Windsurf SWE-1:我们的首批前沿模型
SWE-1:我们的首批前沿模型
Written by By Windsurf Team Published on May 15, 2025 11 min read
今天,我们发布了我们的首个模型系列,名为 SWE-1,它针对整个软件工程流程进行了优化,而不仅仅是编码任务。Learn more
该系列目前包含三个不同的模型:
- SWE-1: 大约达到 Claude 3.5 Sonnet 级别的工具调用推理能力,但服务成本更低。在促销期内,所有付费用户都可以免费使用。
- SWE-1-lite: 一个较小的模型,以更好的质量取代 Cascade Base。所有用户(无论付费与否)都可以无限制地使用。
- SWE-1-mini: 一个小型、极快的模型,为所有用户(无论付费与否)提供 Windsurf Tab 的被动体验。
为什么要构建 SWE-1?简单来说,我们的目标是将软件开发速度提高 99%。编写代码只是您工作的一小部分。“具备编码能力”的模型是不够的。
The Quick Background
在过去的几年里,可以编写代码的模型已经变得越来越好。我们对这些模型的期望已经从提出简短的自动完成建议,发展到可靠地一次性构建简单的应用程序。
但是,这些模型在某些方面将会遇到瓶颈。
首先,任何软件开发人员都会告诉你,并非所有时间都花在编写代码上。我们执行更多类型的任务,并在更多界面上工作,因此我们需要对模型有更高的期望。模型不仅可以读取和编写代码,还可以在终端中工作、访问其他知识和互联网、测试和使用你的产品、理解用户反馈。软件开发人员所做的一切不仅仅是编写代码。
其次,任何软件开发人员都会告诉你,工作发生在所有这些界面上,并且会长期进行,沿着一系列不完整的状态前进。如今,最好的编码基础模型仍然主要接受战术工作的训练——最终代码是否可以编译并通过单元测试?但对你来说,单元测试只是一个更大的工程问题的一部分。有很多方法可以实现一个今天可以工作的功能——但用很少的好的方法可以实现一个你可以构建多年的功能。这就是为什么你会看到模型在 Cascade 中通过主动用户指导做得很好,但在独立运行的时间越长,效果就越差。要自动化更多的工作流程,就需要消除这种限制。这需要对工程流程的完整复杂性进行建模:对不完整状态进行推理,结果可能不明确。
在某些时候,仅仅擅长编码并不能让你或模型更擅长软件工程。我们最终希望帮助加速软件工程师可以做的所有事情,因此我们早就知道我们需要“软件工程”模型。简称 SWE 模型。
SWE-1
在大量使用的 Windsurf Editor 的启发下,我们开始构建一个全新的数据模型(共享时间线)和一个训练方法,其中包含不完整状态、长时间运行的任务和多个界面。
我们的最初目标是证明我们可以通过这种方法达到前沿水平的性能,即使拥有一支较小的工程师团队和比研究实验室更少的计算资源。SWE-1 是最初的概念验证。
总的来说,SWE-1 接近所有前沿基础模型。重要的是,它优于所有非前沿模型和开源替代方案。为了进行基准测试,我们进行了离线评估和盲生产实验。
Offline Evaluation
我们将 SWE-1 的性能与 Anthropic 系列模型(Cascade 中使用最广泛的模型之一)以及 Deepseek 和 Qwen 中的领先编码开源模型进行了比较。
Conversational SWE Task Benchmark : 从现有 Cascade 会话的中间开始,任务只完成了一半,Cascade 在多大程度上解决了下一个用户查询?0-10 的分数是针对帮助性、效率和正确性的判断分数的混合平均值,以及目标文件编辑的准确性指标。
我们认为这个基准测试捕捉到了我们通过 Cascade 开创的人与机器协作编码的独特本质。只要模型不完善,我们认为能够与用户输入无缝地交织在一起完成部分完成的任务是衡量模型有用性的一个非常重要的指标。

End-To-End SWE Task Benchmark : 从对话的开始开始,Cascade 在多大程度上通过通过一组选定的单元测试来解决输入意图?0-10 的分数是测试通过率和判断分数的混合平均值。
这个基准测试旨在捕捉模型独立运行以端到端解决问题的能力。随着所有模型越来越能够无需人工干预即可运行,这是一个越来越重要的用例。
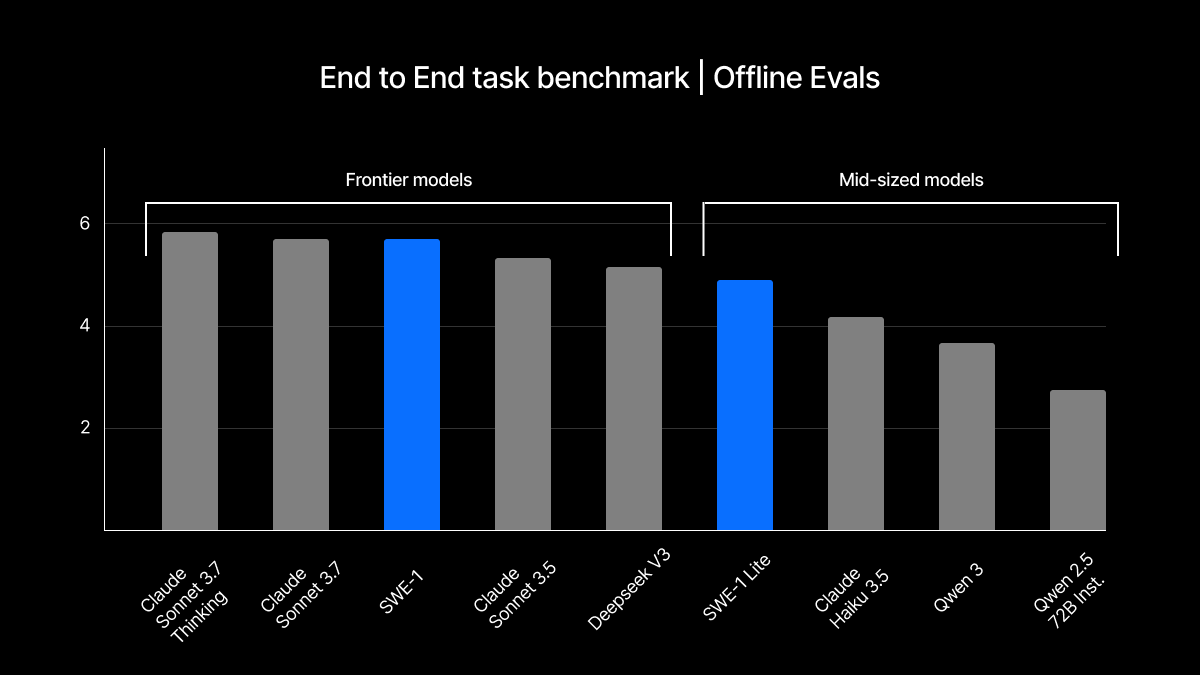
从离线评估来看,我们认为 SWE-1 在这些任务中与基础模型实验室的前沿模型处于同一水平,并且优于领先的开源替代方案中的中型模型和前沿模型。它不是绝对的前沿,但有希望与领先的模型竞争。
Production Experiments
因为我们拥有庞大的用户社区,所以我们也依靠生产实验来补充离线评估。为了计算这些每日指标,我们对一部分用户进行了盲实验,他们不知道他们正在访问哪个模型。每个用户的模型保持不变,以便我们可以衡量一段时间内的重复使用情况。
我们将 Claude 模型作为基准,因为它们历来是并且仍然是 Cascade 中最常用的模型。
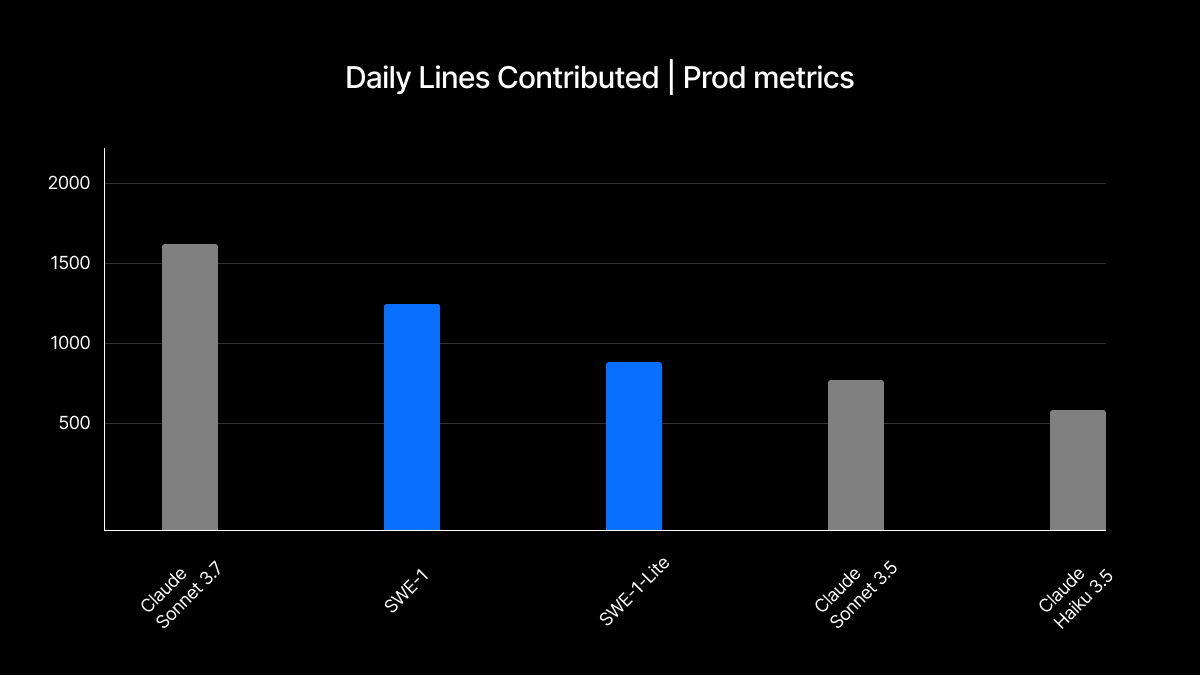
Daily Lines Contributed per User : Cascade 编写的并被用户主动接受和保留的平均代码行数(在固定的时间内)。这是衡量整体帮助性的指标,反映了模型每次被调用时的贡献有多大帮助,以及用户随着时间的推移继续重复使用该模型的意愿。
我们认为这是一个非常有指示性的指标,它反映了主动性和建议质量的平衡,但也反映了输出速度和对反馈的响应能力,这些因素导致用户成为“回头客”。
Cascade Contribution Rate : 对于 Cascade 至少编辑过一次的文件,这是由 Cascade 对这些文件所做的更改百分比。这是衡量帮助性的指标,针对用户希望使用该模型的频率以及模型贡献代码的意愿进行了归一化。因为它只衡量模型编辑的文件,所以它试图控制使用频率和模型编辑倾向。
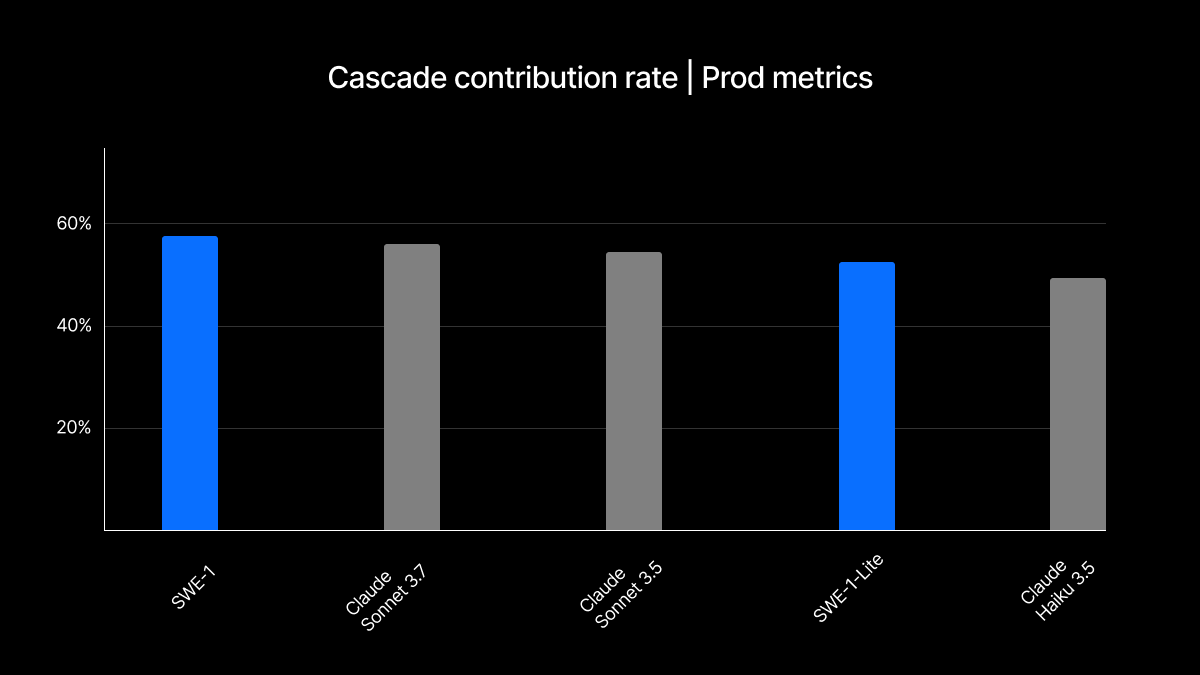
SWE-1 是根据我们的用户与 Cascade 的交互类型构建和过度拟合的,因此我们对其在这些生产实验中似乎接近行业领先水平并不感到非常惊讶。
Other Models and Analysis
在上面的图表中,您会注意到 SWE-1-lite,它是使用相同训练方法构建的 SWE-1 模型的中型版本。它领先于所有其他非前沿的中型模型,并将取代我们的 Cascade Base 模型,成为我们所有用户的无限使用选项。
我们还构建了第三个模型 SWE-1-mini,它共享许多相同的流程感知训练方法,但足够小,可以在被动预测系统的延迟约束内运行,并且针对预测动作任务进行了进一步训练(而不是工具调用)。
需要明确的是,这仅仅是个开始。最终,在软件工程领域,我们的目标不是匹配任何研究实验室的前沿模型性能,而是超越所有这些模型。我们比以往任何时候都更加相信我们拥有这样做的引擎,并且我们将继续大力投资于这一战略。
Our Flow-Aware System
我们在上一节以“受到大量使用的 Windsurf Editor 的启发”开头。我们应该解释一下 Windsurf Editor 如何启用 SWE-1,以及为什么我们如此确信我们的模型最终将成为最好的模型。
这归结为我们如何逐步迭代:流程感知。
什么是流程感知?我们构建 Windsurf Editor 是为了在用户和 AI 的综合状态之间建立无缝的交织。AI 做的任何事情,人都应该能够观察和采取行动,人做的任何事情,AI 都应该能够观察和采取行动。我们将这种对共享时间线的感知称为“流程感知”,因此我们一直将我们的协作代理体验称为“AI 流程”。
为什么支持流程感知的编辑器至关重要?简单来说,在任何 SWE 模型真正能够独立完成所有事情之前,还需要一段时间。流程感知使在此中间阶段采用正确的交互形式成为可能——采用这种模型可以做的任何事情,并在它出错的地方,让人类介入进行纠正,然后模型继续构建在人类所做的事情之上。无缝、自然的切换。
这意味着在任何给定的时间,我们在 Windsurf 始终通过查看模型在此共享时间线中在用户干预和不干预的情况下完成的步骤来了解当前模型能力的真正限制。我们始终大规模地知道我们的用户希望我们接下来改进我们的模型什么。这就是我们能够快速将我们的模型构建到今天 SWE-1 状态所达到的水平的原因,这也是我们相信我们最终将构建绝对最好的 SWE 模型的原因。
事实上,无论您是否注意到,构建共享时间线一直是 Cascade 许多主要功能的指导愿景:
- 在 Cascade 发布时,我们强调的一件事是,您可以在文本编辑器中进行一些编辑,然后在 Cascade 中键入“继续”,Cascade 将自动合并您刚刚所做的编辑。这就是对文本编辑器的感知。
- 不久之后,我们将终端输出纳入流程感知,以便 Cascade 无缝地了解您在运行代码时遇到的错误。这就是对终端的感知。
- 在 Wave 4 中,我们添加了“预览”的概念,以便 Cascade 可以了解用户正在交互和感兴趣的哪种前端组件或错误。这是对浏览器的基本感知。
但是,Windsurf 中的一切都建立在流程感知这个概念之上,而不仅仅是 Cascade。Tab 也建立在相同的共享时间线概念之上。当我们向 Cascade 添加上下文时,我们也会将其添加到 Tab 中。这不仅仅是随意地将更多信息扔到固定的上下文窗口中。这是对最能反映用户操作和目标的共享时间线的非常仔细的构建。这就是为什么我们的 Tab 版本具有:
- 对你的终端命令的感知 (Wave 5)
- 对你在剪贴板中复制的内容的感知 (Wave 5)
- 对当前 Cascade 对话的感知 (Wave 5)
- 对 IDE 内用户搜索的感知 (Wave 6)
我们不会发布随机功能。我们一直在努力构建现有的最丰富的软件工程工作共享时间线表示。即使在使用现成的模型时,我们的工具也因共享时间线中信息的存在而得到了显着改进。但是现在有了我们自己的 SWE 模型,我们可以真正启动这个飞轮,让模型可以摄取时间线并开始对时间线的更多内容采取行动。
What’s Next
正如前面提到的,SWE-1 是由一个规模虽小但极其专注的团队实现的,他们利用了我们作为产品和基础设施公司的优势。它代表了我们首次尝试构建真正具有前沿质量的模型,虽然我们对结果感到自豪,但我们知道这仅仅是个开始。我们强调了我们独特的应用程序、系统和模型飞轮的力量,如果没有我们所运营的那种应用程序界面和大规模的活动衍生洞察力,即使是基础实验室本身也无法拥有这些。
您将继续听到有关 SWE 模型系列改进的消息。我们将继续加大投入,为我们的用户带来最佳性能,同时以最低的成本,以便您可以继续使用 Windsurf 构建更大更好的东西。
如果您想解决这个问题,我们正在迅速扩大我们的 ML 研究和工程团队。点击这里申请。