迁移到 Postgres 的实践
Migrating to Postgres
自从 2022 年初,Motion 开始使用 CockroachDB。 Cockroach 具有许多优点:轻松的水平扩展,尤其是在处理多区域设置时,极高的可用性,以及 SQL 兼容的接口。 早期,我们担心多区域设置(GDPR 强制要求)的最终实现,以及在 Postgres 上的传统设置将如何扩展。
然而,随着 Motion 的发展,我们的使用量和成本也随之增加。 到了 2024 年,Motion 的 CockroachDB 账单增长了 5 倍,达到了六位数的中等水平,并且开始出现一些问题。 我们的客户还没有要求数据本地化,而且我们仍然在单个区域进行相当简单的事务查询——那么为什么要支付分布式数据库的成本呢?
幸运的是,我们有一个 ORM,这使得进行直接对比测试变得相对容易。
Migrations
随着数据库规模的增长,我们经常遇到在应用 migrations 时,Prisma 直接超时的情况。 然后,我们不得不登录 Cockroach 并手动逐个运行 migrations,当然是并发运行。
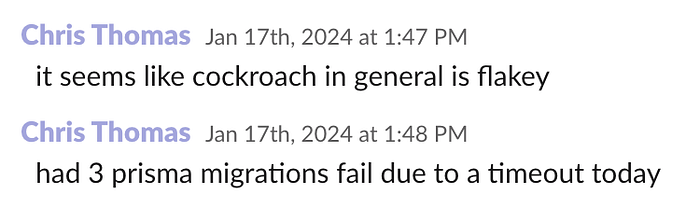
部署被阻止了大约 2 个小时,因为我们正在弄清楚为什么 Cockroach 会超时
当我最终将我们迁移到 Postgres 时,我测试了一个非常相似的迁移(列名不同,只是为了演示目的)。 这是 Postgres 在数据库的重绕实例上(为了控制数据大小)应用此迁移,仅用了 十秒。
在 TeamMember 表中添加一个新的 "foobar" 列并运行 Prisma 迁移。
超时导致了操作上的shortcuts。 到了 2024 年,超时变得非常严重,以至于即使是非常强大的开发人员,也完全出于对锁定整个系统的恐惧,而积极地在数据库之外进行操作。
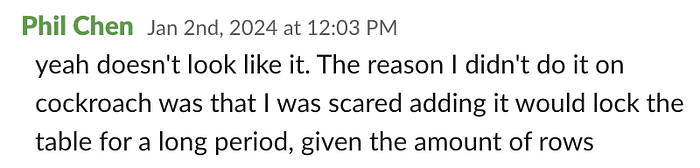
更糟糕的是,迁移问题也成为了升级 Cockroach 版本的阻碍。 我们停留在版本 22,远远超过了生命周期,这使得支持的回复_更加缓慢_。
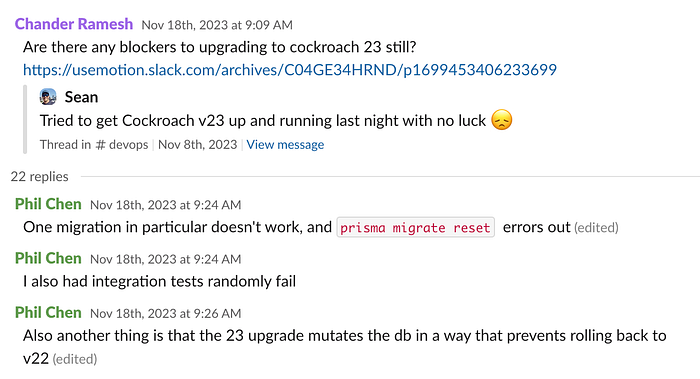
最终,我们放弃了,选择迁移到 Postgres,并一直停留在已停止维护的版本 22 上,直到迁移完成。
ETL
超时也开始影响 migrations 之外的事情——即 ETL。
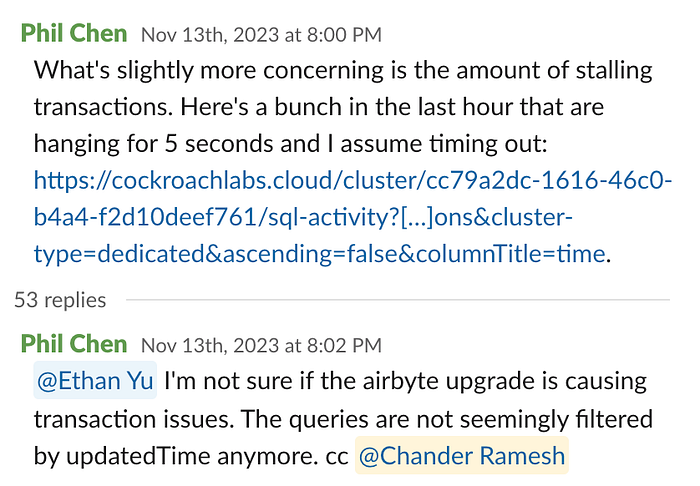
来自 Airbyte 停止的典型错误
我们已经习惯于醒来后看到这样的页面:
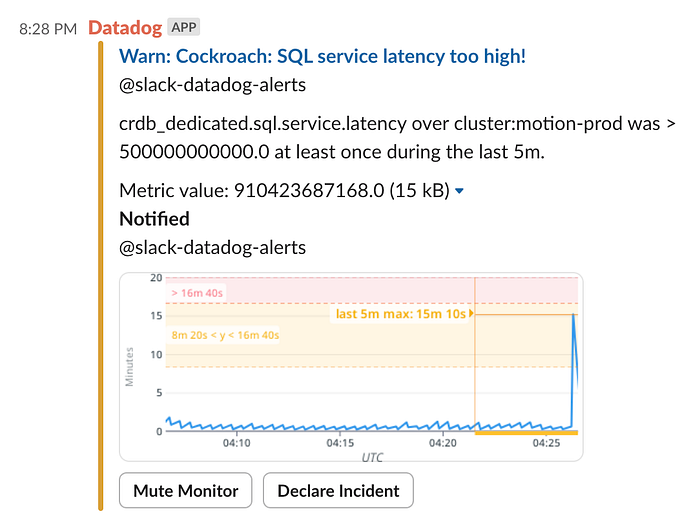
即使 ETL 作业正常工作并且没有超时,性能也_非常糟糕_。
不幸的是,对于提供 CRDB 复制的任何真正的 ETL 解决方案,几乎没有支持。 截至撰写本文时,仍然只有 Airbyte 的连接器(在 2024 年处于 alpha 阶段),并且我们在实施后才发现该连接器存在内存泄漏。
Query Speeds
Query 的直接对比测试很有趣。 由于它们的优化器,某些 query 在 Cockroach 上的速度确实更快:
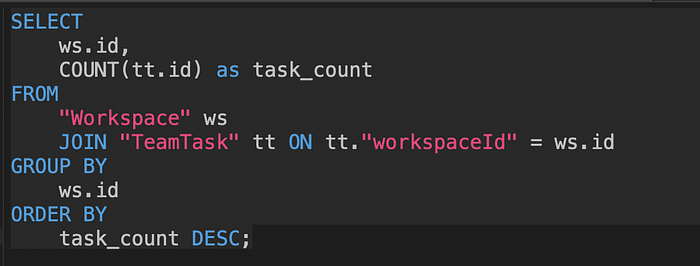
Cockroach 更快的示例 Query
对于上述 Query,Cockroach 会在约 13 秒内解决,而 Postgres 最多需要 20 秒。 似乎 Cockroach query planner 本身理解这些 query 并在 Postgres 天真地结束执行近乎全表扫描时执行聚合。 (当比较 Drizzle 而不是 Prisma 生成的 SQL 时,此优势似乎消失了。更多内容将在另一篇博客文章中介绍。)
但是,在很多情况下,Cockroach query planner 的 "魔力" 似乎适得其反。 这是 Prisma 代码和生成的 SQL,Cockroach 选择执行全表扫描,而 Postgres 则不:
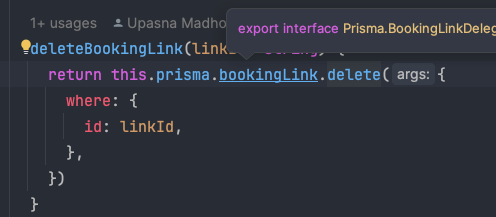
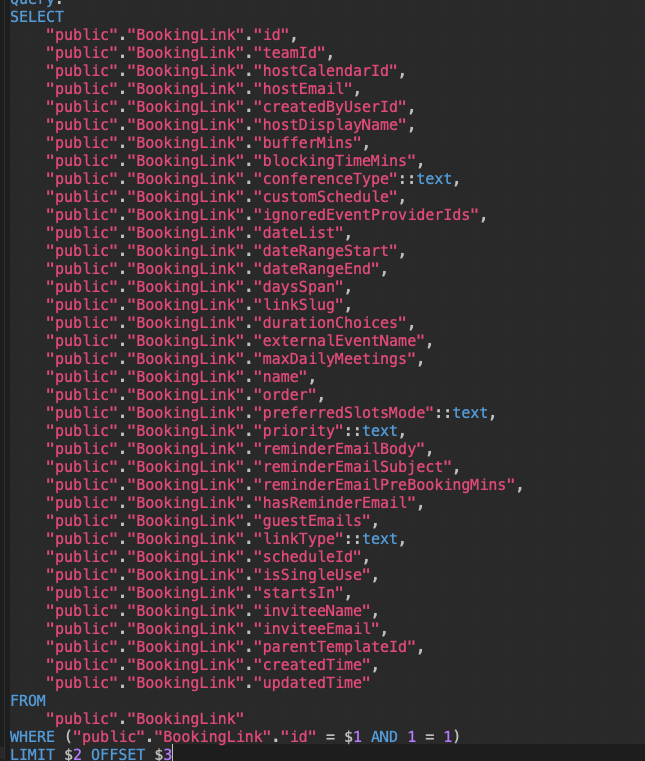
Typescript 代码和 Prisma 生成的相应 SQL 怪物。

请注意末尾的 AND 1=1,导致扫描整个表
我们_绝大多数_的真实 Query 似乎都遵循这种通用模式,其中 Prisma 生成非常复杂的 SQL,其中包含各种列和 join。 这,加上神奇的 Cockroach 优化器,最终导致了极高的延迟。 这是一个真实的例子,Postgres 中的 Query 比 Cockroach 快 二十倍。
SELECT "teamTasks"."id", "teamTasks"."name", "teamTasks"."description", "teamTasks"."dueDate", "teamTasks"."duration", "teamTasks"."completedTime", "teamTasks"."assigneeUserId", "teamTasks"."priorityLevel", "teamTasks"."statusId", "teamTasks"."projectId", "teamTasks"."createdByUserId", "teamTasks"."createdTime", "teamTasks"."updatedTime", "teamTasks"."lastInteractedTime", "teamTasks"."archivedTime", "teamTasks"."workspaceId", "teamTasks"."minimumDuration", "teamTasks"."scheduledStart", "teamTasks"."scheduledEnd", "teamTasks"."startDate", "teamTasks"."isChunkedTask", "teamTasks"."isUnfit", "teamTasks"."type", "teamTasks"."needsReschedule", "teamTasks"."deadlineType", "teamTasks"."schedule", "teamTasks"."parentChunkTaskId", "teamTasks"."parentRecurringTaskId", "teamTasks"."rank", "teamTasks"."isFixedTimeTask", "teamTasks"."slug", "teamTasks"."previousSlugs", "teamTasks"."endDate", "teamTasks"."isBusy", "teamTasks"."isAutoScheduled", "teamTasks"."ignoreWarnOnPastDue", "teamTasks"."scheduleOverridden", "teamTasks"."snoozeUntil", "teamTasks"."manuallyStarted", "teamTasks_chunks"."data" AS "chunks", "teamTasks_labels"."data" AS "labels", "teamTasks_blockedTasks"."data" AS "blockedTasks", "teamTasks_blockingTasks"."data" AS "blockingTasks"FROM "TeamTask" "teamTasks" LEFT JOIN LATERAL ( SELECT coalesce(json_agg(json_build_array("teamTasks_chunks"."id")), '[]'::json) AS "data" FROM "TeamTask" "teamTasks_chunks" WHERE "teamTasks_chunks"."parentChunkTaskId" = "teamTasks"."id") "teamTasks_chunks" ON TRUE LEFT JOIN LATERAL ( SELECT coalesce(json_agg(json_build_array("teamTasks_labels"."labelId")), '[]'::json) AS "data" FROM "TeamTaskLabel" "teamTasks_labels" WHERE "teamTasks_labels"."taskId" = "teamTasks"."id") "teamTasks_labels" ON TRUE LEFT JOIN LATERAL ( SELECT coalesce(json_agg(json_build_array("teamTasks_blockedTasks"."blockingId")), '[]'::json) AS "data" FROM "TeamTaskBlocker" "teamTasks_blockedTasks" WHERE "teamTasks_blockedTasks"."blockedId" = "teamTasks"."id") "teamTasks_blockedTasks" ON TRUE LEFT JOIN LATERAL ( SELECT coalesce(json_agg(json_build_array("teamTasks_blockingTasks"."blockedId")), '[]'::json) AS "data" FROM "TeamTaskBlocker" "teamTasks_blockingTasks" WHERE "teamTasks_blockingTasks"."blockingId" = "teamTasks"."id") "teamTasks_blockingTasks" ON TRUEWHERE ("teamTasks"."workspaceId" in( SELECT "workspaceId" FROM "WorkspaceMember" WHERE ("WorkspaceMember"."userId" = '{{user_id}}' AND "WorkspaceMember"."deletedTime" IS NULL)) and("teamTasks"."workspaceId" in('{{workspace_id}}') and("teamTasks"."id" in( SELECT "taskId" FROM "TeamTaskLabel" WHERE "TeamTaskLabel"."labelId" in('{{label_id}}')) OR "teamTasks"."id" NOT in( SELECT "taskId" FROM "TeamTaskLabel")) AND "teamTasks"."archivedTime" IS NULL AND "teamTasks"."completedTime" IS NULL))
我们在 Team Tasks 表上的大多数 Query,平均而言,在 Cockroach 上的速度比 Postgres 慢_三倍_。
UI/UX Issues
在整个过程中,我们还遇到了一些 UI 问题。
- 未使用的 Indices
未使用的 indices 的 UI 会显示大部分已使用的 indices,这经常导致开发人员的困惑。 我们一直没有弄清楚这是否是因为我们使用了 Prisma。

Cockroach 的建议列表,建议开发人员删除仍在使用的索引
- 取消正在运行的 Query
到目前为止,我们知道在 Cockroach 上运行开销很大的 Query 是_非常_可怕的。 但由于它是一个分布式集群,因此取消 Query 并不那么简单。 使用 Postgres,您只需在 TablePlus(或您喜欢的 SQL 客户端)上点击取消即可。 在 Cockroach 上,您实际上必须登录到控制台并取消 Query,并祈祷所有节点在崩溃之前取消。 (至少有一次,他们没有。您可能可以猜到发生了什么。) 3. Support
首先,support 门户是一个完全不同的网站,它与主门户不共享身份验证。 其次,您必须重新输入他们已经了解您的很多数据(集群 ID 等)。 并且在他们回复时,通常已经过了一个星期。 通常这没问题,但是一旦他们推出了一个 bug,当然会立即让我们崩溃。 那时_不是_登录到单独的门户并输入琐碎细节的时候。
VPC Issues
在我们使用 Cockroach 的两年多时间里,我们经常遇到周期性的 Tailscale 连接问题。
getaddrinfo ENOTFOUND internal-motion-dev-2022-10-grc.gcp-us-central1.cockroachlabs.cloudPrismaClientInitializationError: Can't reach database server at 'internal-motion-prod-gnp.gcp-us-central1.cockroachlabs.cloud':'26257'
无论我们做什么,这些问题都会突然出现,并在一个小时后又突然消失。 这些问题在每个环境中都存在(Airbyte 连接器、CI 和我们本地的 TablePlus 客户端)。 我们从未解决它,并且从未在 Postgres 中遇到过类似的问题。
The Migration
到 2024 年 1 月,我们最大的表大约有 1 亿行。 如前所述,虽然有很多工具可以_将_数据导入 Cockroach,但除了一个非常 alpha 版本的 Airbyte 连接器(由于内存泄漏而一直超时)之外,没有其他 ETL 工具。
所以我决定构建一个自定义的 ETL 解决方案。
大约在这个时候,Bun 越来越受欢迎,因此这次迁移成为了满足我的好奇心的一个方便的借口。 Bun 脚本大致执行以下步骤:
- 读取数据库模式及其所有表信息
- 将每个表的数据转储到磁盘上的专用文件中
- 为我们模式中的每个表生成一个 Bun child process
- 然后,每个子进程将启动从该表转储数据的数据的流式连接
- 该流只是表中所有行的 CSV 流
- 我们流的 "sink" 只会将行插入到 Postgres 中
我相对较快地到达了这一点,并且应该知道这太顺利了。 直到我开始在我们的生产数据库上运行测试迁移时,我才了解到 Cockroach 在 JSON 和数组列中使用了略有不同的字节编码,而 Postgres 则没有。 在接下来的几周中,我使用 Csv-js 组装了一个自定义的 CSV 解析管道,以将所有数据从 Cockroach 转换为与 Postgres 兼容的东西,并且从用户的角度来看也是相同的。
当迁移之夜到来时,我启动了我能得到的最大的 GCP VM(128 核 VM),打开了 Motion 的维护模式,然后开始了迁移。 从开始到结束,生产迁移脚本运行整个数据库大约花了 15 分钟。
Post Migration
您在上面读到的一切都是由_一个_人(我)在几周内完成的。 总的来说,我们从太平洋时间午夜到凌晨 1 点的停机时间不到一个小时——当然,没有任何数据丢失。 我们可以更积极地将停机时间限制在 15 分钟内,但我们选择超级安全并逐渐增加流量。
之后,我们看到聚合请求延迟立即下降了 33%。 但令人兴奋的部分才刚刚开始。 借助 Postgres 生态系统和 PGAnalyze 等工具,我们在迁移后的几个小时内修复了六个未优化的 Query。
尽管我们很保守并且_过度_配置了我们的 postgres 集群,但我们最终仍然为业务节省了每年略高于 110,000 美元的费用(如果考虑到系统流量的持续增长,还会更高)。
如果您喜欢解决这些类型的技术问题并产生令人难以置信的影响,您可能会喜欢在 Motion 工作! 我们正在招聘!