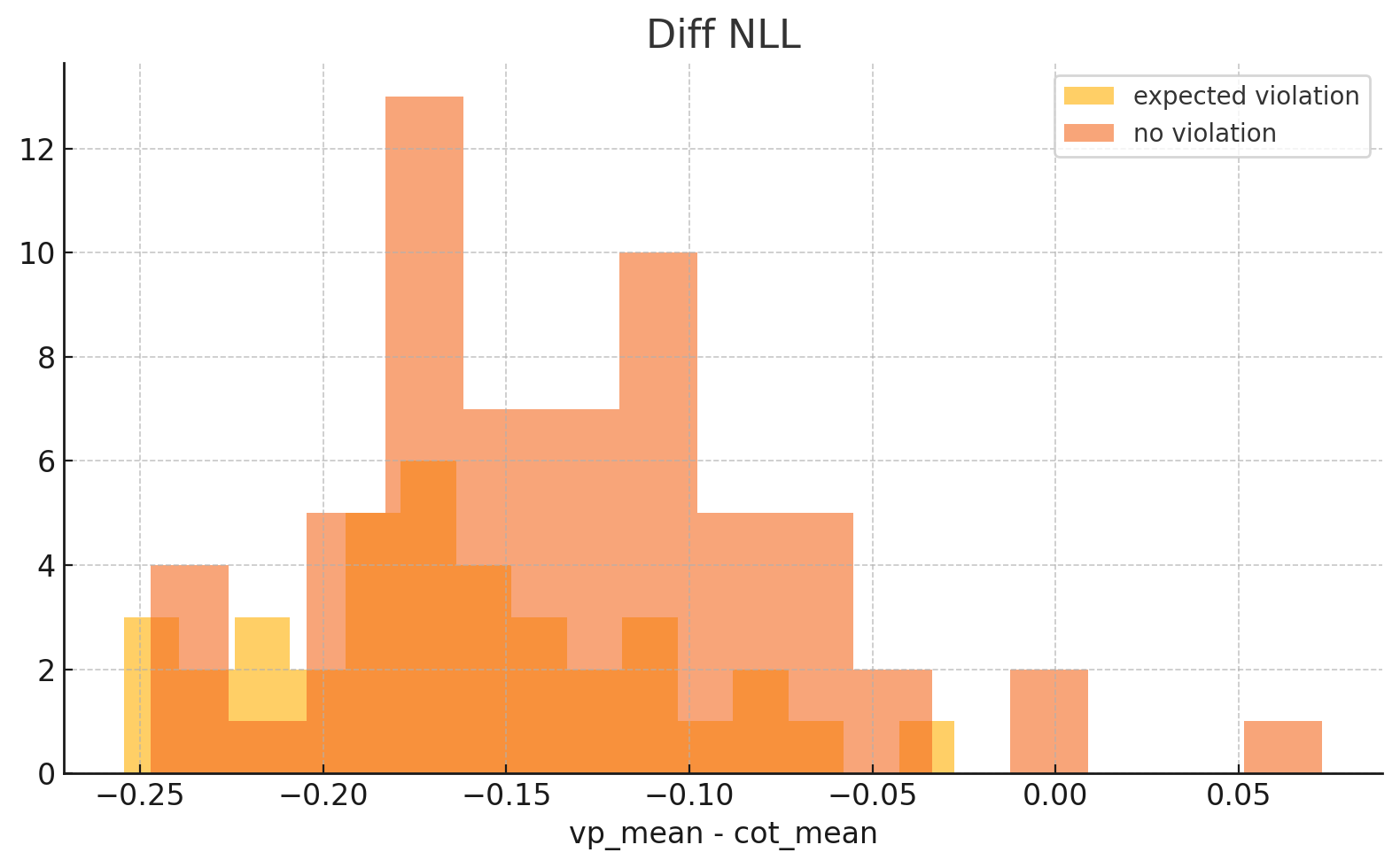
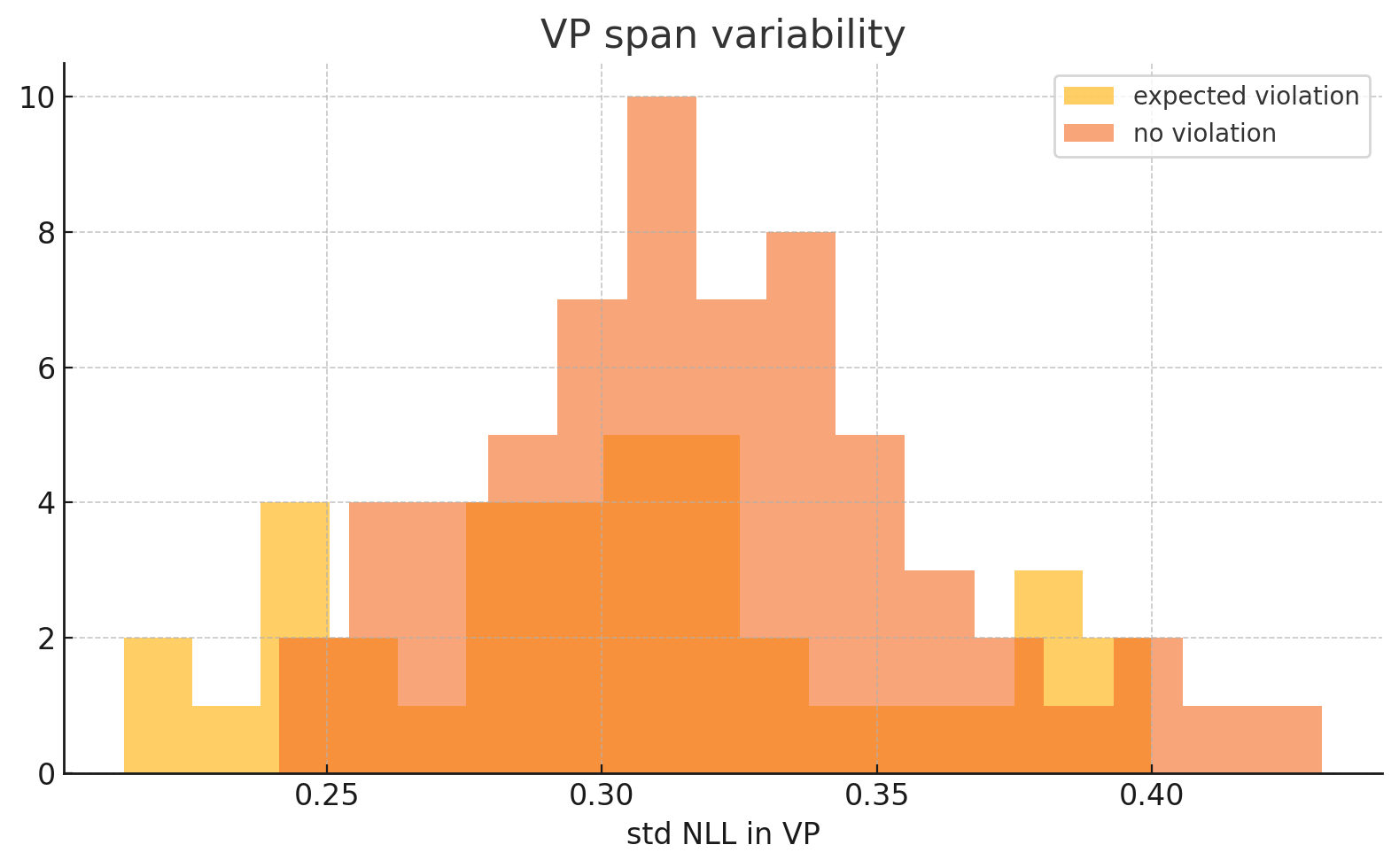
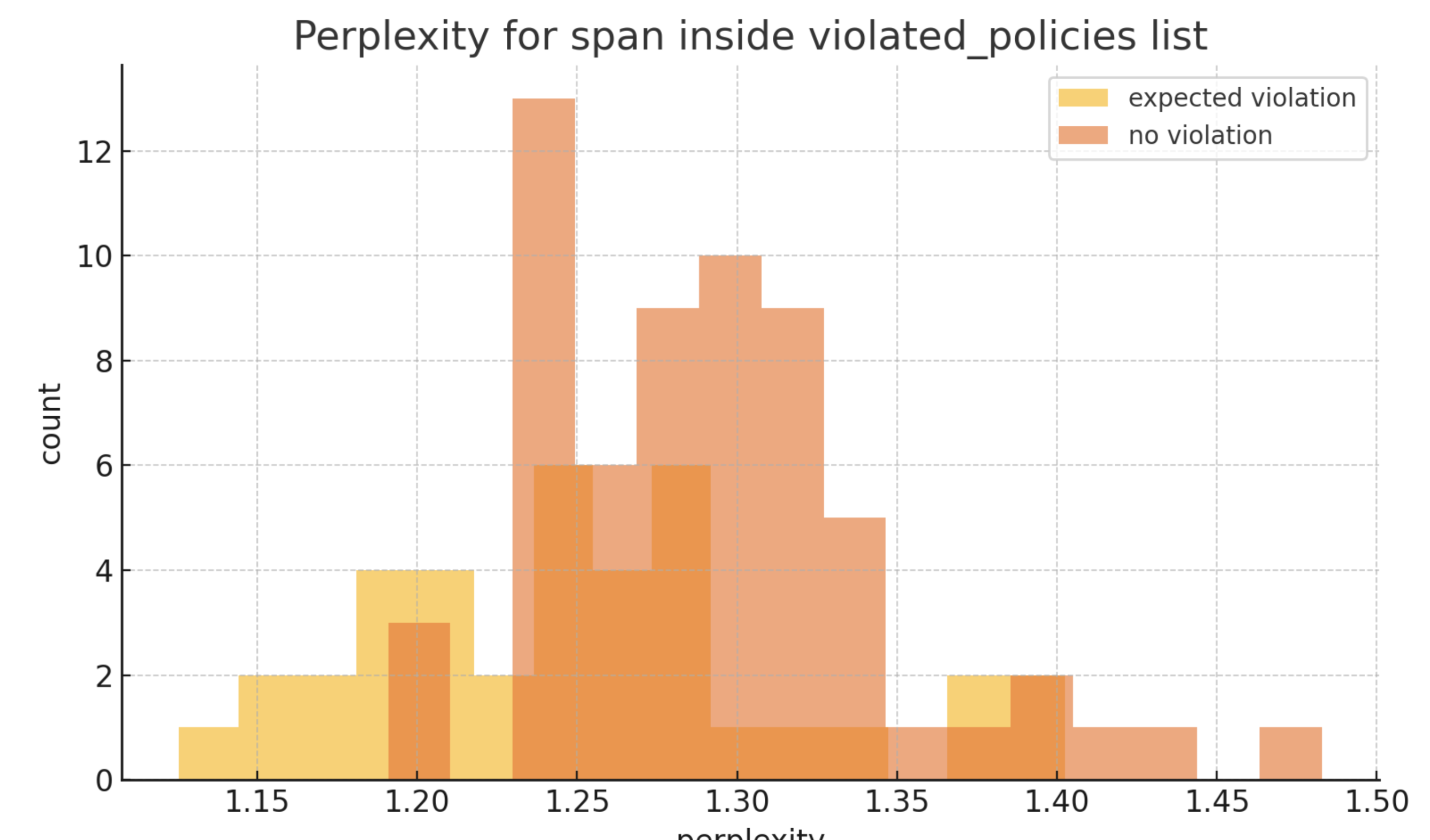 在 GPT-4.1-mini 中恢复不确定性信号的失败尝试
在 GPT-4.1-mini 中恢复不确定性信号的失败尝试
最终结果是,我们失去了幻觉的信号! 所有这些功能都依赖于局部熵在 RLHF 中幸存下来,并且我们没有可以寻找这些信号的地方,因此需要新的模型升级启发式方法来解决这些故障案例,以重新引入一些不确定性度量。
为了应对这种丢失的幻觉信号,我们实施了几种替代的安全措施。 这些新方法(例如正式要求策略解释完全基于实际数据/引言)正在推动我们产品中的新功能,从而实现更好的可解释性和策略迭代,但确实表明模型升级不仅仅是基准升级。
我们目前的方法依赖于更明确的控制:要求模型针对每个策略违规行为提供详细的解释,要求特定的策略引用来支持决策,以及实施过滤系统以捕获策略出现幻觉时损坏的输出。
但是,这些模型的闭源性质极大地限制了我们对 log probabilities 之外的内部信号的访问。 随着模型为了提高效率而不断被进一步提炼,即使是这些有限的信号也在消失,这给可靠的不确定性检测带来了越来越大的挑战,尤其是在使用闭源模型时。
对齐并非免费午餐
在我们的情况下,4.1 的可操纵性和性能升级的改进对于客户来说是值得的,并且我们的内部解决方法足以通过我们最新的版本实际提高精度。 模型升级不仅仅是简单的性能提升; 它是一种分布偏移,可能会使整个 AI 堆栈失效。 任何交付高精度系统的人都应该记录原始 logits、将启发式方法与特定模型版本联系起来,并投资于替代产品安全措施。 对齐使模型对用户来说更安全,但同时也会对工程师隐藏其自身的不确定性; 重新暴露这种不确定性的负担落在了我们身上。
- OpenAI GPT‑4 System Card, § 6.2 “Calibration”: “我们观察到 RLHF 提高了 helpfulness 但可能会扭曲模型的概率估计;对齐后,模型往往对正确和错误的答案都过于自信。
Monitor. Respond. Prevail.
with Variance
Get Started
→
 Products
Autonomous InvestigationsPolicy ManagementAI Threat Hunting
Solutions
Trust & SafetyPhysical SafetyInsider Threat
Resources
AboutCareersBlogContactStatus
Social
X/TwitterLinkedin
© 2025 Decoy Technologies Inc. All rights reserved.
Privacy PolicyTerms of Use
Products
Autonomous InvestigationsPolicy ManagementAI Threat Hunting
Solutions
Trust & SafetyPhysical SafetyInsider Threat
Resources
AboutCareersBlogContactStatus
Social
X/TwitterLinkedin
© 2025 Decoy Technologies Inc. All rights reserved.
Privacy PolicyTerms of Use