Vibe Coding 的反向激励
Vibe Coding 的反向激励

我使用像 Claude Code 这样的 AI 代码助手已经有一段时间了,我想说(请原谅那些有药物滥用问题的人),我可能上瘾了。 而且这真是一个昂贵的习惯。
它那种“差一点就成了”的特性 —— 感觉我们离完美的解决方案只差一个 prompt —— 使它如此令人上瘾。Vibe coding 遵循变动比率强化原则,这是一种强大的操作性条件反射形式,奖励的出现是不可预测的。与固定的奖励不同,这种间歇性的成功模式(“代码有效!太棒了!它刚刚崩溃了!wtf!”),会触发我们大脑奖励通路中更强的多巴胺反应,类似于赌博行为。
AI 使这一点特别有效的原因在于,它只需要付出最小的努力就能获得潜在的巨大回报 —— 创造了神经科学家所说的“努力折扣”优势。再加上我们天生的完成偏见 —— 完成我们已经开始的任务的驱动力 —— 这就形成了一个引人注目的心理循环,让我们不断地尝试 prompt。
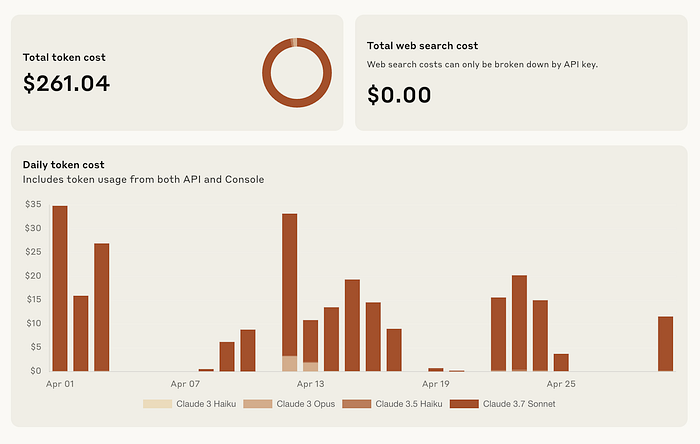 我不抽烟,但这些条形图看起来不像香烟吗?
我不抽烟,但这些条形图看起来不像香烟吗?
自从 Claude Code 发布以来,我可能已经花费了超过 1000 美元来进行 vibe coding,将各种项目变成现实(其中一些我希望很快宣布,别担心)。
但让我们也谈谈费用,因为我认为这里面也有一些不好的东西:编码代理,特别是 Claude 3.7(Claude Code 的后端),倾向于编写_太多_的代码,这种现象最终会使用户付出比应有的更多的成本。
经验丰富的开发人员可能会用几行优雅的代码和一个经过深思熟虑的函数式方法来解决问题,但这些 AI 系统通常会产生冗长、过度设计的解决方案,这些解决方案以增量方式解决问题,而不是从根本上解决问题。
我最初的反应是将此归因于 LLM 的相对不成熟以及它们在推理抽象逻辑问题时的局限性。由于这些模型主要经过训练,可以根据它们以前见过的模式来预测和生成文本,因此它们可能难以进行更深层次的架构思考,而这种思考会带来优雅、最简的解决方案,这是有道理的。
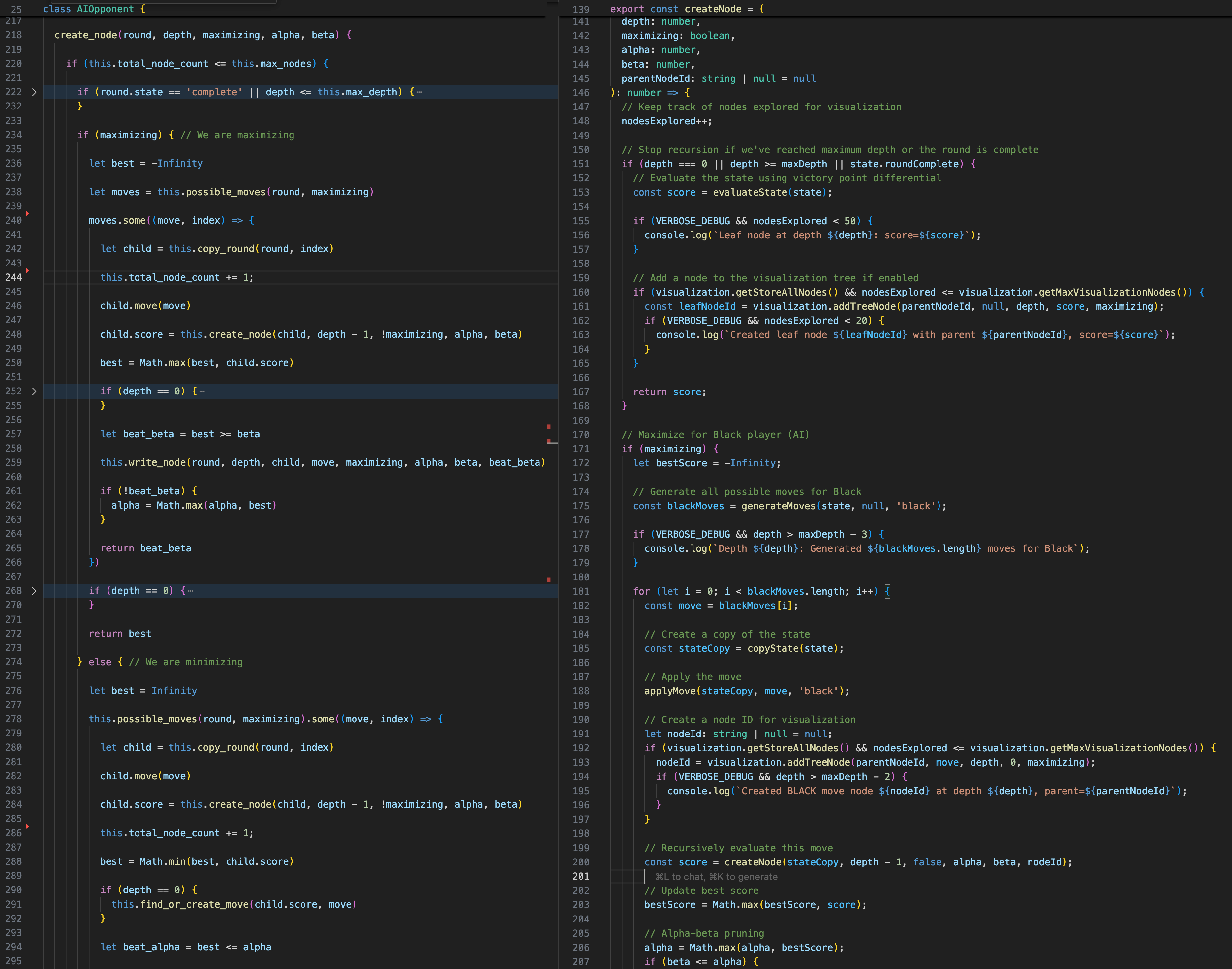 左边是我编写的代码,右边是 Claude Code 实现的相同算法
左边是我编写的代码,右边是 Claude Code 实现的相同算法
事实上,我交给它们的极其复杂的任务大多以失败告终:在新颖的纸牌游戏中实现极小化极大算法,在 CSS 中制作精美的动画,完全重构代码库。在思考解决计算机科学难题所需的高级原则时,LLM 经常迷失方向。
在上面的例子中,我于 2018 年实现的极小化极大算法总共 400 行代码,而 Claude Code 的版本有 627 行。LLM 版本还需要近十几个其他库文件。诚然,此版本是用 TypeScript 编写的,并且有很多额外的花里胡哨的东西,其中一些是我明确要求的,但真正的问题是:它实际上不起作用。此外,使用 LLM 对其进行调试需要每次我想全面调试时都将膨胀的代码发送回 API。
为了给用户留下深刻印象并超额完成任务,LLM 最终会创建一个由超防御代码组成的乱七八糟的东西,其中充斥着调试语句、神经质的注释和几乎没用的辅助函数。如果你曾经在一个高度函数式的生产代码库中工作过,这足以让你发疯。
我认为每个花时间进行 vibe coding 的人都最终会发现类似的东西,并意识到与向员工工程师下达功能级项目相比,制定一个由可以向初级开发人员解释的离散任务组成的计划更有价值。
还有一种可能性是,LLM 接受过训练的大部分代码往往不够优雅且过于冗长。天知道那里有很多 AbstractJavaFinalSerializedFactory 代码。
但我开始认为这个问题更加深入,而且与 AI 辅助的经济学有关。
经济激励问题
许多 AI 代码助手,包括 Claude Code,都按 token 数量收费 —— 本质上是处理和生成的文本量。这创造了经济学家所说的“反向激励” —— 一种产生与实际期望相反的行为的激励。
让我们分解一下它是如何运作的:
- AI 为给定的任务生成冗长的、程序性的代码
- 当你要求进一步的更改或添加时,此代码将成为上下文的一部分(这是关键)
- AI 现在必须读取(并且你为此付费)每次后续交互中的冗长代码
- 处理的 token 越多 = AI 背后的公司收入越多
- LLM 开发人员没有动力“修复”冗长代码问题,因为这样做会显著影响他们的利润
正如厄普顿·辛克莱 (Upton Sinclair) 的名言:“当一个人的薪水取决于他不理解某件事时,很难让他理解这件事。” 同样,当 AI 公司的收入取决于 token 数量时,它们可能难以优先考虑代码简洁性。
更广泛的影响
这种模式指向 AI 开发中一个更普遍的担忧:系统货币化方式与系统满足用户需求的程度之间的一致性。当按 token 数量收费时,自然就减少了优化优雅、最简解决方案的动力。
即使是“吃到饱”的订阅计划(例如,Claude 的“Max”订阅)也无法完全解决这种紧张关系,因为它们通常带有使用上限或其他限制,以维持底层激励结构。
系统指令和冗长性之间的权衡
AI 代码生成中的反向激励指向一个更根本的问题,这个问题超出了代码助手的范围。Louise 在阅读本文草稿时指出,Giskard AI 的 Phare 基准测试中的一些最新研究揭示了一种令人不安的模式,这种模式反映了我们的编码困境:要求更短的回复会危及答案的准确性。
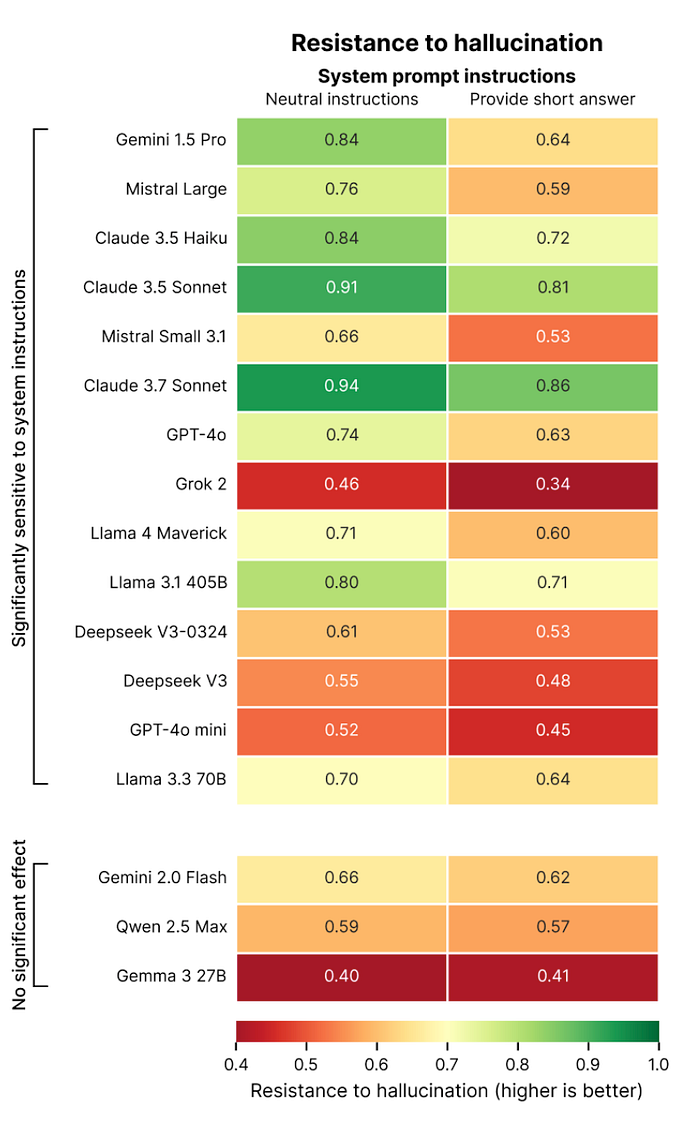
根据他们的研究结果,强调简洁性(例如“简要回答这个问题”)的指令会显著降低大多数测试模型的实际可靠性 —— 在某些情况下,会导致抗幻觉能力下降 20%。当被迫简洁时,模型面临一个不可能的选择:捏造简短但不准确的答案,或者拒绝问题而显得无益。数据显示,当给出这些约束时,模型始终优先考虑简洁性而不是准确性。
显然,LLM 越冗长,效果就越好。考虑到思维链推理可以提高准确性,这实际上是有道理的,但是当涉及到这些几乎神奇的系统时,这个问题已经开始感觉像是一个真正的权衡。
我们每天都在代码生成中看到这种完全相同的紧张关系。当我们优化简洁性并要求以更少的步骤解决问题时,我们经常会牺牲质量。不同之处在于,在编码中,这种牺牲表现为过度设计的冗长 ——模型会生成更多的 token,以涵盖所有可能的边缘情况,而不是深入思考优雅的核心解决方案或根本原因问题。 在这两种情况下,经济激励(token 优化)都与高质量结果(事实准确性或优雅代码)背道而驰。
正如 Phare 的研究表明,看似无辜的 prompt(例如“简洁”)会破坏模型揭穿虚假信息的能力一样,我们的经验表明,标准的 prompting 方法可能会产生臃肿、低效的代码。在这两个领域中,token 经济学和质量输出之间的根本错位会产生持久的紧张关系,用户必须积极管理。
管理这些反向激励的一些技巧
在我们等待 AI 公司更好地将其激励与我们对优雅代码的需求对齐的同时,我已经制定了几种策略来抵消冗长的代码生成:
1. 在实施之前强制规划
我不断地要求 LLM 在生成任何代码之前编写详细的计划。这迫使模型思考架构和方法,而不是直接深入到实现细节中。通常,我发现一个精心设计的计划可以带来更简洁的代码,因为模型在编写单行代码之前就已经解决了解决方案的逻辑结构。
2. 明确的权限协议
我在我的工作流程中实施了一个严格的“在生成之前询问”协议。我的个人 CLAUDE.md 文件明确指示 Claude 在编写任何代码之前请求权限。令人恼火的是,Claude Code 经常忽略这一点,可能是由于它庞大的系统提示 中谈论太多关于编写代码的内容,以至于它覆盖了我的偏好。强制执行此边界并反复强调它(“记住,不要编写任何代码”)有助于防止自动生成不需要的冗长解决方案。
3. 基于 Git 的实验和无情的修剪
当使用 AI 生成的代码时,版本控制变得至关重要。当我到达“好的,它可以按预期工作”的时刻时,我经常在 git 中对代码进行基准测试。创建实验分支也很有帮助。最重要的是,当修复它们需要比从头开始更多的工作时,我已准备好完全抛弃分支。这种放弃沉没成本的意愿非常重要 —— 它可以帮助我解决问题并弄清楚 AI 的问题,同时防止在根本有缺陷的方法之上积累权宜之计的解决方案。
4. 使用更便宜的模型
有时,最简单的解决方案效果最好:使用更小、更便宜的模型通常会导致更直接的解决方案。这些模型倾向于生成较少的冗长代码,仅仅是因为它们具有有限的上下文窗口和处理能力。虽然它们可能无法很好地处理极其复杂的问题,但对于许多日常编码任务来说,它们的约束实际上可以产生更优雅的解决方案。例如,Claude 3.5 Haiku 目前的价格是 Claude 3.7 的 26%(每个 token 0.80 美元,而 Claude 3.7 为 3 美元)。此外,Claude 3.7 似乎比 Claude 3.5 更频繁地进行过度设计。
朝着更好的对齐方向发展
更好的方法是什么样的?
- LLM 编码代理可以根据代码质量指标而不是仅仅是 token 数量进行评估和激励。这里的挑战在于这种指标非常主观。
- 公司可以提供奖励效率而不是冗长性的定价模式(我不知道这会如何运作,这是 Claude 的愚蠢想法)
- LLM 训练应包含反馈机制,通过 RLHF 具体促进简洁、优雅的解决方案(例如,向开发人员展示同一代码的多个版本并让他们选择最佳版本,也许这已经在发生)
- 公司意识到过度冗长的代码生成对他们的利润不利(例如,Sam Altman 承认 用户对 ChatGPT 说“请”和“谢谢”让他们损失了数百万美元)
这不仅仅是为了获得更好的 AI —— 而是为了确保推动 AI 发展的经济激励与我们作为开发人员真正重视的东西对齐:干净、可维护、优雅的代码,从根本上解决问题。
在那之前,别忘了:简洁是智慧的灵魂,而机器没有灵魂。
感谢 Louise Macfadyen ,Justin Kazmark 和 Bethany Crystal 阅读并建议编辑此草稿。 — - PS: 是的,我使用 Claude 来帮助撰写这篇批评 AI 冗长的文章。这里有一个有趣的讽刺意味:这些系统会很乐意帮助你阐明为什么它们可能会敲诈你。它们愿意steelman 反对自身经济利益的论点表明,反向激励不是嵌入在模型本身中,而是嵌入在围绕它们的业务决策中。换句话说,不要责怪 AI —— 责怪优化收入模型的人。机器只是在做它们被告知的事情,即使这包括解释它们如何被告知做太多的事情。