LPython:全新、快速、可重定向的 Python 编译器 (2023)
LPython: Novel, Fast, Retargetable Python Compiler
发布于 2023 年 7 月 28 日 | 24 分钟 | 5108 字 | Ondřej Čertík, Brian Beckman, Gagandeep Singh, Thirumalai Shaktivel, Smit Lunagariya, Ubaid Shaikh, Naman Gera, Pranav Goswami, Rohit Goswami, Dominic Poerio, Akshānsh Bhatt, Virendra Kabra, Luthfan Lubis
关于
LPython 是一种 Python 编译器,可以将带有类型注解的 Python 代码编译为优化的机器码。LPython 提供多种后端,如 LLVM、C、C++、WASM、Julia 和 x86。正如我们在本博客的基准测试中展示的那样,LPython 具有快速的编译和运行时性能。LPython 还提供即时 (JIT) 编译以及与 CPython 的无缝互操作性。
我们正在发布 LPython 的 alpha 版本,这意味着您在使用它时可能会遇到错误(请报告它们!)。您可以使用 Conda (conda install -c conda-forge lpython) 安装它,或者从源代码构建。
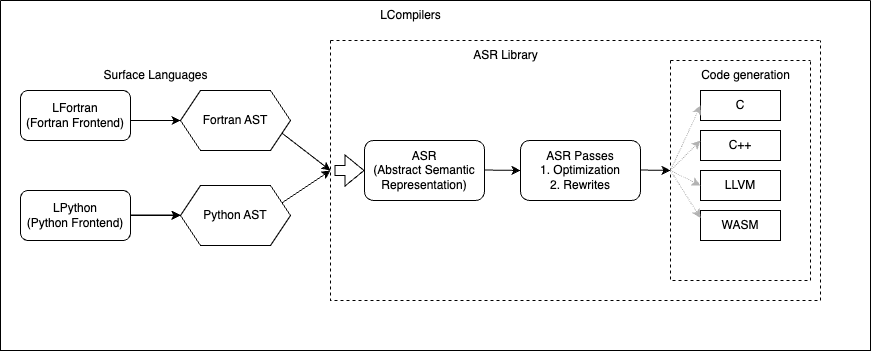
基于与 LFortran 共享的新型抽象语义表示 (ASR),LPython 的中间优化独立于后端和前端。LPython 和 LFortran 这两个编译器共享 ASR 级别改进的所有好处。“速度”是 LPython 项目的主要原则。我们的目标是创建一个既运行速度极快又生成极快代码的编译器。
在本博客中,我们将介绍 LPython 的功能,包括提前 (AoT) 编译、JIT 编译以及与 CPython 的互操作性。我们还将通过多个基准测试展示 LPython 相对于 Numba 和 C++ 等竞争对手的性能。
LPython 的功能
后端
LPython 附带以下后端,它们发出用户输入代码的最终翻译:
- LLVM
- C
- C++
- WASM
LPython 可以同时从用户代码的抽象语义表示 (ASR) 生成到多个后端。
编译阶段
首先,使用解析器将输入代码转换为抽象语法树 (AST)。然后,将 AST 转换为抽象语义表示 (ASR),ASR 保留输入代码中存在的所有语义信息。ASR 包含所有后端所需的信息,其形式不特定于任何特定后端。然后,此 ASR 经历多个 ASR 到 ASR 的传递,其中抽象操作被转换为具体的语句。例如,输入代码中的数组加法表示为 c = a + b。前端通过运算符重载将 c = a + b 转换为 ASR (Assign c (ArrayAdd a b))。_array_op_ ASR 到 ASR 的传递将 (Assign c (ArrayAdd a b)) 转换为循环:
for i0 in range(0, length_dim_0):
for i1 in range(0, length_dim_1):
....
....
c[i0, i1, ...] = a[i0, i1, ...] + b[i0, i1, ...]
在应用所有 ASR 到 ASR 的传递之后,LPython 通过命令行参数(例如,--show-c(生成 C 代码),--show-llvm(生成 LLVM 代码))将最终 ASR 发送到用户选择的后端。
也可以使用以下方法查看生成的 C 或 LLVM 代码
from lpython import i32
def main():
x: i32
x = (2+3)*5
print(x)
main()
$ lpython examples/expr2.py --show-c
#include <inttypes.h>#include <stdlib.h>#include <stdbool.h>#include <stdio.h>#include <string.h>#include <lfortran_intrinsics.h>void main0();
void __main____global_statements();
// Implementations
void main0()
{
int32_t x;
x = (2 + 3)*5;
printf("%d\n", x);
}
void __main____global_statements()
{
main0();
}
int main(int argc, char* argv[])
{
_lpython_set_argv(argc, argv);
__main____global_statements();
return 0;
}
$ lpython examples/expr2.py --show-llvm
; ModuleID = 'LFortran'
source_filename = "LFortran"
@0 = private unnamed_addr constant [2 x i8] c" \00", align 1
@1 = private unnamed_addr constant [2 x i8] c"\0A\00", align 1
@2 = private unnamed_addr constant [5 x i8] c"%d%s\00", align 1
define void @__module___main_____main____global_statements() {
.entry:
call void @__module___main___main0()
br label %return
return: ; preds = %.entry
ret void
}
define void @__module___main___main0() {
.entry:
%x = alloca i32, align 4
store i32 25, i32* %x, align 4
%0 = load i32, i32* %x, align 4
call void (i8*, ...) @_lfortran_printf(i8* getelementptr inbounds ([5 x i8], [5 x i8]* @2, i32 0, i32 0), i32 %0, i8* getelementptr inbounds ([2 x i8], [2 x i8]* @1, i32 0, i32 0))
br label %return
return: ; preds = %.entry
ret void
}
declare void @_lfortran_printf(i8*, ...)
define i32 @main(i32 %0, i8** %1) {
.entry:
call void @_lpython_set_argv(i32 %0, i8** %1)
call void @__module___main_____main____global_statements()
ret i32 0
}
declare void @_lpython_set_argv(i32, i8**)
机器无关的代码优化
LPython 通过 ASR 到 ASR 的传递实现多个机器无关的优化。下面列出了一些:
- 循环展开
- 循环向量化
- 死代码消除
- 函数调用内联
- 将除法转换为乘法运算
- 融合乘法和加法
所有优化都通过一个命令行参数 --fast 应用。要选择单个优化,请编写如下命令行参数:
--pass=inline_function_calls,loop_unroll
以下是在应用优化后 ASR 和转换后的 ASR 的示例
from lpython import i32
def compute_x() -> i32:
return (2 * 3) ** 1 + 2
def main():
x: i32 = compute_x()
print(x)
main()
$ lpython examples/expr2.py --show-asr
(TranslationUnit
(SymbolTable
1
{
__main__:
(Module
(SymbolTable
2
{
__main____global_statements:
(Function
(SymbolTable
5
{
})
__main____global_statements
(FunctionType
[]
()
Source
Implementation
()
.false.
.false.
.false.
.false.
.false.
[]
[]
.false.
)
[main]
[]
[(SubroutineCall
2 main
()
[]
()
)]
()
Public
.false.
.false.
()
),
compute_x:
(Function
(SymbolTable
3
{
_lpython_return_variable:
(Variable
3
_lpython_return_variable
[]
ReturnVar
()
()
Default
(Integer 4)
()
Source
Public
Required
.false.
)
})
compute_x
(FunctionType
[]
(Integer 4)
Source
Implementation
()
.false.
.false.
.false.
.false.
.false.
[]
[]
.false.
)
[]
[]
[(=
(Var 3 _lpython_return_variable)
(IntegerBinOp
(IntegerBinOp
(IntegerBinOp
(IntegerConstant 2 (Integer 4))
Mul
(IntegerConstant 3 (Integer 4))
(Integer 4)
(IntegerConstant 6 (Integer 4))
)
Pow
(IntegerConstant 1 (Integer 4))
(Integer 4)
(IntegerConstant 6 (Integer 4))
)
Add
(IntegerConstant 2 (Integer 4))
(Integer 4)
(IntegerConstant 8 (Integer 4))
)
()
)
(Return)]
(Var 3 _lpython_return_variable)
Public
.false.
.false.
()
),
main:
(Function
(SymbolTable
4
{
x:
(Variable
4
x
[]
Local
()
()
Default
(Integer 4)
()
Source
Public
Required
.false.
)
})
main
(FunctionType
[]
()
Source
Implementation
()
.false.
.false.
.false.
.false.
.false.
[]
[]
.false.
)
[compute_x]
[]
[(=
(Var 4 x)
(FunctionCall
2 compute_x
()
[]
(Integer 4)
()
()
)
()
)
(Print
()
[(Var 4 x)]
()
()
)]
()
Public
.false.
.false.
()
)
})
__main__
[]
.false.
.false.
),
main_program:
(Program
(SymbolTable
6
{
__main____global_statements:
(ExternalSymbol
6
__main____global_statements
2 __main____global_statements
__main__
[]
__main____global_statements
Public
)
})
main_program
[__main__]
[(SubroutineCall
6 __main____global_statements
2 __main____global_statements
[]
()
)]
)
})
[]
)
$ lpython examples/expr2.py --show-asr --pass=inline_function_calls,unused_functions
(TranslationUnit
(SymbolTable
1
{
__main__:
(Module
(SymbolTable
2
{
__main____global_statements:
(Function
(SymbolTable
5
{
})
__main____global_statements
(FunctionType
[]
()
Source
Implementation
()
.false.
.false.
.false.
.false.
.false.
[]
[]
.false.
)
[main]
[]
[(SubroutineCall
2 main
()
[]
()
)]
()
Public
.false.
.false.
()
),
main:
(Function
(SymbolTable
4
{
_lpython_return_variable_compute_x:
(Variable
4
_lpython_return_variable_compute_x
[]
Local
()
()
Default
(Integer 4)
()
Source
Public
Required
.false.
),
x:
(Variable
4
x
[]
Local
()
()
Default
(Integer 4)
()
Source
Public
Required
.false.
),
~empty_block:
(Block
(SymbolTable
7
{
})
~empty_block
[]
)
})
main
(FunctionType
[]
()
Source
Implementation
()
.false.
.false.
.false.
.false.
.false.
[]
[]
.false.
)
[]
[]
[(=
(Var 4 _lpython_return_variable_compute_x)
(IntegerBinOp
(IntegerBinOp
(IntegerBinOp
(IntegerConstant 2 (Integer 4))
Mul
(IntegerConstant 3 (Integer 4))
(Integer 4)
(IntegerConstant 6 (Integer 4))
)
Pow
(IntegerConstant 1 (Integer 4))
(Integer 4)
(IntegerConstant 6 (Integer 4))
)
Add
(IntegerConstant 2 (Integer 4))
(Integer 4)
(IntegerConstant 8 (Integer 4))
)
()
)
(GoTo
1
__1
)
(BlockCall
1
4 ~empty_block
)
(=
(Var 4 x)
(Var 4 _lpython_return_variable_compute_x)
()
)
(Print
()
[(Var 4 x)]
()
()
)]
()
Public
.false.
.false.
()
)
})
__main__
[]
.false.
.false.
),
main_program:
(Program
(SymbolTable
6
{
__main____global_statements:
(ExternalSymbol
6
__main____global_statements
2 __main____global_statements
__main__
[]
__main____global_statements
Public
)
})
main_program
[__main__]
[(SubroutineCall
6 __main____global_statements
2 __main____global_statements
[]
()
)]
)
})
[]
)
提前 (AoT) 编译
LPython 自然地充当 Python 编译器。默认情况下,如果未提供任何后端,它会将带有类型注解的用户输入代码编译为 LLVM,LLVM 会生成二进制最终输出。考虑以下小例子:
from lpython import i32, i64
def list_bench(n: i32) -> i64:
x: list[i32]
x = []
i: i32
for i in range(n):
x.append(i)
s: i64 = i64(0)
for i in range(n):
s += i64(x[i])
return s
res: i64 = list_bench(500_000)
print(res)
(lp) 18:58:29:~/lpython_project/lpython % lpython /Users/czgdp1807/lpython_project/debug.py -o a.out
(lp) 18:58:31:~/lpython_project/lpython % time ./a.out
124999750000
./a.out 0.01s user 0.00s system 89% cpu 0.012 total
您可以看到它非常快。通过命令行参数 --backend=c 使用 C 后端仍然非常快:
% time lpython /Users/czgdp1807/lpython_project/debug.py --backend=c
124999750000
lpython /Users/czgdp1807/lpython_project/debug.py --backend=c 0.12s user 0.02s system 100% cpu 0.144 total
请注意,time lpython /Users/czgdp1807/lpython_project/debug.py --backend=c 包括 LPython 的编译时间和二进制文件的执行时间。两者的总和如此之快,以至于人们可以负担得起在每次更改输入文件时进行编译。 :D。
即时编译
LPython 中的即时编译仅需使用 @lpython 修饰 Python 函数。修饰器采用一个选项来指定所需的后端,如 @lpython(backend="c") 或 @lpython(backend="llvm")。目前仅支持 C;LLVM 和其他将在不久的将来添加。修饰器还传播特定于后端的选项。例如
@lpython(backend="c",
backend_optimization_flags=["-ffast-math",
"-funroll-loops",
"-O1"])
请注意,默认情况下,C 后端使用,没有任何优化标志。
LPython 中 JIT 编译的一个小例子(请注意变量的 LPython 类型注解),
from lpython import i32, i64, lpython
@lpython(backend="c", backend_optimisation_flags=["-ffast-math", "-funroll-loops", "-O1"])
def list_bench(n: i32) -> i64:
x: list[i32]
x = []
i: i32
for i in range(n):
x.append(i)
s: i64 = i64(0)
for i in range(n):
s += i64(x[i])
return s
res = list_bench(1) # compiles `list_bench` to a shared binary in the first call
res = list_bench(500_000) # calls the compiled `list_bench`
print(res)
(lp) 18:46:33:~/lpython_project/lpython % python /Users/czgdp1807/lpython_project/debug.py
124999750000
我们将在下面的基准测试中展示 LPython 如何与 Numba 相比,Numba 也具有 JIT 编译。
与 CPython 的互操作性
通过 @pythoncall 修饰器访问使用 CPython 实现的任何库。例如,
email_extractor.py
# get_email is implemented in email_extractor_util.py which is intimated to
# LPython by specifiying the file as module in `@pythoncall` decorator
@pythoncall(module="email_extractor_util")
def get_email(text: str) -> str:
pass
def test():
text: str = "Hello, my email id is lpython@lcompilers.org."
print(get_email(text))
test()
email_extractor_util.py
# Implement `get_email` using `re` CPython library
def get_email(text):
import re
# Regular expression patterns
email_pattern = r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
# Matching email addresses
email_matches = re.findall(email_pattern, text)
return email_matches[0]
(lp) 18:54:13:~/lpython_project % lpython email_extractor.py --backend=c --enable-cpython
lpython@lcompilers.org
注意:目前仅 C 后端支持 @pythoncall 和 @lpython 修饰器,但最终将与 LLVM 后端一起使用,并且正在进行中。
基准测试和演示
在本节中,我们将展示 LPython 在每个 LPython 提供的功能方面的性能与竞争对手相比如何。我们涵盖 JIT 编译、与 CPython 的互操作性和 AoT 编译。
即时 (JIT) 编译
我们将 LPython 的 JIT 编译与 Numba 在 一维数组的所有元素的求和、两个一维数组的逐点乘法、列表上的插入排序 以及 完全连接图上的 Dijkstra 最短路径算法的二次时间实现 方面进行比较。
系统信息
编译器 | 版本 ---|--- Numba | 0.57.1 LPython | 0.19.0 Python | 3.10.4
一维数组的所有元素的求和
from numpy import float64, arange, empty
from lpython import i32, f64, lpython
import timeit
from numba import njit
@lpython(backend="c", backend_optimisation_flags=["-ffast-math", "-funroll-loops", "-O3"])
def fast_sum(n: i32, x: f64[:], res: f64[:]) -> f64:
s: f64 = 0.0
res[0] = 0.0
i: i32
for i in range(n):
s += x[i]
res[0] = s
return s
@njit(fastmath=True)
def fast_sum_numba(n, x, res):
s = 0.0
res[0] = 0.0
for i in range(n):
s += x[i]
res[0] = s
return s
def test():
n = 100_000_000
x = arange(n, dtype=float64)
x1 = arange(0, dtype=float64)
res = empty(1, dtype=float64)
res_numba = empty(1, dtype=float64)
print("LPython compilation time:", timeit.timeit(lambda: fast_sum(0, x1, res), number=1))
print("LPython execution time: ", min(timeit.repeat(lambda: fast_sum(n, x, res), repeat=10, number=1)))
assert res[0] == 4999999950000000.0
print("Numba compilation time:", timeit.timeit(lambda: fast_sum_numba(0, x1, res_numba), number=1))
print("Numba execution time:", min(timeit.repeat(lambda: fast_sum_numba(n, x, res_numba), repeat=10, number=1)))
assert res_numba[0] == 4999999950000000.0
test()
编译器 | 编译时间 (s) | 系统 | 相对值 ---|---|---|--- Numba | 0.10 | Apple M1 MBP 2020 | 1.00 LPython | 0.20 | Apple M1 MBP 2020 | 2.00 Numba | 0.08 | Apple M1 Pro MBP 2021 | 1.00 LPython | 0.53 | Apple M1 Pro MBP 2021 | 6.62 Numba | 0.15 | Apple M1 2020 | 1.00 LPython | 0.40 | Apple M1 2020 | 2.67 Numba | 0.20 | AMD Ryzen 5 2500U (Ubuntu 22.04) | 1.00 LPython | 0.32 | AMD Ryzen 5 2500U (Ubuntu 22.04) | 1.60
编译器 | 执行时间 (s) | 系统 | 相对值 ---|---|---|--- LPython | 0.013 | Apple M1 MBP 2020 | 1.00 Numba | 0.024 | Apple M1 MBP 2020 | 1.84 LPython | 0.013 | Apple M1 Pro MBP 2021 | 1.00 Numba | 0.023 | Apple M1 Pro MBP 2021 | 1.77 LPython | 0.014 | Apple M1 2020 | 1.00 Numba | 0.024 | Apple M1 2020 | 1.71 LPython | 0.048 | AMD Ryzen 5 2500U (Ubuntu 22.04) | 1.00 Numba | 0.048 | AMD Ryzen 5 2500U (Ubuntu 22.04) | 1.00
两个一维数组的逐点乘法
from numpy import int64, arange, empty
from lpython import i32, i64, lpython
import timeit
from numba import njit
@lpython(backend="c", backend_optimisation_flags=["-ffast-math", "-funroll-loops", "-O3"])
def multiply_arrays(n: i32, x: i64[:], y: i64[:], z: i64[:]):
i: i32
for i in range(n):
z[i] = x[i] * y[i]
@njit(fastmath=True)
def multiply_arrays_numba(n, x, y, z):
for i in range(n):
z[i] = x[i] * y[i]
def test():
n = 100_000_000
x1 = arange(0, dtype=int64)
y1 = arange(0, dtype=int64)
res1 = arange(0, dtype=int64)
x = arange(n, dtype=int64)
y = arange(n, dtype=int64) + 2
res = empty(n, dtype=int64)
res_numba = empty(n, dtype=int64)
print("LPython compilation time:", timeit.timeit(lambda: multiply_arrays(0, x1, y1, res1), number=1))
print("LPython execution time:", min(timeit.repeat(lambda: multiply_arrays(n, x, y, res), repeat=10, number=1)))
assert sum(res - x * y) == 0
print("Numba compilation time:", timeit.timeit(lambda: multiply_arrays_numba(0, x1, y1, res1), number=1))
print("Numba execution time:", min(timeit.repeat(lambda: multiply_arrays_numba(n, x, y, res_numba), repeat=10, number=1)))
assert sum(res_numba - x * y) == 0
test()
编译器 | 编译时间 (s) | 系统 | 相对值 ---|---|---|--- Numba | 0.11 | Apple M1 MBP 2020 | 1.00 LPython | 0.50 | Apple M1 MBP 2020 | 4.54 Numba | 0.09 | Apple M1 Pro MBP 2021 | 1.00 LPython | 0.60 | Apple M1 Pro MBP 2021 | 6.67 Numba | 0.11 | Apple M1 2020 | 1.00 LPython | 0.46 | Apple M1 2020 | 4.18 Numba | 0.21 | AMD Ryzen 5 2500U (Ubuntu 22.04) | 1.00 LPython | 0.31 | AMD Ryzen 5 2500U (Ubuntu 22.04) | 1.48
编译器 | 执行时间 (s) | 系统 | 相对值 ---|---|---|--- Numba | 0.041 | Apple M1 MBP 2020 | 1.00 LPython | 0.042 | Apple M1 MBP 2020 | 1.02 Numba | 0.037 | Apple M1 Pro MBP 2021 | 1.00 LPython | 0.040 | Apple M1 Pro MBP 2021 | 1.08 Numba | 0.042 | Apple M1 2020 | 1.00 LPython | 0.042 | Apple M1 2020 | 1.00 Numba | 0.21 | AMD Ryzen 5 2500U (Ubuntu 22.04) | 1.00 LPython | 0.21 | AMD Ryzen 5 2500U (Ubuntu 22.04) | 1.00
列表上的插入排序
from lpython import i32, lpython
import timeit
from numba import njit
@lpython(backend="c", backend_optimisation_flags=["-ffast-math", "-funroll-loops", "-O3"])
def test_list_sort(size: i32):
i: i32
x: list[i32]
x = []
for i in range(size):
x.append(size - i)
for i in range(1, size):
key: i32 = x[i]
j: i32 = i - 1
while j >= 0 and key < x[j] :
x[j + 1] = x[j]
j -= 1
x[j + 1] = key
for i in range(1, size):
assert x[i - 1] < x[i]
@njit(fastmath=True)
def test_list_sort_numba(size):
x = []
for i in range(size):
x.append(size - i)
for i in range(1, size):
key = x[i]
j = i - 1
while j >= 0 and key < x[j] :
x[j + 1] = x[j]
j -= 1
x[j + 1] = key
for i in range(1, size):
assert x[i - 1] < x[i]
def test():
n = 25000
print("LPython compilation time:", timeit.timeit(lambda: test_list_sort(0), number=1))
print("LPython execution time:", min(timeit.