使用 SIMD 在 AMD 9950X 上实现 21 GB/s 的 CSV 解析
nietras
编程、机械共鸣、机器学习和 .NET ❤. 博客 Sep (世界上最快的 .NET CSV 解析器) 关于
Sep 0.10.0 - 在 AMD 9950X 上使用 SIMD 实现 21 GB/s 的 CSV 解析 🚀
Sep 0.10.0 于 2025 年 4 月 22 日发布,针对支持 AVX-512 的 CPU 进行了优化,例如 AMD 9950X (Zen 5),并更新了基准测试,包括 9950X。现在,Sep 在 9950X 上实现了惊人的 21 GB/s 的低级 CSV 解析速度。🚀 在 0.10.0 之前,Sep 在 9950X 上的速度约为 18 GB/s。
有关此版本的所有更改,请参阅 v0.10.0 release,有关完整详细信息,请参阅 GitHub 上的 Sep README。
在这篇博文中,我将深入探讨 .NET 9.0 为 AVX-512 生成的机器码如何次优,以及为了绕过这个问题并加速 Sep 对 AVX-512 的支持所做的更改,沿途展示有趣的代码和汇编。准备好迎接 SIMD C# 代码、x64 SIMD 汇编和大量的基准测试数字吧。
然而,首先让我们来看看 Sep 的性能从早期的 0.1.0 到 0.10.0,从 .NET 7.0 到 .NET 9.0,以及从 AMD Ryzen 9 5950X (Zen 3) 到 9950X (Zen 5) 的演变,因为我最近也升级了我的工作电脑。
Sep 性能演变
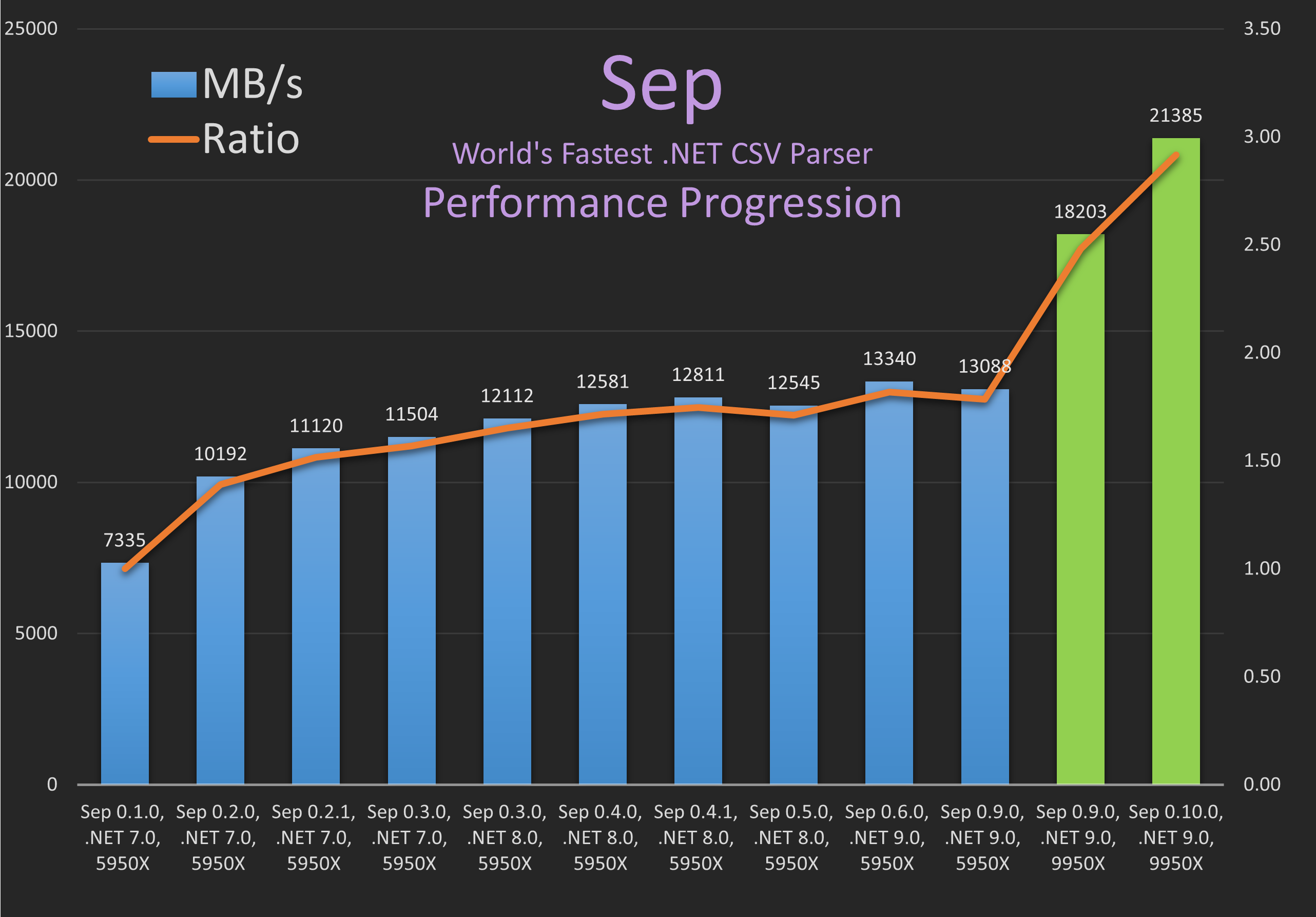
上面的基准测试数字适用于 package assets CSV 数据和底层解析 Rows only scope,有关详细信息,请参阅 GitHub 上的 Sep README 或 GitHub 上的代码。请注意,这里的所有数字都是单线程的,并且也显示在下表中。请注意,数字可能存在几个百分点的差异,因此对于给定的版本,Sep 可能会出现轻微的倒退。
主要的收获是,Sep 的性能得到了逐步提升,这得益于主要(例如,0.2.0 中内部结构的几乎完全重写)和次要的代码更改。同时,在新版本的 .NET 上也看到了性能的提高。最后,这里展示了从 AMD 5950X (Zen 3) 到 AMD 9950X (Zen 5) 的改进。因此,这展示了软件与硬件的改进如何将性能提升到新的水平。
我们可以看到 Sep 的进展:
~ 7 GB/s(0.1.0, 5950X 和 .NET 7.0)~12 GB/s(0.3.0, 5950X 和 .NET 8.0)~13 GB/s(0.6.0, 5950X 和 .NET 9.0)~18 GB/s(0.9.0, 9950X 和 .NET 9.0)~21 GB/s(0.10.0, 9950X 和 .NET 9.0)
自从 Sep 于 2023 年 6 月推出 以来,在不到 2 年的时间里,这是一个惊人的 ~3 倍 的改进。
Sep | .NET | CPU | Rows | Mean [ms] | MB | MB/s | Ratio | ns/row
---|---|---|---|---|---|---|---|---
0.1.0 | 7.0 | 5950X | 1000000 | 79.590 | 583 | 7335.3 | 1.00 | 79.6
0.2.0 | 7.0 | 5950X | 1000000 | 57.280 | 583 | 10191.6 | 1.39 | 57.3
0.2.1 | 7.0 | 5950X | 50000 | 2.624 | 29 | 11120.2 | 1.52 | 52.5
0.3.0 | 7.0 | 5950X | 50000 | 2.537 | 29 | 11503.7 | 1.57 | 50.7
0.3.0 | 8.0 | 5950X | 50000 | 2.409 | 29 | 12111.6 | 1.65 | 48.2
0.4.0 | 8.0 | 5950X | 50000 | 2.319 | 29 | 12581.3 | 1.72 | 46.4
0.4.1 | 8.0 | 5950X | 50000 | 2.278 | 29 | 12811.2 | 1.75 | 45.6
0.5.0 | 8.0 | 5950X | 50000 | 2.326 | 29 | 12544.5 | 1.71 | 46.5
0.6.0 | 9.0 | 5950X | 50000 | 2.188 | 29 | 13339.9 | 1.82 | 43.8
0.9.0 | 9.0 | 5950X | 50000 | 2.230 | 29 | 13088.4 | 1.78 | 44.6
0.9.0 | 9.0 | 9950X | 50000 | 1.603 | 29 | 18202.7 | 2.48 | 32.1
0.10.0 | 9.0 | 9950X | 50000 | 1.365 | 29 | 21384.9 | 2.92 | 27.3
从 5950X w. Sep 0.9.0 到 9950X w. Sep 0.10.0 的改进是 ~1.6 倍,这是从 Zen 3 到 Zen 5 的一个相当不错的改进。请注意,9950X 的加速频率为 5.7 GHz,而 5950X 的加速频率为 4.9 GHz,因此仅此一项可能就解释了 1.2 倍。
AVX-512 代码生成和 Mask 寄存器问题
Sep 自 0.2.3 以来就支持 AVX-512,当时我注意到:
这里的不同之处在于使用了 mask 寄存器 (
k1-k8),它是随着 AVX-512 引入的。但是,.NET 8 没有对这些寄存器的显式支持,并且代码生成有点次优,因为 mask 寄存器每次都会被移动到普通寄存器。然后再移回来。
当时我没有直接访问支持 AVX-512 的 CPU,所以我无法详细测试 AVX-512 的性能,但我确实在 Xeon Silver 4316 上进行了验证,根据一些快速测试,尽管存在 mask 寄存器的问题,但 AVX-512 解析器在该 CPU 上速度最快。
9950X 升级和 AVX-512 与 AVX2 性能
最近,我从 AMD 5950X (Zen 3) CPU 升级到 AMD 9950X (Zen 5) CPU。Zen 3 不支持 AVX-512,但 Zen 5 支持。在新 CPU 上做的第一件事当然是运行 Sep 基准测试,结果表明,Sep 在 9950X 上实现了约 18 GB/s 的低级 CSV 文件解析速度。这很棒,比 5950X 快约 1.4 倍。这是从 Zen 3 到 Zen 5 的一个相当不错的改进。
但是,我仍然想将 AVX-512 与 AVX2 进行比较。Sep 具有非官方的支持,可以通过环境变量覆盖默认选择的解析器。这也用于全面测试所有可能的解析器,无论选择哪个解析器作为最佳解析器。令人惊讶的是,9950X 上的 AVX2 解析器达到了约 20GB/s!也就是说,它比基于 AVX-512 的解析器快约 10%,这对于 Sep 来说非常重要。因此,mask 寄存器问题似乎仍然存在。
解析器代码/汇编比较和新的 AVX-512-to-256 解析器
让我们检查一下基于 AVX-512 的解析器 (0.9.0) 的代码和汇编(通过 Disasmo),一个调整后的版本 (0.10.0),将其与基于 AVX2 的解析器进行比较,最后回顾一下一个新的基于 AVX-512-to-256 的解析器,它绕过了 mask 寄存器问题,并且比基于 AVX2 的解析器更快,如上所示达到了约 21 GB/s。
Parse 方法
Sep 中的所有解析器都遵循相同的基本布局,如下所示,并且具有一个通用的 Parse 方法,用于支持在处理引号时 (ParseColInfos) 和不处理引号时 (ParseColEnds) 的解析。前者需要跟踪更多状态,并且速度稍慢。
在 Sep 中,Parse 方法标记为 AggressiveInlining,以确保它被内联,这意味着原则上可以在安装了 Disasmo 的 Visual Studio 中转到 ParseColEnds 并点击 ALT + SHIFT + D。不幸的是,由于某种原因,除非将解析器从 class 更改为 struct,否则这目前不起作用。因此,读者如果想跟着一起操作,请注意。有关更多信息,请参阅 GitHub 问题 Empty disassembly for method with inlined generic method (used to work)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| ```
public void ParseColEnds(SepReaderState s)
{
Parse<int, SepColEndMethods>(s);
}
public void ParseColInfos(SepReaderState s)
{
Parse<SepColInfo, SepColInfoMethods>(s);
}
void Parse<TColInfo, TColInfoMethods>(SepReaderState s)
where TColInfo : unmanaged
where TColInfoMethods : ISepColInfoMethods<TColInfo>
{
// Implementation
}
---|---
`
总而言之,Sep 中的解析是在一个 `char` 的 span 上完成的(来自一个数组),例如 16K,并输出该 span 的一组列结束索引和行列计数。这确保了对 CPU 缓存中可以容纳的足够小但重要的数据块进行解析,并且也有助于之后进行高效的多线程处理。
然后,span 的解析基本上只是一个循环,其中加载一个或两个 SIMD 寄存器(例如 `Vector256`)(作为无符号 16 位整数,例如 `ushort`),并将其转换为 `byte` SIMD 寄存器,然后使用 SIMD 比较指令将其与特殊字符(例如 `\n`、`\r`、`"`、`;`)进行比较。然后将比较结果转换为位掩码,并且之后依次解析该掩码中的每个设置位。
这里有趣的部分是 SIMD 代码以及它如何在 .NET 上 JIT 编译成机器码,以及它的效率如何。下面显示了前面提到的解析器的这个特定代码和汇编。
### `SepParserAvx512PackCmpOrMoveMaskTzcnt.cs` (0.9.0)
下面代码片段的分解:
1. **数据加载和打包** :
* 使用未对齐的读取从内存中读取两个 16 位整数向量(`v0` 和 `v1`)。
* 使用 `PackUnsignedSaturate` 将这些向量打包成一个字节向量,确保值在字节范围内。
* 对于 AVX-512,这意味着加载两个 512 位 SIMD 寄存器,每个寄存器有 32 个 `char`,然后将其打包成具有 64 个字节的单个 512 位 SIMD 寄存器。这意味着在每个循环中处理 64 个 `char`。
2. **重新排序打包的数据** :
* 打包的数据是交错的,因此应用一个排列操作 (`PermuteVar8x64`) 以将字节重新排序为正确的序列。
3. **字符比较** :
* 使用 SIMD 相等操作将字节向量与特定字符(例如 `\n`、`\r`、`"`、`;`)进行比较。这些比较识别与 CSV 解析相关的特殊字符。
4. **合并比较结果** :
* 使用逻辑运算合并比较结果。
5. **位掩码生成和检查** :
* `MoveMask` 操作从 SIMD 寄存器中提取一个位掩码,以便快速检查,如果未找到特殊字符,则跳过进一步的处理。
所有解析器都遵循相同的基本方法,因此后续将省略此描述。请注意,`ISA` 和 `Vec` 是别名,用于使不同的解析器更相似,这使得比较和维护不同的解析器更容易。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| ``` var v0 = ReadUnaligned(ref byteRef); var v1 = ReadUnaligned(ref Add(ref byteRef, VecUI8.Count)); var packed = ISA.PackUnsignedSaturate(v0, v1); // Pack interleaves the two vectors need to permute them back var permuteIndices = Vec.Create(0L, 2L, 4L, 6L, 1L, 3L, 5L, 7L); var bytes = ISA.PermuteVar8x64(packed.AsInt64(), permuteIndices).AsByte(); var nlsEq = Vec.Equals(bytes, nls); var crsEq = Vec.Equals(bytes, crs); var qtsEq = Vec.Equals(bytes, qts); var spsEq = Vec.Equals(bytes, sps); var lineEndings = nlsEq | crsEq; var lineEndingsSeparators = spsEq | lineEndings; var specialChars = lineEndingsSeparators | qtsEq; // Optimize for the case of no special character var specialCharMask = MoveMask(specialChars); if (specialCharMask != 0u)
---|---
`
下面显示了具有 AVX-512 支持的 64 位 CPU(例如 9950X)的汇编。这里最有趣的是,每个比较 Vec.Equals 最终都变成了两个指令 vpcmpeqb (compare equal bytes) 和 vpmovm2b (move mask to byte)。也就是说,有很多从 mask 寄存器(例如 k1)到普通 512 位寄存器(例如 zmm5)的来回移动。
请注意,C# 代码不直接处理向量 mask 寄存器。.NET 不支持这一点,因此 JIT 负责围绕此进行代码生成。不幸的是,在这里它做得不好,AVX-512 没有它应有的那么快。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| ```
mov edi, r9d
lea rdi, bword ptr [r10+2*rdi]
vmovups zmm4, zmmword ptr [rdi]
vpackuswb zmm4, zmm4, zmmword ptr [rdi+0x40]
vmovups zmm5, zmmword ptr [reloc @RWD00]
vpermq zmm4, zmm5, zmm4
vpcmpeqb k1, zmm4, zmm0
vpmovm2b zmm5, k1
vpcmpeqb k1, zmm4, zmm1
vpmovm2b zmm16, k1
vpcmpeqb k1, zmm4, zmm2
vpmovm2b zmm17, k1
vpcmpeqb k1, zmm4, zmm3
vpmovm2b zmm4, k1
vpternlogd zmm5, zmm4, zmm16, -2
vpord zmm16, zmm5, zmm17
vpmovb2m k1, zmm16
kmovq r15, k1
test r15, r15
je G_M000_IG03
vpmovb2m k1, zmm4
kmovq r13, k1
lea r12, [r15+r8]
cmp r13, r12
je G_M000_IG43
---|---
`
### `SepParserAvx512PackCmpOrMoveMaskTzcnt.cs` (0.10.0)
为了解决上述代码生成问题,在 Sep 0.10.0 中,我更改了基于 AVX-512 的解析器,方法是更早地移动 `MoveMask` 调用,以避免如下所示的整个 mask 寄存器来回移动。对于其他解析器,仅在必要时调用 `MoveMask`,以减少“happy”/skip 路径中的指令。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| ``` var v0 = ReadUnaligned(ref byteRef); var v1 = ReadUnaligned(ref Add(ref byteRef, VecUI8.Count)); var packed = ISA.PackUnsignedSaturate(v0, v1); // Pack interleaves the two vectors need to permute them back var permuteIndices = Vec.Create(0L, 2L, 4L, 6L, 1L, 3L, 5L, 7L); var bytes = ISA.PermuteVar8x64(packed.AsInt64(), permuteIndices).AsByte(); var nlsEq = MoveMask(Vec.Equals(bytes, nls)); var crsEq = MoveMask(Vec.Equals(bytes, crs)); var qtsEq = MoveMask(Vec.Equals(bytes, qts)); var spsEq = MoveMask(Vec.Equals(bytes, sps)); var lineEndings = nlsEq | crsEq; var lineEndingsSeparators = spsEq | lineEndings; var specialChars = lineEndingsSeparators | qtsEq; // Optimize for the case of no special character var specialCharMask = specialChars; if (specialCharMask != 0u)
---|---
`
如下所示,这大大改进了解析器的汇编。基本上,指令更少了。我们仍然要从 mask 寄存器转到普通寄存器,但至少只有一次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| ```
mov edi, r9d
lea rdi, bword ptr [r10+2*rdi]
vmovups zmm4, zmmword ptr [rdi]
vpackuswb zmm4, zmm4, zmmword ptr [rdi+0x40]
vmovups zmm5, zmmword ptr [reloc @RWD00]
vpermq zmm4, zmm5, zmm4
vpcmpeqb k1, zmm4, zmm0
kmovq r15, k1
vpcmpeqb k1, zmm4, zmm1
kmovq r13, k1
vpcmpeqb k1, zmm4, zmm2
kmovq r12, k1
vpcmpeqb k1, zmm4, zmm3
kmovq rcx, k1
or r15, rcx
or r15, r13
or r12, r15
je SHORT G_M000_IG03
mov r13, rcx
lea rcx, [r12+r8]
cmp r13, rcx
je G_M000_IG43
---|---
`
### `SepParserAvx2PackCmpOrMoveMaskTzcnt.cs` (0.10.0)
让我们将 AVX-512 与基于 AVX2 的解析器进行比较。下面显示了 C# 代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| ``` var v0 = ReadUnaligned(ref byteRef); var v1 = ReadUnaligned(ref Add(ref byteRef, VecUI8.Count)); var packed = ISA.PackUnsignedSaturate(v0, v1); // Pack interleaves the two vectors need to permute them back var bytes = ISA.Permute4x64(packed.AsInt64(), 0b_11_01_10_00).AsByte(); var nlsEq = Vec.Equals(bytes, nls); var crsEq = Vec.Equals(bytes, crs); var qtsEq = Vec.Equals(bytes, qts); var spsEq = Vec.Equals(bytes, sps); var lineEndings = nlsEq | crsEq; var lineEndingsSeparators = spsEq | lineEndings; var specialChars = lineEndingsSeparators | qtsEq; // Optimize for the case of no special character var specialCharMask = MoveMask(specialChars); if (specialCharMask != 0u)
---|---
`
但是,下面的汇编显然更简单,因为不涉及 mask 寄存器。这解释了为什么基于 AVX2 的解析器比旧的 (0.9.0) 基于 AVX-512 的解析器更快。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| ```
mov edi, r9d
lea rdi, bword ptr [r10+2*rdi]
vmovups ymm4, ymmword ptr [rdi]
vpackuswb ymm4, ymm4, ymmword ptr [rdi+0x20]
vpermq ymm4, ymm4, -40
vpcmpeqb ymm5, ymm4, ymm0
vpcmpeqb ymm6, ymm4, ymm1
vpcmpeqb ymm7, ymm4, ymm2
vpcmpeqb ymm4, ymm4, ymm3
vpternlogd ymm5, ymm4, ymm6, -2
vpor ymm6, ymm5, ymm7
vpmovmskb r15d, ymm6
mov r15d, r15d
test r15, r15
je SHORT G_M000_IG03
vpmovmskb r13d, ymm4
mov r13d, r13d
lea r12, [r15+r8]
cmp r13, r12
je G_M000_IG43
---|---
`
### `SepParserAvx512To256CmpOrMoveMaskTzcnt.cs` (0.10.0)
鉴于即使经过调整的基于 AVX-512 (0.10.0) 的解析器也存在 mask 寄存器的问题,我一直在想也许有一种更直接的方法可以做到这一点,然后在与 LLM 进行了一些搜索和无果的讨论后,我发现可以使用 AVX-512 指令加载 `char`,然后通过使用 `ConvertToVector256ByteWithSaturation` (`vpmovuswb`) 将 16 位饱和转换为 8 位字节,作为一个 256 位寄存器,避免了 512 位 mask 寄存器,如下所示。这“仅”一次解析 32 个 `char`,但它更简单,并且避免了 mask 寄存器问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ``` var v = ReadUnaligned(ref byteRef); var bytes = ISA.ConvertToVector256ByteWithSaturation(v); var nlsEq = Vec.Equals(bytes, nls); var crsEq = Vec.Equals(bytes, crs); var qtsEq = Vec.Equals(bytes, qts); var spsEq = Vec.Equals(bytes, sps); var lineEndings = nlsEq | crsEq; var lineEndingsSeparators = spsEq | lineEndings; var specialChars = lineEndingsSeparators | qtsEq; // Optimize for the case of no special character var specialCharMask = MoveMask(specialChars); if (specialCharMask != 0u)
---|---
`
然后汇编变得更加简单和直接(更接近 AVX2),不仅避免了 mask 寄存器问题,而且具有更直接的饱和转换,因为打包的数据已经在 ymm4 寄存器中(即 zmm4 的 256 位部分)按顺序排列,因此不需要排列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
| ```
mov edi, r9d
lea rdi, bword ptr [r10+2*rdi]
vmovups zmm4, zmmword ptr [rdi]
vpmovuswb zmm4, zmm4
vpcmpeqb ymm5, ymm4, ymm0
vpcmpeqb ymm6, ymm4, ymm1
vpcmpeqb ymm7, ymm4, ymm2
vpcmpeqb ymm4, ymm4, ymm3
vpternlogd ymm5, ymm4, ymm6, -2
vpor ymm6, ymm5, ymm7
vpmovmskb r15d, ymm6
mov r15d, r15d
test r15, r15
je SHORT G_M000_IG03
vpmovmskb r13d, ymm4
mov r13d, r13d
lea r12, [r15+r8]
cmp r13, r12
je G_M000_IG43
---|---
`
这就是使 Sep 解析在 9950X 上达到惊人的 21 GB/s 的原因!🚀
### 所有解析器的基准测试
最后,鉴于 Sep 中所有可用的解析器,我添加了一个基准测试,该基准测试使用前面提到的环境变量来运行所有解析器,并比较它们在低级行解析中的性能,以便更好地衡量它们在同一 CPU 上的各个性能。这里是 AMD 9950X。
新的 AVX-512-to-256 解析器是所有解析器中最快的,达到了约 21.5 GB/s,但是基于 Vector256/AVX2 的解析器也不甘落后(约 5%)。`SepParserVector256NrwCmpExtMsbTzcnt` 是跨平台的基于 `Vector256` 的解析器,现在它与 AVX2 相当,但是请注意,其他跨平台的基于 `Vector128` 和 `Vector512` 的解析器并不相当(仍然很快,但慢 5-10%),甚至更糟糕的是 `Vector512` 的速度比 `Vector128` 慢。
`SepParserIndexOfAny` 远远落后,应该清楚地表明,任何认为它可以用来与 Sep 竞争的想法都是不切实际的。😉 `Vector64` 在 9950X 上没有加速,因此非常慢。它只是为了完整性而存在。
Parser | MB/s | ns/row | Mean
---|---|---|---
SepParserAvx512To256CmpOrMoveMaskTzcnt | `21597.7` | 27.0 | 1.351 ms
SepParserVector256NrwCmpExtMsbTzcnt | `20608.5` | 28.3 | 1.416 ms
SepParserAvx2PackCmpOrMoveMaskTzcnt | `20599.3` | 28.3 | 1.417 ms
SepParserAvx512PackCmpOrMoveMaskTzcnt | `19944.3` | 29.3 | 1.463 ms
SepParse