利用生成式AI将3D可购物产品带到线上
Bringing 3D shoppable products online with generative AI
2025年5月12日 Steve Seitz, Google Labs 杰出科学家 了解我们最新的AI模型如何将2D产品图像转化为沉浸式3D体验,为在线购物者服务。
每天,数十亿人在网上购物,希望能够复刻店内购物的最佳体验。看到吸引眼球的商品,拿起并亲自检查,是我们与产品建立联系的关键环节。然而,捕捉到实体店那种直观、亲身体验的感觉,并将其在屏幕上完美复现,是充满挑战的。我们知道技术可以帮助弥合这一差距,通过快速滚动屏幕,将关键细节展现在你的指尖。但是,对于企业来说,大规模创建这些在线工具的成本可能很高,而且耗时。
为了解决这个问题,我们开发了新的生成式AI技术,仅需三张产品图像,即可创建高质量且可用于购物的3D产品可视化效果。今天,我们很高兴分享最新的进展,它由 Google 最先进的视频生成模型 Veo 提供支持。这项技术已经可以在 Google Shopping 上为各种产品类别生成交互式3D视图。
[播放静音循环视频] [暂停静音循环视频]
由照片生成的3D产品可视化示例。
第一代: Neural Radiance Fields (NeRFs)
2022年,来自 Google 的研究人员齐心协力开发技术,使产品可视化更具沉浸感。最初的重点是使用 Neural Radiance Fields (NeRF) 学习产品的3D表示,以便从五个或更多产品图像中渲染新的视角(即,新视角合成),例如360°旋转。这需要解决许多子问题,包括选择信息量最大的图像、移除不需要的背景、预测3D先验、从一组稀疏的以对象为中心的图像中估计相机位置,以及优化产品的3D表示。
同年,我们 宣布 了这项突破,并发布了第一个里程碑:Google Search 上的交互式360°鞋类可视化。虽然这项技术前景广阔,但它受到噪声输入信号(例如,不准确的相机姿势)和来自稀疏输入视角的模糊性的影响。在尝试重建凉鞋和高跟鞋时,这一挑战变得非常明显,因为它们的细薄结构和更复杂的几何形状很难仅从少数图像中重建。
这让我们开始思考:生成式扩散模型最近的进展能否帮助我们改进学习到的3D表示?

我们的第一代方法使用神经辐射场 (NeRF) 来渲染新视角,结合了多种3D技术,例如 NOCS 用于XYZ预测, CamP 用于相机优化,以及 Zip-NeRF 用于从稀疏视角集进行最先进的新视角合成。
第二代: 通过视角条件扩散先验进行扩展
2023年,我们引入了第二代方法,该方法使用视角条件扩散先验来解决第一代方法的局限性。所谓“视角条件”是指,你可以给它一张鞋子顶部的图像,然后询问模型“这只鞋子的正面是什么样的?”。这样,我们可以使用视角条件扩散模型来帮助预测从任何视点看到的鞋子是什么样的,即使我们只有有限视点的照片。
在实践中,我们采用了一种称为_分数蒸馏采样_ (SDS) 的变体,该方法最初在 DreamFusion 中提出。在训练过程中,我们从随机相机视角渲染3D模型。然后,我们使用视角条件扩散模型和可用的姿势图像,从相同的相机视角生成目标图像。最后,我们通过比较渲染图像和生成的目标图像来计算得分。该分数直接为优化过程提供信息,从而优化3D模型的参数并提高其质量和真实感。
这种第二代方法带来了显著的扩展优势,使我们能够为 Google Shopping 上每天浏览的许多鞋子生成3D表示。今天,当你在 Google 上购物时,你可以找到凉鞋、高跟鞋、靴子和其他鞋类类别的交互式360°可视化效果,其中大部分都是通过这项技术创建的!
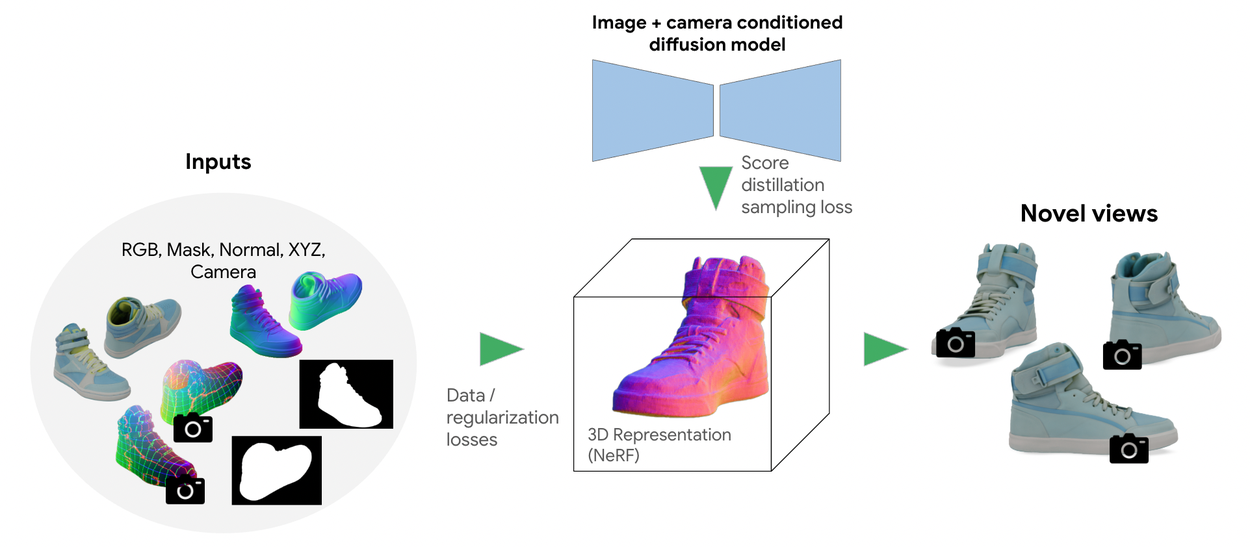
第二代方法使用基于 TryOn 架构的视角条件扩散模型。扩散模型充当学习到的先验,使用在 DreamFusion 中提出的分数蒸馏采样来提高新视角的质量和逼真度。
第三代: 通过 Veo 进行泛化
我们最新的突破建立在 Google 最先进的视频生成模型 Veo 之上。Veo 的一个关键优势是它能够生成捕捉光线、材料、纹理和几何形状之间复杂交互的视频。其强大的基于扩散的架构及其在各种多模态任务上进行微调的能力使其擅长新视角合成。
为了微调 Veo,将其用于将产品图像转换为一致的360°视频,我们首先策划了一个包含数百万高质量3D合成资产的数据集。然后,我们从各种相机角度和光照条件下渲染3D资产。最后,我们创建了一个配对图像和视频的数据集,并监督 Veo 生成以一个或多个图像为条件的360°旋转视频。
我们发现这种方法可以有效地推广到各种产品类别,包括家具、服装、电子产品等。Veo 不仅能够生成符合可用产品图像的新视角,而且还能够捕捉复杂的光照和材料交互(即,有光泽的表面),这对于第一代和第二代方法来说都具有挑战性。
[播放静音循环视频] [暂停静音循环视频]
第三代方法建立在 Veo 之上,可以从一个或多个产品图像生成360°旋转视频。
此外,第三代方法避免了从一组稀疏的以对象为中心的产品图像中估计精确相机姿势的需求,从而简化了问题并提高了可靠性。微调后的 Veo 方法非常强大——只需一张图像,你就可以生成对象的逼真3D表示。但是,与任何生成式3D技术一样,Veo 需要从不可见的视角中推断细节,例如,当只有正面视图可用时,需要推断对象的背面。随着输入图像数量的增加,Veo 生成高保真、高质量新视角的能力也会提高。在实践中,我们发现,仅需三张捕捉大多数对象表面的图像就足以提高3D图像的质量并减少幻觉。
结论和未来展望
在过去的几年里,3D生成式AI取得了巨大的进展,从 NeRF 到视角条件扩散模型,再到现在的 Veo。每项技术都在使在线购物感觉更真实、更具互动性方面发挥了关键作用。展望未来,我们很高兴能够继续突破这个领域的界限,并帮助我们的用户使在线购物变得越来越令人愉快、信息丰富且引人入胜。
致谢
这项工作得益于 Philipp Henzler、Matthew Burruss、Matthew Levine、Laurie Zhang、Ke Yu、Chung-Yi Weng、Jason Y. Zhang、Changchang Wu、Ira Kemelmacher-Shlizerman、Carlos Hernandez、Keunhong Park 和 Ricardo Martin-Brualla 的共同努力。我们感谢来自 Google Labs、Google DeepMind 和 Google Shopping 的 Aleksander Holynski、Ben Poole、Jon Barron、Pratul Srinivasan、Howard Zhou、Federico Tombari 以及更多人的支持。
标签:
其他相关文章
- [
 2025年5月14日 深入了解检索增强生成:充分上下文的作用
2025年5月14日 深入了解检索增强生成:充分上下文的作用
- Data Mining & Modeling ·
- Generative AI ·
- Machine Intelligence ](https://research.google/blog/deeper-insights-into-retrieval-augmented-generation-the-role-of-sufficient-context/>)
- [
 2025年5月6日 使复杂文本易于理解:使用 Gemini 进行最小损失的文本简化
2025年5月6日 使复杂文本易于理解:使用 Gemini 进行最小损失的文本简化
- Generative AI ·
- Health & Bioscience ·
- Product ](https://research.google/blog/making-complex-text-understandable-minimally-lossy-text-simplification-with-gemini/>)
- [
 2025年5月2日 Amplify Initiative:用于全球化AI的本地化数据
2025年5月2日 Amplify Initiative:用于全球化AI的本地化数据
- Generative AI ·
- Global ·
- Open Source Models & Datasets ·
- Responsible AI ](https://research.google/blog/amplify-initiative-localized-data-for-globalized-ai/>)
关注我们