Jargonic 刷新日语 ASR 的 SOTA 纪录
Jargonic 为日语 ASR 设立新标准
日本語で話そう。Jargonic is ready.
自动语音识别(ASR)系统通常在实验室条件下表现出色,但在实际的企业环境中却表现不佳,尤其是在像日语这样语言结构复杂的语言中。与英语不同,日语不使用空格(句子中单词之间的空格)来分隔单词,因此词错误率(WER)作为基准的相关性较低。相反,字符错误率(CER)成为评估转录质量的主要指标。
最重要的是,日语融合了三种不同的书写系统——平假名、片假名和汉字——,拥有数百种敬语结构,并且发音会根据语境而变化。例如,“三”这个词在指人、扁平物体或动物时发音不同。再加上密集的特定领域术语,这些复杂性使日语成为 ASR 难以掌握的最具挑战性的语言之一。随着 Jargonic V2 的发布,aiOla 将继续突破这些障碍。
在为英语、西班牙语、法语等语言设置了新基准之后,Jargonic V2 现在也在日语方面处于领先地位——不仅提供卓越的转录准确性,还在制造业、物流、医疗保健和金融等行业中提供无与伦比的专业术语召回率。
超越转录:为什么术语召回很重要
如今,大多数 ASR 模型都是“通用抄写员”——经过广泛的转录准确性训练,但不适合识别实际企业环境中发现的缩写、产品名称和技术术语。这就是 Jargonic 与众不同的地方。
我们专有的 Keyword Spotting (KWS) 技术使 Jargonic 能够识别特定领域的术语,而无需重新训练或手动管理的词汇列表。与传统模型在遇到利基或行业特定词汇时可能会出错不同,Jargonic 可以实时检测到它们——这要归功于深度集成到 ASR 管道中的上下文感知、零样本学习机制。
基准测试结果:Jargonic vs. 业界
我们在两个日语数据集上测试了 Jargonic V2(两者都包含所有三个主要的日语脚本:汉字、平假名和片假名):
- CommonVoice v.13 – 一个测试通用语音识别功能的标准数据集。
- ReazonSpeech – 从地面电视流收集的各种自然日语语音集。
在两个数据集中,Jargonic 在关键领域都优于 Whisper v3、ElevenLabs、Deepgram 和 AssemblyAI:
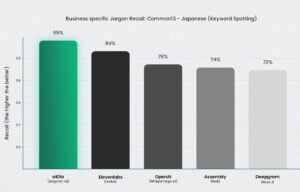
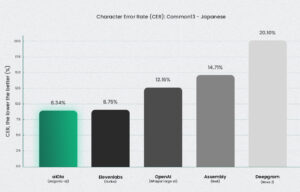
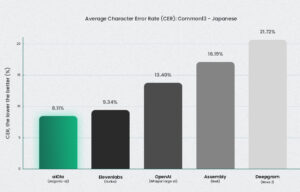
Jargonic 对特定领域的日语术语的召回率达到了 94.7%——这意味着它几乎正确地检测到了所有专业术语,而无需训练。没有其他模型能与之匹敌。
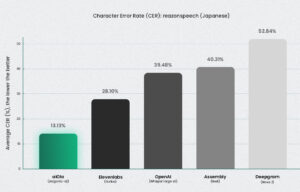
即使在自然、非结构化的日语语音(Reazon 数据集)中,Jargonic 的表现也优于所有其他模型——将字符错误率 (CER) 降低了一半甚至更多。
为现实世界而生
这些结果不仅仅是学术上的。它们突出了在多语言、术语密集型环境中运营的企业的一项基本能力:能够从口语互动中捕获准确、结构化的数据——无论语言、上下文或复杂性如何。
借助 Jargonic,语音成为企业 AI 的可靠界面——不仅用于转录,还用于实时理解和行动。