揭秘 Ruby (1/3): 线程的奥秘
揭秘 Ruby ♦️ (1/3): 线程的奥秘
Ruby 是一门真正的并行语言吗?!
发布于 2024年10月20日 | Wilfried
Ruby 是一种动态的、解释型、开源编程语言,以其简洁、高效和“人类可读”的语法而闻名。 Ruby 通常用于 Web 开发,特别是与 Ruby on Rails 框架一起使用。 它支持面向对象、函数式和指令式编程范式。
最著名和最常用的 Ruby 虚拟机是 Matz Ruby Interpreter (又名 CRuby),由 Yukihiro Matsumoto (又名 Matz),Ruby 的创建者开发。 所有其他的 Ruby 实现,例如 JRuby,TruffleRuby 等,都不在此博文的讨论范围内。
MRI 实现了 Global Interpreter Lock,这是一种机制,用于确保同一时间只有一个线程运行,从而有效地限制了真正的并行性。 从字里行间可以看出,Ruby 是多线程的,但并行性限制为 1 (或者可能更多 👀)。
许多流行的 Gems,例如 Puma,Sidekiq,Rails,Sentry 都是多线程的。
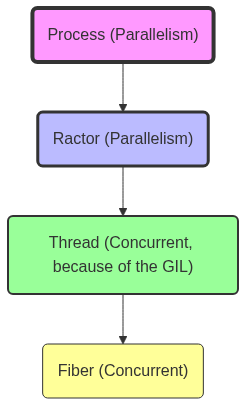
进程 💎, Ractor 🦖, 线程 🧵 和 Fiber 🌽
以下概述了 Ruby 中处理并发和并行性的所有复杂层(是的,它们不是同一件事)。 让我们深入探讨每一个。
你正身处一个模拟的模拟中……在一个更大的模拟里面!笑得更厉害了
默认情况下,所有这些嵌套结构都存在于你能想到的最简单的 Ruby 程序中。
你需要相信我,所以这是一个证明:
#!/usr/bin/env ruby
# Print the current Process ID
puts "Current Process ID: #{Process.pid}"
# Ractor
puts "Current Ractor: #{Ractor.current}"
# Print the current Thread
puts "Current Thread: #{Thread.current}"
# Print the current Fiber
puts "Current Fiber: #{Fiber.current}"
📋
Current Process ID: 6608
Current Ractor: #<Ractor:#1 running>
Current Thread: #<Thread:0x00000001010db270 run>
Current Fiber: #<Fiber:0x00000001012f3ee0 (resumed)>
每一段 Ruby 代码都运行在一个 Fiber 中,该 Fiber 运行在一个 Thread 中,该 Thread 运行在一个 Ractor 中,该 Ractor 运行在一个 Process 中。
进程 💎
这一个可能更容易理解。 你的计算机正在并行运行许多进程,例如:你的窗口管理器和你现在使用的 Web 浏览器是两个并行运行的进程。
因此,要并行运行 Ruby 进程,你可以打开两个终端窗口,并在每个窗口中运行一个程序,瞧!(或者你也可以在程序中运行 fork)。
在这种情况下,调度由操作系统协调,内存在进程 A 和进程 B 之间隔离(比如,你不想让 Word 访问你的浏览器内存吧?)。
如果你想将数据从进程 A 传递到进程 B,则需要进程间通信机制,例如管道、队列、套接字、信号或更琐碎的东西,例如共享文件,一个读取而另一个写入(注意竞态条件!)。
Ractor 🦖
Ractor 是一种新的实验性功能,旨在在 Ruby 程序中实现并行执行。 Ractor 由 VM 管理(而不是操作系统),在底层使用本机线程并行运行。 每个 Ractor 的行为都类似于同一 Ruby 进程中的独立虚拟机 (VM),具有自己的隔离内存。 “Ractor”代表“Ruby Actors”,与 Actor 模型一样,Ractor 通过传递消息来交换数据,而无需共享内存,从而避免了 Mutex 方法。 每个 Ractor 都有自己的 GIL,允许它们独立运行,而不会受到其他 Ractor 的干扰。
总而言之,Ractor 提供了一种真正的并行模型,其中内存隔离可以防止竞争条件,消息传递提供了一种结构化且安全的方式供 Ractor 交互,从而可以在 Ruby 中实现高效的并行执行。
让我们尝试一下
require 'time'
# `sleep` used here is not really CPU bound but it’s used to simplify the example
def cpu_bound_task()
sleep(2)
end
# Divide a large range into smaller chunks
ranges = [
(1..25_000),
(25_001..50_000),
(50_001..75_000),
(75_001..100_000)
]
# Start timing
start_time = Time.now
# Create Ractors to calculate the sum in parallel with delays
ractors = ranges.map do |range|
Ractor.new(range) do |r|
cpu_bound_task()
r.sum
end
end
# Collect results from all Ractors
sum = ractors.sum(&:take)
# End timing
end_time = Time.now
# Calculate and display total execution time
execution_time = end_time - start_time
puts "Total sum: #{sum}"
puts "Parallel Execution time: #{execution_time} seconds"
# Start timing
start_time = Time.now
sum = ranges.sum do |range|
cpu_bound_task()
range.sum
end
# End timing
end_time = Time.now
# Calculate and display total execution time
execution_time = end_time - start_time
puts "Total sum: #{sum}"
puts "Sequential Execution time: #{execution_time} seconds"
📋
warning: Ractor is experimental, and the behavior may change in future versions of Ruby! Also there are many implementation issues.
Total sum: 5000050000
Parallel Execution time: 2.005622 seconds
Total sum: 5000050000
Sequential Execution time: 8.016461 seconds
这就是 Ractor 并行运行的证明。
正如我之前所说,它们具有相当的实验性,并且未在您可能看到的许多 Gems 或代码中使用。
它们确实用于将密集的 CPU 绑定任务分配到您的所有 CPU 核心。
线程 🧵
操作系统线程和 Ruby 线程之间的关键区别在于它们如何处理并发和资源管理。 操作系统线程由操作系统管理,允许它们跨多个 CPU 核心并行运行,这使得它们资源密集型,但可以实现真正的并行性。 相比之下,Ruby 线程(尤其是在 MRI Ruby 中)由解释器管理并受 Global Interpreter Lock (GIL) 的限制,这意味着一次只能执行一个线程 Ruby 代码,从而将它们限制为并发而没有真正的并行性。 这使得 Ruby 线程很轻量级(也称为“绿色线程”),但无法充分利用多核系统(与允许在同一进程中运行多个“Ruby VM”的 Ractor 相反)。
让我们看一下这个使用线程的代码片段:
require 'time'
def slow(name, duration)
puts "#{name} start - #{Time.now.strftime('%H:%M:%S')}"
sleep(duration)
puts "#{name} end - #{Time.now.strftime('%H:%M:%S')}"
end
puts 'no threads'
start_time = Time.now
slow('1', 3)
slow('2', 3)
puts "total : #{Time.now - start_time}s\n\n"
puts 'threads'
start_time = Time.now
thread1 = Thread.new { slow('1', 3) }
thread2 = Thread.new { slow('2', 3) }
thread1.join
thread2.join
puts "total : #{Time.now - start_time}s\n\n"
📋
no threads
1 start - 08:23:20
1 end - 08:23:23
2 start - 08:23:23
2 end - 08:23:26
total : 6.006063s
threads
1 start - 08:23:26
2 start - 08:23:26
1 end - 08:23:29
2 end - 08:23:29
total : 3.006418s
Ruby 解释器控制何时切换线程,通常是在设置的指令数之后,或者当线程执行阻塞操作(如文件 I/O 或网络访问)时。 这使得 Ruby 对于 I/O 绑定任务非常有效,即使 CPU 绑定任务仍然受到 GIL 的限制。
您可以使用一些技巧,例如 priority 属性指示解释器您希望它优先运行优先级较高的线程,但不能保证 Ruby VM 会遵守它。 如果你想更直接一点,可以使用 Thread.pass。 一般来说,在代码中使用这些低级指令被认为是一个坏主意。
但是为什么首先需要 GIL 呢? 因为 MRI 的内部结构不是线程安全的! 这对于 MRI 非常特殊,其他 Ruby 实现(如 JRuby)没有这些限制。
最后,不要忘记线程共享内存,因此这为竞争条件打开了大门。 这是一个过于复杂的例子,供你理解。 它依赖于类级别变量共享相同内存空间的事实。 将类变量用于常量以外的其他用途被认为是一种不好的做法。
# frozen_string_literal: true
class Counter
# Shared class variable
@@count = 0
def self.increment
1000.times do
current_value = @@count
sleep(0.0001) # Small delay to allow context switches
@@count = current_value + 1 # Increment the count
end
end
def self.count
@@count
end
end
# Create an array to hold the threads
threads = []
# Create 10 threads that all increment the @@count variable
10.times do
threads << Thread.new do
Counter.increment
end
end
# Wait for all threads to finish
threads.each(&:join)
# Display the final value of @@count
puts "Final count: #{Counter.count}"
# Check if the final count matches the expected value
if Counter.count == 10_000
puts "Final count is correct: #{Counter.count}"
else
puts "Race condition detected: expected 10000, got #{Counter.count}"
end
📋
Final count: 1000
Race condition detected: expected 10000, got 1000
这里的 sleep 强制将上下文切换到另一个线程,因为它是一个 I/O 操作。 这会导致 @@count 值在上下文从一个线程更改为另一个线程时重置为先前的值。
在你的日常代码中,你不应该使用线程,但很高兴知道它们存在于我们每天使用的大多数 Gems 的底层!
Fiber 🌽
现在我们来介绍最后一个嵌套层! Fiber 是一种非常轻量级的协同并发机制。 与线程不同,fiber 不是抢先调度的; 而是显式地来回传递控制权。 Fiber.new 采用您将在 fiber 中执行的块。 从那里,您可以使用 Fiber.yield 和 Fiber.resume 来控制 fiber 之间的来回切换。 正如我们之前看到的,Fiber 在同一个 Ruby 线程中运行(因此它们共享相同的内存空间)。 与此博文中强调的每个其他概念一样,您应该将 Fiber 视为非常低级的接口,我建议避免构建大量基于它们的代码。 对我来说,唯一有效的用例是 Generator。 使用 Fiber 可以相对容易地创建一个惰性生成器,如下面的代码所示。
def fibernnacci
Fiber.new do
a, b = 0, 1
loop do
Fiber.yield a
a, b = b, a + b
end
end
end
fib = fibernnacci
5.times do
puts Time.now.to_s
puts fib.resume
end
📋
2024-10-19 15:58:54 +0200
0
2024-10-19 15:58:54 +0200
1
2024-10-19 15:58:54 +0200
1
2024-10-19 15:58:54 +0200
2
2024-10-19 15:58:54 +0200
3
正如您在此输出中看到的,代码仅在需要使用它们时才惰性地生成值。 这允许您在工具箱中可能需要的有趣模式和属性。
再一次,由于它是低级 API,因此在代码中使用 Fiber 可能不是最好的主意。 最著名的大量使用 Fiber 的 Gem 是 Async Gem(由 Falcon 使用)。
总结
Ruby 提供了几种并发模型,每种模型都具有适合不同任务的独特特征。
- 进程 提供完全的内存隔离,并且可以跨 CPU 核心并行运行,这使得它们非常适合需要完全分离但资源繁重的任务。
- Ractor(在 Ruby 3 中引入)还提供具有内存隔离的并行性,但在同一进程中,允许通过在 Ractor 之间传递消息来进行更安全的并行执行。
- 线程 比进程更轻量级,在同一进程中共享内存,并且可以并发运行,但它们需要仔细同步以避免竞争条件。
- Fiber 是最轻量级的并发机制,通过手动生成控制来提供协同多任务处理。 它们共享相同的内存,最适合用于构建生成器或协程,而不是并行执行。
有了这些知识,你现在就有论据来参加永无止境的 Puma(线程优先方法)与 Unicorn(进程优先方法)辩论。 请记住,讨论这个话题就像试图解释 Vi 和 Emacs 之间的区别! 找到哪个是赢家的练习留给读者!2
- 必须阅读关于
.map(&:something)语法 ↩︎ - 剧透:这取决于 ↩︎