让 AI 编写高质量 SQL:Text-to-SQL 技术详解
[中文正文内容]
Organizations 依赖于快速且准确的、数据驱动的洞察力来进行决策,而 SQL 是他们访问这些数据的核心方式。借助 Gemini,Google 可以直接从自然语言生成 SQL,也就是 Text-to-SQL。 这种能力提高了开发人员和分析师的生产力,并使非技术用户能够直接与他们所需的数据进行交互。
目前,您可以在许多 Google Cloud 产品中找到 Text-to-SQL 功能:
- BigQuery Studio 中的 SQL Editor 和 SQL Generation tool,以及 Data Canvas SQL 节点。
- Cloud SQL Studio 中的 "Help me code" 功能 (Postgres, MySQL 和 SQLServer), AlloyDB Studio 和 Cloud Spanner Studio。
- AlloyDB AI 及其直接连接数据库的自然语言界面,目前以公开预览版提供。
- 通过 Vertex AI,您可以直接访问 Gemini 模型,这些模型是这些产品的基础。
最近,像 Gemini 这样强大的大型语言模型 (LLMs) 凭借其推理和综合能力,推动了 Text-to-SQL 领域的显著进步。 在这篇博客文章(该系列的第一篇)中,我们将探讨 Google Cloud 的 Text-to-SQL 代理的技术内部原理。我们将介绍用于上下文构建和表检索的先进方法,如何使用 LLM-as-a-judge 技术对 Text-to-SQL 质量进行有效评估,LLM prompt 和后处理的最佳方法,以及我们如何使用能够让系统提供实际上经过验证的正确答案的技术。
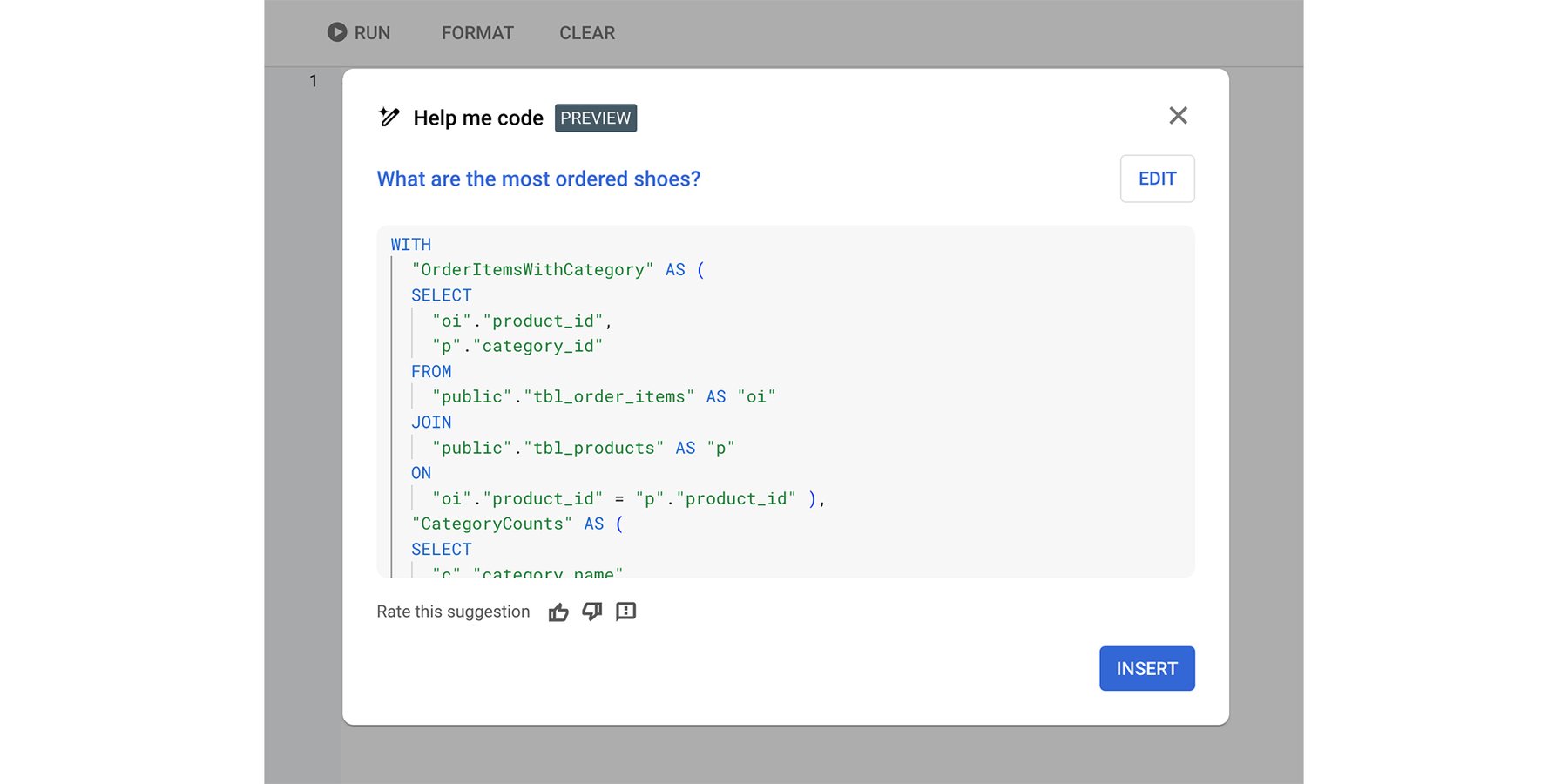
Cloud SQL Studio 中的“Help me code”功能从文本提示生成 SQL
Text-to-SQL 技术的挑战
当前最先进的 LLMs(如 Gemini 2.5)具有推理能力,使其擅长将自然语言提出的复杂问题转换为可运行的 SQL,包括连接、筛选、聚合和其他困难概念。
为了了解这一点,您可以在 Vertex AI Studio 中进行一个简单的测试。 假设提示“我有一个包含产品和订单的数据库模式。 编写一个 SQL 查询,显示鞋子的订单数量”,Gemini 会为假设的模式生成 SQL:
SELECT COUNT(DISTINCT o.order_id) AS NumberOfShoeOrders FROM orders o JOIN order_items oi ON o.order_id = oi.order_id JOIN products p ON oi.product_id = p.product_id WHERE p.product_name LIKE '%shoe%'.
太棒了,这是一个看起来不错的查询。 但是,如果您超越这个简单的例子,并在真实世界的数据库和真实世界用户问题上使用 Gemini 进行 Text-to-SQL 会发生什么? 事实证明,这个问题更加困难。 该模型需要通过以下方法进行补充:
- 提供业务特定的上下文
- 理解用户意图
- 管理 SQL 语法的差异
让我们来看看这些挑战中的每一个。
问题 1:提供业务特定的上下文
就像数据分析师或工程师一样,LLMs 需要大量的知识或“上下文”才能生成准确的 SQL。 上下文可以是显式的(模式是什么样的,相关的列是什么,数据本身是什么样的?),也可以是更隐式的(一条数据的精确语义含义是什么?对于特定的业务案例意味着什么?)。
专门的模型训练或微调通常不是解决此问题的可扩展解决方案。 针对每个数据库或数据集的形状进行训练,并跟上模式或数据更改,既困难又成本高昂。 业务知识和语义通常在一开始就没有得到很好的记录,并且很难转化为训练数据。
例如,即使是世界上最好的 DBA,如果他们不知道 pcat_extension 表中的 cat_id2 = 'Footwear' 意味着相关产品是一种鞋子,也无法编写准确的查询来跟踪鞋子的销售情况。 LLMs 也是如此。
问题 2:理解用户意图
自然语言不如 SQL 精确。 面对模糊问题的工程师或分析师可以检测到他们需要更多信息,然后回去提出正确的后续问题。 另一方面,LLM 倾向于尝试给您一个答案,当问题不明确时,可能会产生幻觉。
示例:以“什么是最畅销的鞋子?”这样的问题为例。 在这里,一个明显的模糊点是“最畅销”在业务或应用程序的上下文中实际上意味着什么——订购最多的鞋子? 带来最多收入的鞋品牌? 此外,SQL 是否应该计算退回的订单? 以及您希望在报告中看到多少种鞋子? 等等。
此外,不同的用户需要不同类型的答案。 如果用户是技术分析师或开发人员,提出一个模糊的问题,给他们一个合理但可能不是 100% 正确的 SQL 查询是一个好的开始。 另一方面,如果用户技术水平较低且不了解 SQL,则提供精确、正确的 SQL 更为重要。 能够回复后续问题以消除歧义,解释答案背后的推理过程,并引导用户找到他们正在寻找的内容至关重要。
问题 3:LLM 生成的限制
开箱即用,LLMs 特别擅长创意写作、总结或从文档中提取信息等任务。 但是,某些模型可能难以遵循精确的指示并完全正确地获取细节,尤其是在涉及更晦涩的 SQL 功能时。 为了能够生成正确的 SQL,LLM 需要严格遵守通常会变成复杂规范的内容。
示例:考虑 SQL 方言之间的差异,这些差异比 Python 和 Java 等编程语言之间的差异更微妙。 作为一个简单的例子,如果您使用的是 BigQuery SQL,则从时间戳列中提取月份的正确函数是 EXTRACT(MONTH FROM timestamp_column)。 但是,如果您使用的是 MySQL,则使用 MONTH(timestamp_column)。
Text-to-SQL 技术
在 Google Cloud,我们不断改进我们的 Text-to-SQL 代理以提高其质量。 为了解决上面列出的问题,我们应用了许多技术。
| 问题 | 解决方案 | | :--------------------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | 理解模式、数据和业务概念 | * 基于语义相似性的数据集、表和列的智能检索和排序。 * 具有业务特定示例的上下文学习 * 数据链接和抽样 * 原始数据上的语义层。 这在复杂的数据结构和客户使用的日常语言之间架起了一座桥梁 * 使用模式分析和查询历史 | | 理解用户意图 | 使用 LLMs 消除歧义 * 实体解析 | | SQL-aware 基础模型 | | | LLM 生成的限制 | 自洽性 验证和重写 * 强大的基础模型 * 具有方言特定示例的上下文学习 * 模型微调 |
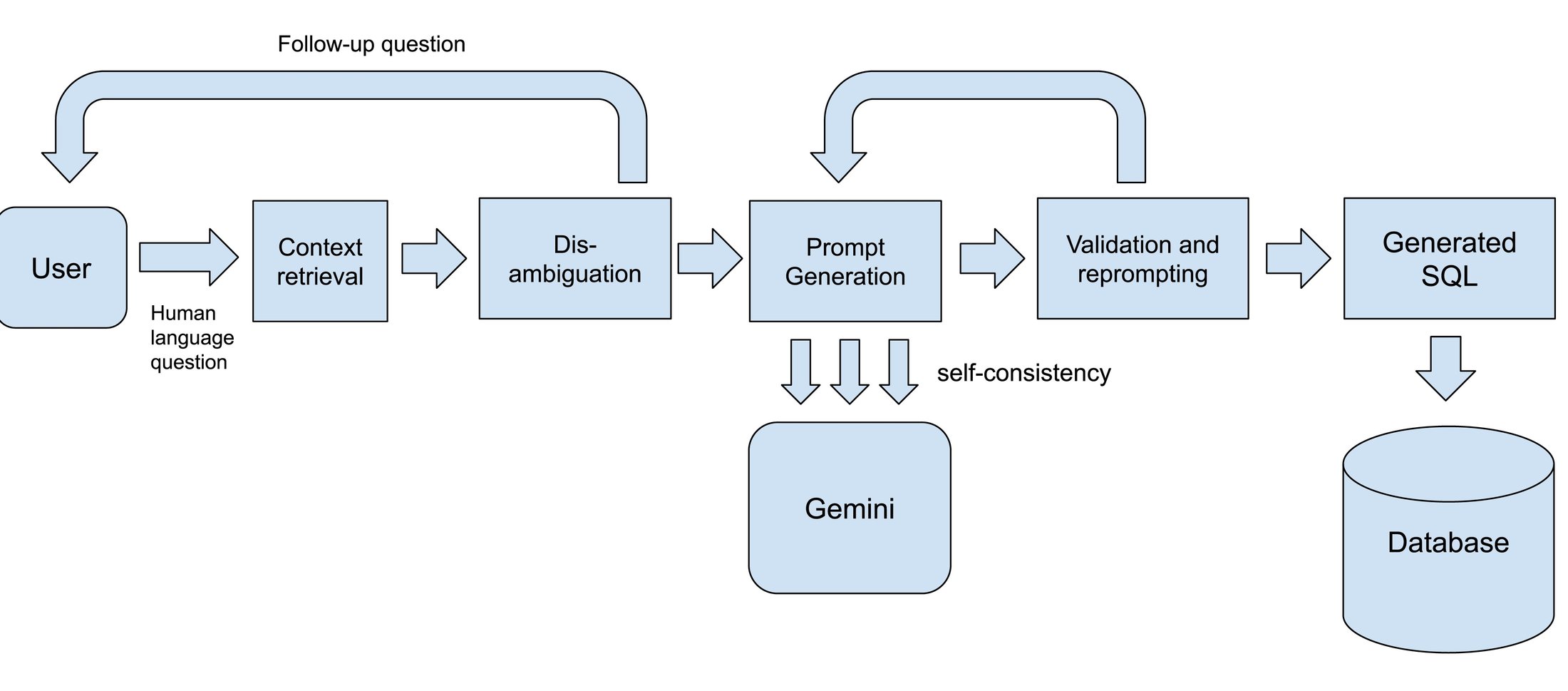
Text-to-SQL 架构
让我们仔细看看其中一些技术。
SQL-aware 模型 强大的 LLMs 是 Text-to-SQL 解决方案的基础,Gemini 系列模型在高质量代码和 SQL 生成方面拥有良好的记录。 根据特定的 SQL 生成任务,我们混合和匹配模型版本,包括在某些情况下我们采用定制的微调,例如确保模型为某些方言提供足够好的 SQL。
使用 LLMs 消除歧义 消除歧义涉及让系统在遇到不够清楚的问题时回复一个澄清问题(在上面的“什么是最畅销的鞋子?”的例子中,应该导致文本 -SQL 代理提出类似“您想查看按订单数量或收入排序的鞋子吗?”的后续问题)。 在这里,我们通常编排 LLM 调用,首先尝试确定是否可以根据可用的模式和数据实际回答问题,如果不能,则生成必要的后续问题以澄清用户的意图。
检索和上下文学习 如上所述,为模型提供生成 SQL 所需的上下文至关重要。 我们使用各种索引和检索技术——首先识别相关的数据集、表和列,通常使用向量搜索进行多阶段语义匹配,然后加载其他有用的上下文。 根据产品,这可能包括用户提供的模式注释、类似 SQL 的示例或如何应用特定的业务规则,或者用户对同一数据集运行的最近查询的样本。 所有这些数据都被组织成提示,然后传递给模型。 Gemini 对长上下文窗口的支持通过允许模型处理大型模式和其他上下文信息来解锁新的功能。
验证和重新提示 即使使用高质量的模型,LLM 驱动的 SQL 生成仍然涉及一定程度的非确定性或不可预测性。 为了解决这个问题,我们发现像查询解析或对生成的 SQL 进行试运行这样的非 AI 方法可以很好地补充基于模型的工作流程。 如果 LLM 遗漏了一些关键内容,我们可以获得一个清晰、确定的信号,然后将其传递回模型进行第二次处理。 当提供一个错误示例和一些指导时,模型通常可以解决他们出错的地方。
自洽性 自洽性的想法是不依赖于单轮生成,而是为同一个用户问题生成多个查询,可能使用不同的 prompting 技术或模型变体,并从所有候选查询中选择最佳的。 如果多个模型一致认为一个答案看起来特别好,则最终 SQL 查询准确且与用户正在寻找的内容相匹配的可能性更大。
评估和衡量改进
改进 AI 驱动的功能取决于强大的评估。 学术界开发的 Text-to-SQL 基准,例如流行的 BIRD-bench,一直是了解模型和端到端系统性能的非常有用的基线。 但是,当涉及到表示广泛的真实世界模式和工作负载时,这些基准通常是缺乏的。 为了解决这个问题,我们开发了自己的综合基准套件,以多种方式增强基线。
覆盖范围: 我们确保拥有涵盖广泛的 SQL 引擎和产品(包括方言和引擎特定功能)的基准。 这不仅包括查询,还包括 DDL、DML 和其他管理需求,以及代表常见使用模式的问题,包括更复杂的查询和模式。
指标: 我们结合了用户指标和离线评估指标,并采用人工和自动化评估,特别是使用 LLM-as-a-judge 技术,这降低了成本,但仍然允许我们了解模糊和不明确任务的性能。
持续评估: 我们的工程和研究团队使用评估来快速测试新的模型、新的 prompting 技术和其他改进。 它可以快速给我们信号,告诉我们一种方法是否显示出前景并且值得追求。
总而言之,使用这些技术正在推动我们在实验室以及客户环境中看到的 Text-to-SQL 的显着改进。 当您准备好将 Text-to-SQL 纳入您自己的环境时,请继续关注对我们 Text-to-SQL 解决方案的更深入探讨。 立即在 BigQuery Studio、CloudSQL, AlloyDB 和 Spanner Studio 以及 AlloyDB AI 中试用 Gemini Text-to-SQL。