Transformer 神经网络通过示例学习运行 Conway's Game of Life
Transformer 神经网络通过示例学习运行 Conway's Game of Life
发布时间:2024年7月7日 最后编辑时间:2025年5月17日
我们发现,一个高度简化的 Transformer 神经网络仅通过学习游戏的示例,就能够完美地计算 Conway’s Game of Life。
这个模型的简单性使我们能够观察它的结构,并确认它确实在计算 Game of Life —— 而不是一个基于已训练的所有示例来预测最可能的下一个状态的统计模型。
我们观察到,它学会使用其 attention 机制来计算 3x3 卷积 —— 3x3 卷积是实现 Game of Life 的一种 常见 方法,因为它可用于计算单元格的邻居数量,而邻居数量用于决定单元格是存活还是死亡。
我们将该模型称为 SingleAttentionNet,因为它由一个带有 single-head attention 的 attention block 组成。 该模型将 Life 网格表示为一组 tokens,每个网格单元格一个 token。
下图显示了由 SingleAttentionNet 模型计算的 Life 游戏:
 下图显示了 SingleAttentionNet 模型的 attention 矩阵在训练过程中的示例:
下图显示了 SingleAttentionNet 模型的 attention 矩阵在训练过程中的示例:
 这表明该模型正在学习通过其 attention 机制计算 3x3 平均池化(排除中心单元格)。
这表明该模型正在学习通过其 attention 机制计算 3x3 平均池化(排除中心单元格)。
细节
完整的代码可在此处获得:here。
问题建模如下:
model(life_grid) = next_life_grid
其中使用梯度下降来最小化损失:
loss = cross_entropy(true_next_life_grid, predicted_next_life_grid)
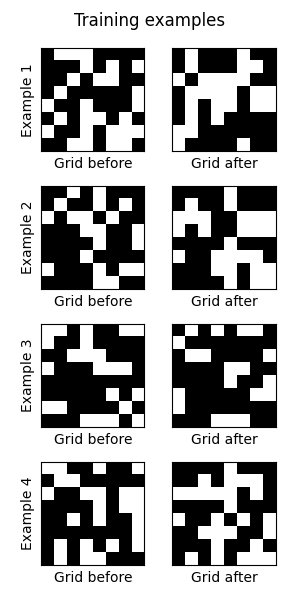
随机生成 Life 网格,以提供无限的训练对来源 (life_grid, next_life_grid)。 一些例子:
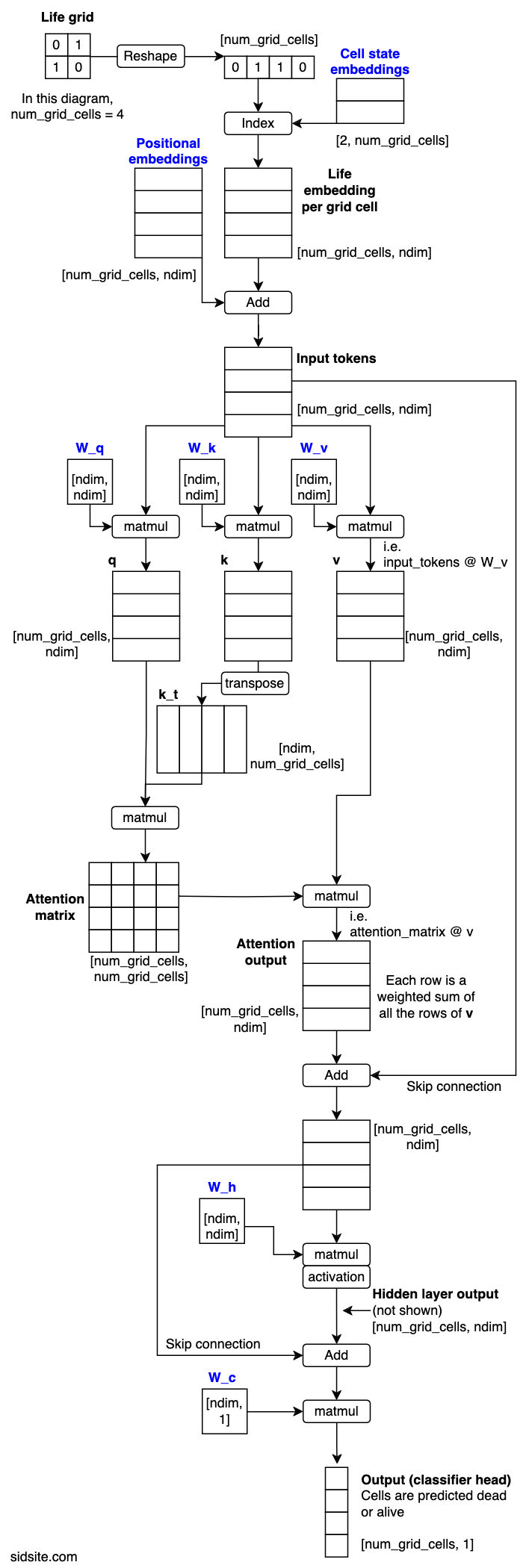
模型图
该图中的模型处理 2x2 Life 网格,这意味着每个网格总共有 4 个 tokens。蓝色文字表示通过梯度下降学习的参数。数组标有它们的形状(省略了 batch 维度)。
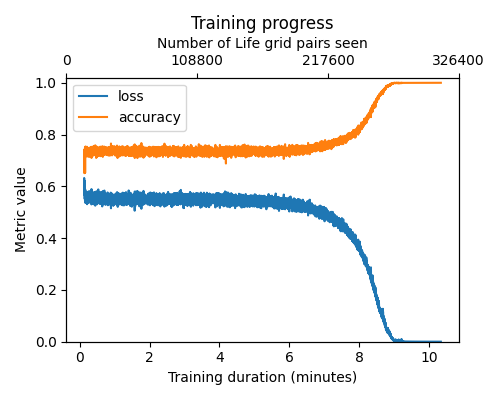
训练
在 GPU 上,训练模型需要几分钟到 10 分钟不等,或者可能会因为 seed 和其他训练超参数的原因而无法收敛。我们成功训练的最大网格大小为 16x16。
备注
我们尝试用手动计算的 Neighbour Attention 矩阵替换模型的 attention 层,发现该模型更快地学习了它的任务,并且推广到任意网格大小。我们发现用 3x3 平均池化层替换该层也是如此。
我们通过寻找具有完美预测的 1024 个训练批次,以及它可以完美运行 100 个 Life 游戏 100 步来检测模型是否已收敛。
我们发现仅在随机 Life 游戏的第一次和第二次迭代上训练模型就足够了,但仅在第一次迭代上训练是不够的。
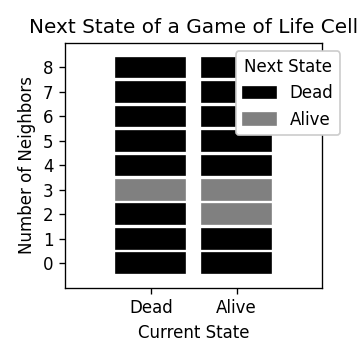
Life 的规则
Life 发生在 2D 网格上,网格中的单元格要么是死的,要么是活的(用 0 或 1 表示)。 一个单元格有 8 个邻居,它们是网格上紧挨着它的单元格。
要进入下一个 Life 步骤,请使用以下规则:
- 如果一个单元格有 3 个邻居,那么它将在下一步中存活,而不管它当前的状态(存活或死亡)。
- 如果一个单元格是活的并且有 2 个邻居,那么它将在下一步中保持存活。
- 否则,一个单元格将在下一步中死亡。
这些规则如下图所示。
参考:
- Springer et al - 2020 - It’s Hard For Neural Networks to Learn the Game of Life - https://arxiv.org/abs/2009.01398
- McGuigan - 2021 - Its Easy for Neural Networks To Learn Game of Life - https://www.kaggle.com/code/jamesmcguigan/its-easy-for-neural-networks-to-learn-game-of-life
- Vaswani et al - 2017 - Attention Is All You Need - https://arxiv.org/abs/1706.03762
- Conway’s Game of Life - https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life
引用:
@misc{radcliffe_life_transformer_2024,
title={Training a Simple Transformer Neural Net on Conway's Game of Life},
url={https://sidsite.com/posts/life-transformer/},
howpublished={Main page: \url{https://sidsite.com/posts/life-transformer/}, GitHub repository: \url{https://github.com/sradc/life-transformer}},
author={Radclffe, Sidney},
year={2024},
month={July}
}