Sorbet 类型语法的过去、现在和未来
Sorbet 类型语法的过去、现在和未来
这是我于 2025 年 4 月 23 日首次发表的 演讲 的略经编辑的文字稿。 2025 年 4 月 25 日 首页 目录 ⊕
首先要承认的是:Sorbet 的语法很丑陋。 当人们开始抱怨 Sorbet 的语法时,我不得不花很多时间来转移话题甚至为它辩护,这很烦人:我完全同意,这个语法确实很丑!它很冗长,很陌生。它不像任何类型化的语言,也不与 Ruby 独特的风格互补。 我的反驳是,当涉及到语言设计时,语义——类型所代表的含义——比语法重要 10 倍。这是 我所学到的;这也是 我所见证的。编程是一种理论构建的行为,当你坐下来编写_代码_时,你试图将你对问题的思考方式编纂成机器指令。类型成为帮助将语义从你的头脑转移到代码库的工具。这是一个有损的过程,类型的作用有点像大脑转储的“纠错码”。 所以我尽_最大_努力避免陷入关于语法的争论——这在很大程度上是因为在我看来,大量抱怨语法的人_也_不喜欢这些语义,他们只是不知道如何表达。而且他们不仅不喜欢 Sorbet 的语义,他们从一开始就不喜欢静态类型的语义!即使我改变了他们对 Sorbet 语法的看法,我基本上也无法改变他们对静态类型的看法。所以何必呢?无论我说什么,他们都不会成为潜在的 Sorbet 用户。 但是以这种方式思考,我忽略了那些忠诚的、热情的 Sorbet 用户群体,他们实际上喜欢这些语义,但只是容忍这个语法。 所以这次演讲是为这些人准备的:我不是来劝你开始喜欢类型标注,或者开始使用 Sorbet!相反,我想把一切都摆出来,以便那些对语法比我更感兴趣的人可以了解问题所在,并将他们的抱怨转化为行动。 我们将涵盖很多内容:
- 在 Stripe 产生 Sorbet 的历史背景
- 源于该历史背景的目标和约束
- 我们随着时间的推移发现的各种问题,迫使我们重新设计类型语法
- 未来可能对语法进行的更改,范围从“是的,我们昨天就应该这样做”到“这听起来永远不会发生……但如果发生的话岂不是很酷?”
之前的时间
在我们深入了解之前,我忘了自我介绍:我的名字是 Jake,我已经全职从事 Sorbet 工作近 7 年了。

:jez-type-safety:
我在 Ruby 类型检查器项目启动前一个月加入 Stripe,并在 1 年后加入了该团队。我在这里要说的大部分内容都来自直接经验,来自午餐时与人的聊天,或者来自梳理旧邮件。这意味着 2017 年之前发生的一些事情有点模糊,但我会尽力做到最好。
在 2017 年年中(当我加入时,以及当 Sorbet 开始时),Stripe 大约有 750 人,其中大约 300 人是工程师。
每 6 个月(直到今天),Stripe 都会对公司所有工程师进行调查,询问他们的工作效率。在 2017 年的第一次调查中,工程师们被要求从以下列表中选择三项,以选择 Developer Productivity 团队的优先事项:
- 更好的技术文档
- Ruby 的静态类型检查
- 无人值守的部署
- 功能分支构建上的 CI 不稳定性
- 主分支构建上的 CI 不稳定性
- 异步编程原语和库
- 在开发中无缝启动多个服务
- 用于运行数据库迁移的 GUI
这是按他们的回答顺序排列的:前两名是“更好的文档”和“静态类型检查”。此外,在查看自由格式的回答时,提到“代码组织、接口和模块化”主题的抱怨数量比 6 个月前增加了一倍。测试速度虽然比之前的调查有了很大的提高,但仍然是一个普遍的呼声。 其中一个开放式问题是:“我们可以做哪些最重要的 1-2 件事来提高您的工作效率?”它得到的答案如下:
将所有东西都单仓库化;更好、更直观的代码/文档(更清晰的接口,静态类型,来自 linting 的更强保证) 静态类型 / 减少 [Stripe 的 Ruby 代码库] 中的魔法 构建速度更快,分支上的测试通过意味着您不会破坏主分支,[Stripe 的 Ruby 代码库] 中的静态类型 我提到所有这些是为了强调,我们构建 Sorbet 并不是因为我们想这样做,而是因为人们要求它! 这也是我很难为采用 Sorbet 的人提供建议的原因。他们会问我,“你是如何说服人们的?”我会说,“我们没有:他们_说服了_我们!”但我离题了,因为我今天不是想说服人们使用 Sorbet。
Stripe 对类型标注的需求
我们可以更深入地挖掘,看看这种对类型标注的需求从何而来。早在 2013 年,Stripe 就为其数据库模型定义开发了自己的对象数据库映射器:⊕ 为什么 Stripe 不使用官方 MongoDB ODM mongoid?我不知道。第一个 mongoid 提交比第一个 Odin 提交早大约 4 年,所以并不是没有替代方案。
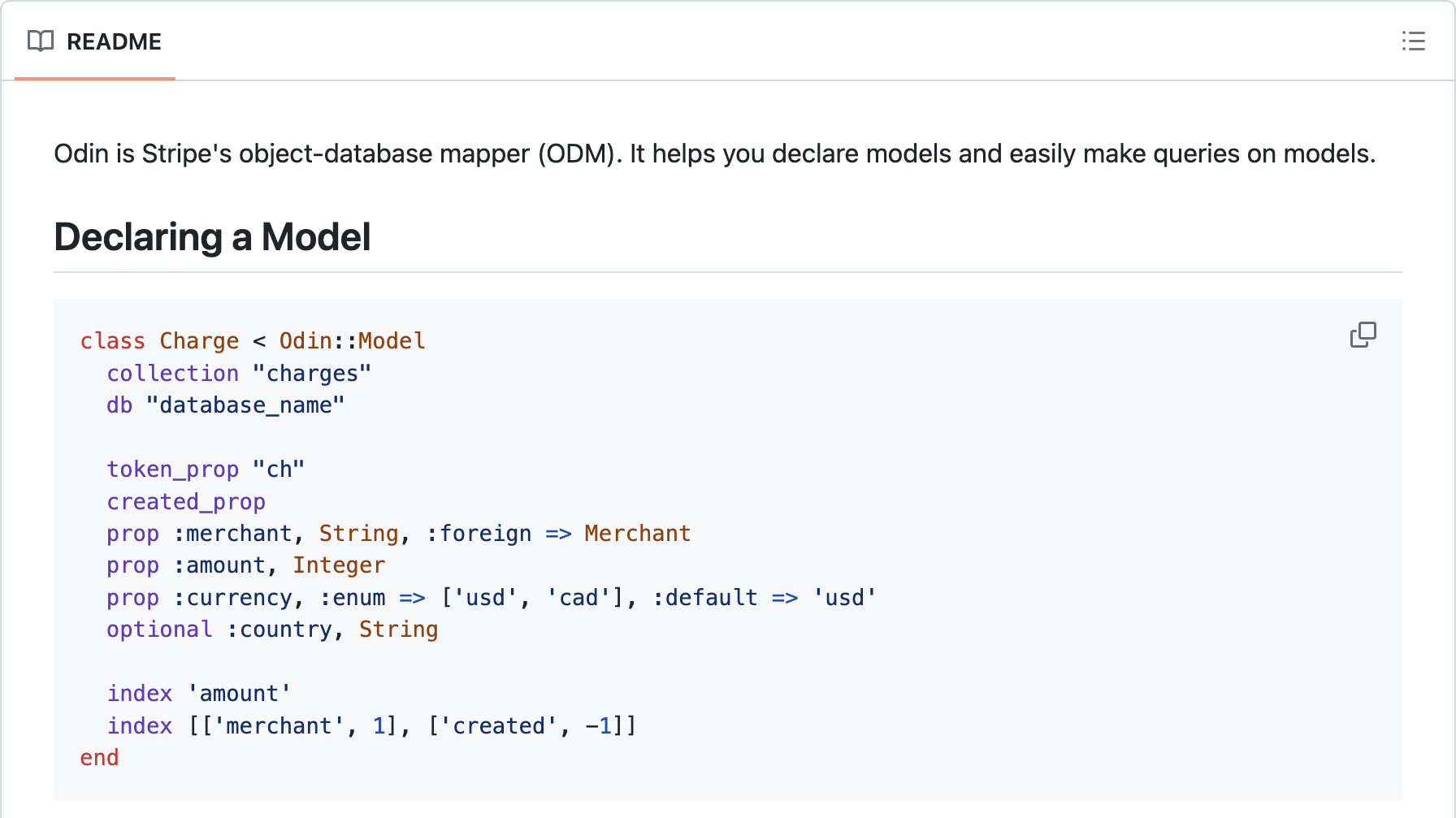
Odin::Model 的文档,它是 Chalk::ODM 以及后来的 T::Struct 的前身
对于任何使用 Sorbet 的人来说,这应该看起来非常熟悉:这与您今天用来定义 T::Struct 的代码完全相同。像任何好的 ODM (或 ORM) 一样,它在运行时进行类型验证,以确保数据库写入操作不会存储坏数据。
Stripe 还在 2013 年左右拥有一个用于定义接口的库:
 这个想法是,一个接口将公开一组特定的必需方法。然后,您可以将该接口的值框起来,例如
这个想法是,一个接口将公开一组特定的必需方法。然后,您可以将该接口的值框起来,例如
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb1-1>)animal = Animal.from_instance(Dog.new)
该库将检查您是否实现了所有必需的方法。此外,它还阻止在运行时调用不在接口中的方法。例如,animal.bark 将引发 NoMethodError,因为 bark 不在 Animal 的公共接口中。如果您需要调用特定于 Dog 的方法,您必须显式地向下转换为狗:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb2-1>)animal.bark # 💥
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb2-2>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb2-3>)dog = Chalk::Interface.dynamic_cast(animal, Dog)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb2-4>)dog.bark # ✅
如果您在不是 Dog 的东西上调用 dynamic_cast,您会得到 nil,就像 dynamic_cast 在 C++ 中的工作方式一样。
您应该看到一种模式:Stripe 对类型标注的大部分需求都表现为用于运行时检查和声明显式接口的 Ruby DSL。这在 2016 年 11 月达到了一个转折点——几乎在 Sorbet 出现一年前——当时 Stripe 实现了它所谓的“接口约束”。
⊕ 对于正在玩“发现时代错误”的 Stripe 员工来说,这张屏幕截图应该是 Hackpad 的,但那早已不复存在。

declare_method 的提案,sig 的最早前身,大约 2016 年 11 月
它是一个使用运行时类型检查包装方法的库,模仿了一种原始形式的“契约式设计。” ⊕ 在一个反复出现的主题中,Ruby 中已经有用于“契约式设计”的库,例如 contracts.ruby,Stripe 选择不使用它们。我找不到提及它们影响 Stripe 的“接口约束提案”的任何信息,但回想起来,我认为 Stripe 能够控制 Sorbet 类型语法的演变非常重要。
该库直接演变为 Sorbet 的 sig 语法,它的工作方式相同:该库允许声明方法的规范,然后使用运行时类型检查来包装以下方法。
该提案提到有一天可能会为这些注释构建静态检查,但这主要是假设性的:运行时检查从一开始就是重点。Ruby 是一种关于您可以在运行时做的很酷的事情的语言!
后来,这个 declare_method 库获得了对声明可覆盖和抽象方法的支持,这让它可以替换 Chalk::Interface 库(以便接口可以讨论所需的签名,而不仅仅是所需的方法):
 宣布
宣布 declare_method → standard_method 等等的电子邮件
加上为 Stripe 仪表板提供支持的 JavaScript 代码库在 2016 年 7 月获得了对静态类型的支持(通过 Flow ⊕ 在研究时,我遇到了来自 2014 年的 原始 Flow 公告,这对于理解其原始设计目标很有趣。),舞台已经搭好了。对 Ruby 静态类型的渴望在 2017 年上半年达到了一个闪点。Stripe 一位有影响力的工程师发出的一封特别的电子邮件(已经消失在保留的沙滩上)指出,鉴于 Stripe 的 Ruby 代码库的规模和演变,很难理解它,以及静态类型检查器可以消除这些问题的具体、引人注目的实例。
类型语法的设计
该团队评估了各种方法:
- 重写为类型化语言是行不通的:Stripe 当时有近 200 万行 Ruby 代码,正如我们在 Stripe 所说的那样,“[我们还没有赢](https://blog.jez.io/history-of-sorbet-syntax/https:/stripe.com/jobs/culture#:~:text=classic%E2%80%9D%20Stripe%20slogans%3A-,We%20haven%E2%80%99t%20won%20yet,-Efficiency%20is%20leverage),”这是一种说工作永不停止的方式。没有时间暂停所有功能开发并重写为另一种语言,因为这不会让我们的用户的生活更好。
- 大多数情况下,没有现有的 Ruby 类型检查器。RDL 项目,但它是一种混合的静态 + 运行时检查器。RDL 的“静态”检查发生在急切加载所有代码并使用 Ruby VM 进行大多数符号查找之后。当时,急切加载所有 Stripe 的代码(甚至没有要求 RDL 检查类型)花费了几分钟——相比之下,第一个版本的 Sorbet 在几秒钟内运行。
- 还有一个名为 TypedRuby 的项目,这在很大程度上是 GitHub 一位工程师的热情项目。经过几周的评估,似乎该项目中存在足够的错误,以至于修复它们将需要几乎完全重写该项目。
因此,该团队决定从头开始编写一些东西,这意味着要设计一种类型语法。让我们看看一些方法。
TypeScript 的方法:在顶部添加类型,编译时移除它们
事后看来,最明显的方法是 TypeScript 取得巨大成功的方法:构建我们自己的语法,不受源语言中任何约束的限制,并使用构建步骤将其编译掉。 对于 Sorbet 来说,这将意味着与 Ruby 兼容性的巨大突破。在 JavaScript 世界中,minifiers、tree shakers、transpilers 和 compile-to-JS 语言随处可见。大多数开发人员早在 TypeScript 流行之前就放弃了“保存文件,重新加载页面”的开发模式:CoffeeScript 比 TypeScript 早 4 年。 但即使在今天,我也不知道任何具有源转换构建步骤的、大小可观的 Ruby 代码库会阻止运行测试或重新加载服务。Ruby 工程师期望直接运行测试,并能够在保存文件后立即重新加载服务。引入一个强制性的构建步骤来阻止运行测试将会是一个很大的摩擦点。 即使 Stripe 可以接受强加一个构建步骤,它也会破坏几乎所有 Ruby 开发工具。Linters、语法高亮和代码格式化将会中断。可观察性工具将显示在错误位置的回溯,因为 Ruby VM 没有源代码映射。像 RubyMine 这样的 IDE 将会退化为文本编辑器。 假设我们也构建了所有这些工具。我们希望有一天开源 Sorbet:这是项目简报中的首要目标。如果有人要采用 Sorbet,它需要是渐进的:不需要从根本上重新设计代码库构建、测试和部署代码的方式来试用它。采用构建步骤对于代码库来说是一个巨大的“要么全有要么全无”的决定。
头文件方法:类似于现在的 RBS
如果我们不能更改源代码语法,也许我们可以制作自己的语法来声明类型?每个源文件都可以与一种“头”类型定义文件配对,该文件声明类型。
基本上所有渐进式语言最终都会支持这一点:TypeScript 有 *.d.ts,Python 有 *.pyi。Sorbet 有 *.rbi 文件,Ruby 最终发布了 *.rbs。您需要这些文件来为完全不受您控制的文件声明类型:第三方 gem、在原生扩展中定义的内容等。
问题在于它们只是解决方案的一半:即使您使用 RBS 文件来注释方法,您仍然需要在方法体中使用显式类型转换。仅 RBS 文件无法说,“相信我,在这里我知道这个变量是一个 Integer。”
我会说:这种方法的好处是您可以自由选择您想要的任何干净的语法:它在类型语法设计上是空白的,几乎没有约束,甚至比 transpiler 方法更空白。我们稍后会回到这一点。
JSDoc 的方法:注释中的类型
如果类型需要在源代码中,并且我们不能更改语法,也许我们会在注释中发明自己的语法?Google 的 Closure Compiler 在 TypeScript 出现之前就选择了这种策略,并且 Ruby 已经通过 YARD 等工具拥有基于注释的类型注释的历史。Sorbet 本可以形式化一种严格的基于类型的注释语法,并将其用于方法签名和内联类型转换。 但在这里我们回到了运行时检查的问题:Stripe 工程师要求进行静态和运行时类型检查,而不是静态而不是运行时! 如果您使用运行时检查来装饰一个方法,您可以免费获得很多东西,其中最重要的是保证没有人会 Hyrum's Law 您的方法:
如果有足够多的 API 用户,那么您在合同中承诺什么并不重要:系统的所有可观察行为都将被某些人依赖。 考虑以下代码:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb3-1>)def get_mcc(charge, merchant)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb3-2>) return charge.mcc if charge
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb3-3>) merchant.default_mcc
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb3-4>)end
如果 charge 为非 nil,我们会在检查 merchant 是否为 nil 之前提前返回。现在假设我们需要编辑该方法来实现一个新的“商户覆盖 MCC”功能:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb4-1>)def get_mcc(charge, merchant)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb4-2>) override = merchant.override_mcc
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb4-3>) return override if override
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb4-4>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb4-5>) return charge.mcc if charge
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb4-6>) merchant.default_mcc
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb4-7>)end
这个新的覆盖旨在优先于 charge 上的任何“MCC”。这个更改安全吗?调用者应该将一个非 nil 的商户传递给这个方法,但也许有些人没有?如果我们不确定,现在我们必须采取防御措施,这很烦人,并且可能导致其他问题!
但是,当在具有运行时检查签名的方法中进行更改时,这个问题就消失了。
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb5-1>)sig { params(charge: Charge, merchant: Merchant).returns(MCC) }
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb5-2>)def get_mcc(charge, merchant)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb5-3>) override = merchant.override_mcc
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb5-4>) return override if override
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb5-5>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb5-6>) return charge.mcc if charge
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb5-7>) merchant.default_mcc
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb5-8>)end
如果签名说它是非 nil 的,我们可以在整个方法体中、在所有条件语句中都依赖于该不变量。只要该方法已经有一个运行时检查的 sig,添加对 merchant.override_mcc 的新调用就不会导致_新的_未捕获的 NoMethodError 异常。在有数百人进行更改的、不断增长的代码库中,运行时检查确保代码保持灵活性,而无需担心。
一种基于注释的类型语法方法意味着放弃运行时检查的签名。再说一遍:运行时检查是 Ruby 动态性的独特优势!
DSL 方法:declare_method 变为 sig
Sorbet 选择的方法是重新利用 Stripe 的 declare_method DSL。作为一个好处,这意味着该项目立即获得了数千个值得信赖的注释,可以用作实现的试验场。
在我们深入研究 DSL 方法的具体考虑因素之前,我想花一点时间惊叹于这种方法实际上有效这一事实。这太疯狂了,不是吗?用一行代码装饰一个方法——在一种没有一流装饰器的语言中!——并且以下方法会进行运行时检查。您可以尝试在 JavaScript 中使用高阶函数来近似这一点,但它看起来远没有那么好。
在 declare_method 缩短为 sig 的同时,类型语法也从类似 Opus::Types.any(NilClass, String) 的内容缩短为仅 T.nilable(String)。
sig 使用的特定语法演变了几次 ⊕ 真的,在研究这个主题时,我发现了如此多古怪的旧语法,太多了,无法全部放在这篇文章中。如果您想要详细信息,请随时问我。 我想讨论这些变化,但在此之前,我想考虑最后一种方法。
Python 的方法:第一方类型提示
Python 中的类型支持方式不同。早在 2007 年,就接受了一个关于“函数注释”的提案:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb6-1>)def foo(a: expression, b: expression = 5):
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb6-2>) ...
这个想法是,注释将完全没有意义,以便各种工具可以赋予它们自己的意义。就像:您可以在那里存储任意字符串并将其用于文档,或者您可以在那里放置类名并将其用作类型,等等。即使在当时,人们 已经在讨论 各种项目注释的互操作性,最终在 2015 年的一项后续提案形式化了 类型提示,基本上说,“您不必将函数注释用于类型,但如果您要使用,您应该遵循这些约定来理解类型的含义。”
这些注释发挥了 Python 作为一种动态的、以运行时为中心的语言的优势。它们不是像 TypeScript 那样被编译掉的静态注释:它们通过 __annotations__ 属性在运行时存在,并且注释可以评估任意代码!Python VM 不会将它们用于运行时检查,但是 多个、第三方 库 提供了执行此操作的装饰器。
对于 Python 来说,这种方法有很多优点:
- 它是一种一流的语法,与其他语言的语法感觉很自然。
- 单个项目可以选择他们是否需要运行时检查。
- 这些注释始终在运行时存在,供第三方工具直接使用它们。
显而易见的缺点是它需要更改 VM。在 Sorbet 的规划阶段,要求 Ruby 团队为我们发明语法是行不通的。 ……但是如果您眯起眼睛,Sorbet 的 DSL 方法几乎与这种类型提示方法相同!
- 两者都将注释视为完全可选。
- 两者都将注释视为可运行的语法,允许语言的完全灵活性。
- 两者都允许可选的静态和可选的运行时检查。
- 两者都提供了一个反射 API 来在运行时获取注释。
最大的区别只是语法——两者都提供了我们需要的语义!当 Sorbet 以 DSL 方法开始时,一个卖点是,如果这成为一种选择,它很容易迁移到一种经过认可的、上游的类型提示方法。 不幸的是,类型提示方法在 Ruby 中停滞不前。我对这一点有更多的想法,但现在让我们继续回顾 Sorbet 的 DSL 语法的演变。
类型是表达式
DSL 方法和类型提示方法都具有类型是表达式的特征。这导致了类型语法设计的三个主要约束。
当我们想要的语法已经被占用时
当类型是表达式时,有时您想要的类型语法已经有另一种含义。
直接在类或模块名称上使用 | 作为联合类型、& 作为交集类型以及 [] 作为泛型类型会非常好:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb7-1>)Integer | String # Module#|
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb7-2>)Runnable & HasOwner # Module#&
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb7-3>)Box[Integer] # Module#[]
有两个问题:
- 它将涉及 monkey patching
Module,这将是有争议的,因此需要选择加入:这种语法不能是唯一接受的语法。 - 某些单例类可能已经定义了这些方法。
Array和Set是标准库中的示例:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb8-1>)Array[1, 2, 3] # Array.[]
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb8-2>)# => [1, 2, 3]
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb8-3>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb8-4>)Set[1, 2, 3] # Set.[]
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb8-5>)# => #<Set: {1, 2, 3}>
因此,Array[Integer] 不会创建一个泛型类型,而是创建一个长度为 1 的数组:[Integer]。⊕ 当我们处于古怪的领域时,我们可以使用“块作用域”monkey patching,其中我们在评估 sig 块时替换某些方法的含义以使其工作,但早期的观点仍然存在:有些人不想要它。
元组也会出现类似的情况:| 和 & 方法对于数组已经有意义:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb9-1>)[1, 3, 5] | [2, 4, 6] # Array#|
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb9-2>)# => [1, 3, 5, 2, 4, 6]
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb9-3>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb9-4>)[1, 2, 3] & [2, 3, 4] # Array#&
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb9-5>)# => [2, 3]
在这种情况下,放弃使用原始 Array 字面量作为元组可能更容易,而是使用类似 T[Integer, String] 的语法来定义一个元组,从而释放 | 和 &。
在构建 Sorbet 时,我们的目标是保持一致性,采用一种方法来做事。也许现在是时候放松一下了?如果 Ruby 可以接受使用三种名称来过滤列表,那么 Sorbet 也可以接受使用多种方式来指定联合类型。我们可以让单个代码库决定他们想要使用哪种语法。
前向引用
当类型是表达式时,您必须担心类型语法中的前向引用。DSL 语法的演变如下所示:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb10-1>)declare_method({x: Integer}, returns: String)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb10-2>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb10-3>)standard_method({x: Integer}, returns: String)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb10-4>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb10-5>)sig.params(x: Integer).returns(String)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb10-6>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb10-7>)sig { params(x: Integer).returns(String) }
最近的更改切换为在块内指定类型,这样做是为了添加 sig 不会导致加载顺序问题。例如:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-1>)class A
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-2>) sig.params(x: MyData).void
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-3>) def self.example(my_data)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-4>) puts(my_data.foo)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-5>) end
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-6>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-7>) MyData = Struct.new(:foo)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-8>)end
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-9>)
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb11-10>)A.example(MyData.new(42))
加载此文件没有问题,直到您添加 sig(如图所示,使用旧的、急切的语法)。即使 MyData#foo 方法在第 4 行被调用,也在第 7 行的定义之上,这也没关系,因为 example 直到第 10 行才被调用。
但是添加 sig 会破坏这一点:现在有一个对 MyData 的前向引用,sig 会急切地评估它,从而在加载时引发异常。随着人们添加越来越多的 sig,这不断引起问题。由于自动加载,问题变得更糟:在开发中,一切可能看起来都很好,因为您只以某种顺序评估事物,然后在 CI 或生产中,以不同顺序加载事物会咬您。
将所有类型隐藏在一个块中会将签名从急切评估切换为延迟评估:运行时实现会将强制块推迟到第一次调用该方法。这些天,如果代码已经存在加载顺序问题,您基本上只会遇到加载顺序问题。
有趣的是,Python 类型提示也经历了非常相似的成长之痛,并且在较新版本的 Python 中,您可以编写:
[](https://blog.jez.io/history-of-sorbet-syntax/<#cb12-1>)from __future__ import annotations
将类型提示从急切评估转换为延迟评估。介绍它的提案 写得非常好,并且对历史和问题进行了很好的总结。
有时你真的很想要自定义语法
当类型是表达式时,您会受到有效 Ruby 语法的限制。有很多替代语法对于类型语法来说非常好:
Integer?而不是 `T.