Embeddings Are Underrated
被低估的 Embeddings 技术
机器学习 (ML) 有潜力推动技术写作的进步。不,我不是在说像 Claude, Gemini, LLaMa, GPT 等文本生成模型。可能对技术写作产生最大影响的 ML 技术是 embeddings。
Embeddings 并非全新事物,但在过去几年里,它们的可访问性大大提高。Embeddings 为技术写作者提供的是以前所未有的规模发现文本之间关联的能力。
构建对 Embeddings 的直觉认识
以下是如何使用 embeddings 以及它们如何工作的一个概述。它是为初次接触 embeddings 的技术写作者准备的。
输入与输出
有人让你“生成一些 embeddings”。你需要输入什么?你需要输入文本。 你不需要每次都提供相同数量的文本。例如,有时你的输入是单个段落,而另一些时候可能是几个章节、整个文档,甚至多个文档。
你得到什么作为返回? 如果你提供单个词作为输入,输出将是一个数字数组,如下所示:
[-0.02387, -0.0353, 0.0456]
现在假设你的输入是整个文档集合。输出就变成这样:
[0.0451, -0.0154, 0.0020]
一个输入远小于另一个输入,但它们都产生了包含 3 个数字的数组。真是越来越奇怪了。(当你在实际中使用 embeddings 时,数组将包含数百或数千个数字,而不是 3 个。稍后会详细介绍。)
这里是第一个关键的理解。 因为无论输入文本的大小如何,我们总是得到相同数量的数字,我们现在有了一种可以用数学方法比较任意两段文本的方式。
但是,这些数字 意味 着什么呢?
1 有些 embedding 模型是“多模态的”,这意味着你也可以提供图像、视频和音频作为输入。 这篇文章侧重于文本,因为这是我们技术写作者最常使用的媒介。 还没有见过支持味觉、触觉或嗅觉的多模态模型!
首先,如何真正地生成 embeddings
大型服务提供商已经让它变得很容易。 以下是使用 Gemini 的方法:
importgoogle.generativeaiasgemini
gemini.configure(api_key='…')
text = 'Hello, world!'
response = gemini.embed_content(
model='models/text-embedding-004',
content=text,
task_type='SEMANTIC_SIMILARITY'
)
embedding = response['embedding']
数组的大小取决于你使用的模型。 Gemini 的 text-embedding-004 模型返回一个包含 768 个数字的数组,而 Voyage AI 的 voyage-3 模型返回一个包含 1024 个数字的数组。 这是你不能互换使用来自不同提供商的 embeddings 的原因之一。(主要原因是来自一个模型的数字的含义与来自另一个模型的数字的含义完全不同。)
花费很多钱吗?
不。
对环境有害吗?
我不知道。 在创建(训练)模型之后,我非常确定生成 embeddings 的计算密集程度远低于生成文本。 但似乎 embedding 模型的训练方式与文本生成模型 2 类似,这意味着会消耗大量能源。 找到更多信息后,我将更新此部分。
2 来自 You Should Probably Pay Attention to Tokenizers: “Embeddings 是 transformer 训练的副产品,实际上是在大量的分词文本上训练的。 更好的是:当我们要求 LLMs 生成文本时,embeddings 实际上是作为输入提供给 LLMs 的。”
什么模型最好?
理想情况下,你的 embedding 模型可以接受大量的输入文本,这样你就可以为完整的页面生成 embeddings。 如果你尝试提供的输入超过了模型可以处理的范围,你通常会收到错误。 截至 2024 年 10 月,voyage-3 在输入大小 3 方面似乎是明显的赢家:
组织 | 模型名称 | 输入限制 (tokens) ---|---|--- Voyage AI | voyage-3 | 32000 Nomic | Embed | 8192 OpenAI | text-embedding-3-large | 81914 Mistral | Embed | 8000 Google | text-embedding-004 | 2048 Cohere | embed-english-v3.0 | 512
对于我作为技术写作者的特定用例,大的输入大小是一个重要因素。 但是,你的用例可能不需要大的输入大小,或者可能有其他更重要的因素。 参阅 Massive Text Embedding Benchmark (MTEB) 排行榜。
3 这些输入限制基于 tokens,并且每个服务计算 tokens 的方式都不同,因此不要太看重这些确切的数字。 例如,一个模型的 token 可能大约是 3 个字符,而另一个模型可能是大约 4 个字符。 4 以前,我错误地将此模型的输入限制列为 3072。 很抱歉。
非常奇怪的多维空间
回到最大的谜团。 这些数字到底 意味 着什么?
让我们从思考地图上的坐标开始。 假设我给你三个点及其坐标:
点 | X 坐标 | Y 坐标 ---|---|--- A | 3 | 2 B | 1 | 1 C | -2 | -2
这个地图有 2 个维度:X 坐标和 Y 坐标。 每个点都位于 X 坐标和 Y 坐标的交点处。
A 更接近 B 还是 C?
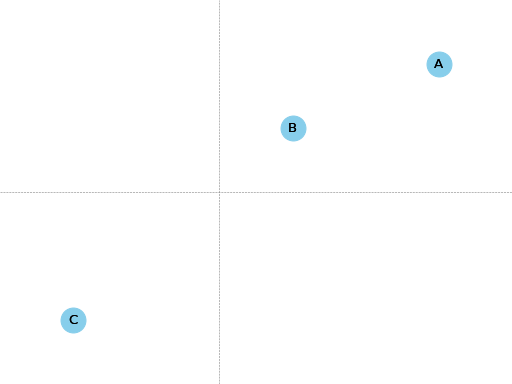
A 更接近 B。
这里是一个思维的飞跃。Embeddings 类似于地图上的点。 embedding 数组中的每个数字都是一个_维度_,类似于之前的 X 坐标和 Y 坐标。 当 embedding 模型向你返回一个包含 1000 个数字的数组时,它会告诉你该文本在它的 1000 维空间中_语义上_所处的位置,相对于所有其他文本。 当我们比较此 1000 维空间中两个 embeddings 之间的距离时,我们实际上是在确定这两个文本在语义上彼此之间的距离有多近或多远。

以这种方式将项目放置在多维空间中的概念,其中相关项目聚集在一起,这个概念有一个很棒的名字,叫做 latent space(潜在空间)。
这项技术最著名的实用性示例来自 Word2vec paper,这是 11 年前引发人们对 embeddings 兴趣的基础研究。 在论文中,他们分享了这则轶事:
embedding("king") - embedding("man") + embedding("woman") ≈ embedding("queen")
从 king 的 embedding 开始,减去 man 的 embedding,然后加上 woman 的 embedding。 当你在此潜在空间的附近查看时,你会发现 queen 的 embedding 就在附近。 换句话说,embeddings 可以以对我们人类来说感觉直观的方式表示语义关系。 如果你问一个人“什么是国王的女性等价物?”,那个人可能会回答“女王”,这与我们从 embeddings 得到的答案相同。 有关底层理论的更多解释,请参阅 Distributional semantics(分布语义学)。
二维地图类比是构建直觉的一个很好的垫脚石,但现在我们需要把它放在一边,因为 embeddings 在数百或数千个维度中运行。 我们这些低级的 3 维生物不可能可视化“距离”在 1000 个维度中是什么样的。 此外,我们不知道每个维度代表什么,因此才有了标题“非常奇怪的多维空间”。5 一个维度可能代表某种接近颜色的东西。 king - man + woman ≈ queen 这则轶事表明这些模型包含一个具有某种性别概念的维度。 等等。好吧,伙计,我们就是不知道。
正如你可能想象的那样,将文本转换为非常奇怪的多维空间的机制很复杂。 毕竟,他们是在教_机器_去_学习_。The Illustrated Word2vec 是你开始进入兔子洞的一个好方法。
5 我从 Embeddings: What they are and why they matter 中借用了这句话。
比较 Embeddings
生成 embeddings 后,你需要某种“数据库”来跟踪每个 embedding 与什么文本相关联。 在稍后讨论的实验中,我仅使用了一个本地 JSON 文件:
{
"authors": {
"embedding": […]
},
"changes/0.1": {
"embedding": […]
},
…
}
authors 是一个页面的名称。 embedding 是该页面的 embedding。
比较 embeddings 涉及大量的线性代数。 我从 Linear Algebra for Machine Learning and Data Science 中学习了基础知识。 像 NumPy 和 scikit-learn 这样的大型数学和 ML 库可以为你完成繁重的工作(即,你这端几乎不需要编写数学代码)。
应用
我可以告诉你我究竟认为我们如何才能利用 embeddings 来推进技术写作,但那有什么乐趣呢? 你现在知道了为什么它们是技术写作者工具箱中如此有趣和有用的新工具……自己去连接剩下的点吧!
让我们介绍一个基本示例,将直觉构建的想法付诸实践,然后结束这篇文章。
相关页面
有些文档站点有一个推荐系统,让你了解其他相关的文档。 该系统会查看你当前所在的任何页面,找到与该页面相关的其他页面,然后建议访问其他页面。 Embeddings 提供了一种支持此功能的新方法,可能只需以前方法成本的一小部分。 它是这样工作的:
- 为你的文档站点上的每个页面生成一个 embedding。
- 对于每个页面,将其 embedding 与所有其他页面 embeddings 进行比较。 如果两个 embeddings 在数学上相似,那么这两个页面上的内容可能彼此相关。
这可以作为批量操作来完成。 只有当页面的内容发生变化时,才需要更改页面的 embedding。
我在 Sphinx 文档上运行了这个实验。 结果非常好。 Implementation 和 Results 中有详细信息。
有关此方法的另一个示例,请参阅 Related content using embeddings。
让一千个 Embeddings 绽放?
作为文档站点的所有者,我想知道我们是否应该开始通过 REST APIs 或 well-known URIs 免费为我们的内容提供 embeddings 给任何想要它们的人。 谁知道我们的社区可以利用关于我们文档的这种额外类型的数据构建出什么样的酷东西呢?
结束语
三年前,如果你问我什么是 768 维空间,我会告诉你这只是物理学家和数学家出于深奥的原因需要的抽象概念,可能与弦理论有关。 Embeddings 给了我一个更深入地思考这个想法并将它实际应用到我自己的工作中的理由。 我觉得这很酷。
我们维护文档的能力的数量级改进很可能仍然是可能的……也许我们只需要数量级更多的维度!
附录
实现
我创建了一个 Sphinx extension,用于为每个文档生成一个 embedding。 Sphinx 在构建文档时会自动调用此扩展。
importjson
importos
importvoyageai
VOYAGE_API_KEY = os.getenv('VOYAGE_API_KEY')
voyage = voyageai.Client(api_key=VOYAGE_API_KEY)
defon_build_finished(app, exception):
with open(srcpath, 'w') as f:
json.dump(data, f, indent=4)
defembed_with_voyage(text):
try:
embedding = voyage.embed([text], model='voyage-3', input_type='document').embeddings[0]
return embedding
except Exception as e:
return None
defon_doctree_resolved(app, doctree, docname):
text = doctree.astext()
embedding = embed_with_voyage(text) # Generate an embedding for each document!
data[docname] = {
'embedding': embedding
}
# Use some globals because this is just an experiment and you can't stop me
definit_globals(srcdir):
global filename
global srcpath
global data
filename = 'embeddings.json'
srcpath = f'{srcdir}/{filename}'
data = {}
defsetup(app):
init_globals(app.srcdir)
# https://www.sphinx-doc.org/en/master/extdev/appapi.html#sphinx-core-events
app.connect('doctree-resolved', on_doctree_resolved) # This event fires on every doc that's processed
app.connect('build-finished', on_build_finished)
return {
'version': '0.0.1',
'parallel_read_safe': True,
'parallel_write_safe': True,
}
构建完成后,embeddings 数据将存储在 embeddings.json 中,如下所示:
{
"authors": {
"embedding": […]
},
"changes/0.1": {
"embedding": […]
},
…
}
authors 和 changes/0.1 是文档。 embedding 包含该文档的 embedding。
最后一步是找到每个文档的最近邻居。 即,找到被认为与你当前所在的页面相关的另一个页面。 正如前面提到的,Linear Algebra for Machine Learning and Data Science 这门课程教会了我基础知识。
importjson
importnumpyasnp
fromsklearn.metrics.pairwiseimport cosine_similarity
deffind_docname(data, target):
for docname in data:
if data[docname]['embedding'] == target:
return docname
return None
# Adapted from the Voyage AI docs
# https://web.archive.org/web/20240923001107/https://docs.voyageai.com/docs/quickstart-tutorial
defk_nearest_neighbors(target, embeddings, k=5):
# Convert to numpy array
target = np.array(target)
embeddings = np.array(embeddings)
# Reshape the query vector embedding to a matrix of shape (1, n) to make it
# compatible with cosine_similarity
target = target.reshape(1, -1)
# Calculate the similarity for each item in data
cosine_sim = cosine_similarity(target, embeddings)
# Sort the data by similarity in descending order and take the top k items
sorted_indices = np.argsort(cosine_sim[0])[::-1]
# Take the top k related embeddings
top_k_related_embeddings = embeddings[sorted_indices[:k]]
top_k_related_embeddings = [
list(row[:]) for row in top_k_related_embeddings
] # convert to list
return top_k_related_embeddings
with open('doc/embeddings.json', 'r') as f:
data = json.load(f)
embeddings = [data[docname]['embedding'] for docname in data]
print('.. csv-table::')
print(' :header: "Target", "Neighbor"')
print()
for target in embeddings:
dot_products = np.dot(embeddings, target)
neighbors = k_nearest_neighbors(target, embeddings, k=3)
# ignore neighbors[0] because that is always the target itself
nearest_neighbor = neighbors[1]
target_docname = find_docname(data, target)
target_cell = f'`{target_docname} <https://www.sphinx-doc.org/en/master/{target_docname}.html>`_'
neighbor_docname = find_docname(data, nearest_neighbor)
neighbor_cell = f'`{neighbor_docname} <https://www.sphinx-doc.org/en/master/{neighbor_docname}.html>`_'
print(f' "{target_cell}", "{neighbor_cell}"')
你可能已经注意到,我实际上并没有在这个实验中实现推荐 UI。 我的主要目标是获取基本数据,了解 embeddings 方法是否能生成不错的推荐。
结果
如何解释数据:“Target”是你当前所在的页面。 “Neighbor”将是推荐的页面。
Target | Neighbor ---|--- authors | changes/0.6 changes/0.1 | changes/0.5 changes/0.2 | changes/1.2 changes/0.3 | changes/0.4 changes/0.4 | changes/1.2 changes/0.5 | changes/0.6 changes/0.6 | changes/1.6 changes/1.0 | changes/1.3 changes/1.1 | changes/1.2 changes/1.2 | changes/1.1 changes/1.3 | changes/1.4 changes/1.4 | changes/1.3 changes/1.5 | changes/1.6 changes/1.6 | changes/1.5 changes/1.7 | changes/1.8 changes/1.8 | changes/1.6 changes/2.0 | changes/1.8 changes/2.1 | changes/1.2 changes/2.2 | changes/1.2 changes/2.3 | changes/2.1 changes/2.4 | changes/3.5 changes/3.0 | changes/4.3 changes/3.1 | changes/3.3 changes/3.2 | changes/3.0 changes/3.3 | changes/3.1 changes/3.4 | changes/4.3 changes/3.5 | changes/1.3 changes/4.0 | changes/3.0 changes/4.1 | changes/4.4 changes/4.2 | changes/4.4 changes/4.3 | changes/3.0 changes/4.4 | changes/7.4 changes/4.5 | changes/4.4 changes/5.0 | changes/3.5 changes/5.1 | changes/5.0 changes/5.2 | changes/3.5 changes/5.3 | changes/5.2 changes/6.0 | changes/6.2 changes/6.1 | changes/6.2 changes/6.2 | changes/6.1 changes/7.0 | extdev/deprecated changes/7.1 | changes/7.2 changes/7.2 | changes/7.4 changes/7.3 | changes/7.4 [changes/7.4](https://technicalwriting.dev/