MinorMiner:我们将你孩子的数学作业变成 Bitcoin
Robert Heaton
Software Engineer / One-track lover / Down a two-way lane
MinorMiner:我们将你孩子的数学作业变成 Bitcoin
14 May 2025
您好!您好!欢迎,欢迎。我叫 Hobert Reaton,我来到这家简陋的汽车旅馆会议室,向您展示又一个千载难逢的投资机会。
看看这张照片。告诉我你看到了什么:

你看到的是学习?自我提升?我们国家的未来领导者?
我告诉你我看到了什么:浪费的计算能力。
在 5 岁到 18 岁之间,接受全日制教育的普通孩子每周完成大约 5 张数学练习题。每张练习题有 20 个问题。这意味着在他们的整个学习生涯中,我们每个孩子都要进行大约 80,000 次计算。
目前,我们完全浪费了他们的工作。一个学生算出了 5+5=10 和 7x7=49。这激励了他们;他们因成功而充满活力。但是,我们如何处理他们的劳动成果呢?什么也不做!我们把果实扔掉,让它在虚空中腐烂。“我们已经知道了,”我们告诉我们的孩子。“你的想法并不重要。” 与社会其他部分不同,我相信孩子们应该感到被欣赏。 我相信他们的成就是有价值的。
这就是我创立 MinorMiner 的原因。
什么是 MinorMiner?
MinorMiner 是一个平台,允许学龄儿童通过使用数学作业来挖掘 Bitcoin,从而将其货币化。是的,你没听错。我们给孩子们布置作业,他们努力完成,然后我们一起将他们的汗水转化为数字黄金。 这不是一些小打小闹的激励计划,我们用它来贿赂孩子们关心乘法。 作业是为我们的机器提供动力的基本原材料。 我们需要这些孩子。 没有孩子;就没有 Bitcoin。
为了理解使 MinorMiner 成为可能的创新,我们首先需要理解今天是如何挖掘 Bitcoin 的。 现在,人们通过使用计算机解决复杂的数学难题来挖掘 Bitcoin。 这些难题看起来像这样:
- 获取自上次 Bitcoin 被挖掘以来发生的所有 Bitcoin 交易的列表。检查它们是否都被正确授权,并且没有一个花费了创建者没有的钱。
- 选择一串额外的字母和数字添加到此列表的末尾(一个 nonce)。 这是你尝试解决难题的方法。
- 将列表和你的额外字符通过一个极其复杂的函数,称为 SHA-256 hash function(技术上你将它通过该函数两次)。hash function 切割、切片、旋转和骰切输入,表面上(但实际上并非如此)是随机的。最后,它吐出一个数字。
- 你试图解决的难题是:步骤 2 中的字母和数字的哪种组合导致步骤 3 的输出小于某个小的目标数字?
步骤 1 收集自上一个区块以来的有效 Bitcoin 交易 步骤 2 添加 nonce 步骤 3 通过 hash function 传递交易和 nonce 步骤 4 检查 hash 输出是否小于目标 NO - 使用新的 nonce 重试 发布解决方案并声明奖励 YES - 挖掘新的 bitcoin 区块!
没有优雅的方法来解决这些难题。 Bitcoin 矿工唯一能做的就是反复猜测步骤 2 的输入,直到他们找到一个恰好满足步骤 4 中的标准。 当矿工猜对了答案时,我们说他们“挖掘”了一个新的“区块”。 他们将他们的解决方案附加到区块链上,以表明他们已经验证了区块中的交易,并且他们获得了新的 bitcoin 的奖励。 他们的工作,以及我稍微忽略的几个额外步骤,确保了区块链的安全。
然而,它也需要令人难以置信的电力 - 每年约 150TWh,或占世界总能源消耗的 1%。 如果有一种更好、更有效的方式来实现同样的目标呢?
这就是 MinorMiner 和学龄儿童发挥作用的地方。“但是挖掘 Bitcoin 听起来很难!”我听到你哀嚎。“我的孩子只对基本算法有初步的掌握!” 没错,没错 - 但神奇之处在于我们平台上的孩子们不需要知道如何挖掘 Bitcoin,他们甚至不会知道他们正在这样做。 我们的团队已将 bitcoin 区块链使用的 SHA-256 hashing algorithm 转换成一系列即使是最迟钝的人也能回答的基本算术问题。 解决一个区块链难题曾经需要理解和执行 SHA-256 hash。 现在,所需要的只是跳过几个万亿个简单的脑筋急转弯。
5+3=?10*5=?102 比 67 大吗? (y/n)- 等等
孩子们做这些总和 - 我们负责其余的工作。
MinorMiner 平台如何运作?
MinorMiner 的核心是一个集中式系统,用于管理我们的挖掘。 该系统将 SHA-256 hash 计算分解为简单的算术问题,并确定接下来需要回答哪些问题。 足够简单 - 但是我们如何将问题传递给孩子们? 三个字:在线数学测验。
你看,MinorMiner 还有一个数学学习平台,我们将其出售给世界各地的学校。 我们的平台不是特别好,但我们给部门负责人慷慨的收入分成,因此这往往无关紧要。 一旦老师(或者我们喜欢称之为“分销伙伴”)在 MinorMiner 上设置好,他们就会给他们的班级布置测验作为作业。 晚上,他们的孩子(或者“计算伙伴”)登录 MinorMiner 门户并回答他们当天的测验,其中包括我们的 hashing system 需要做的任何问题。 作为补偿,他们的分销伙伴不会给他们留校。 我们收集他们的答案并用它们来继续计算 hash。 当一个伙伴完成他们的测验时,下一个伙伴从他们离开的地方继续计算。
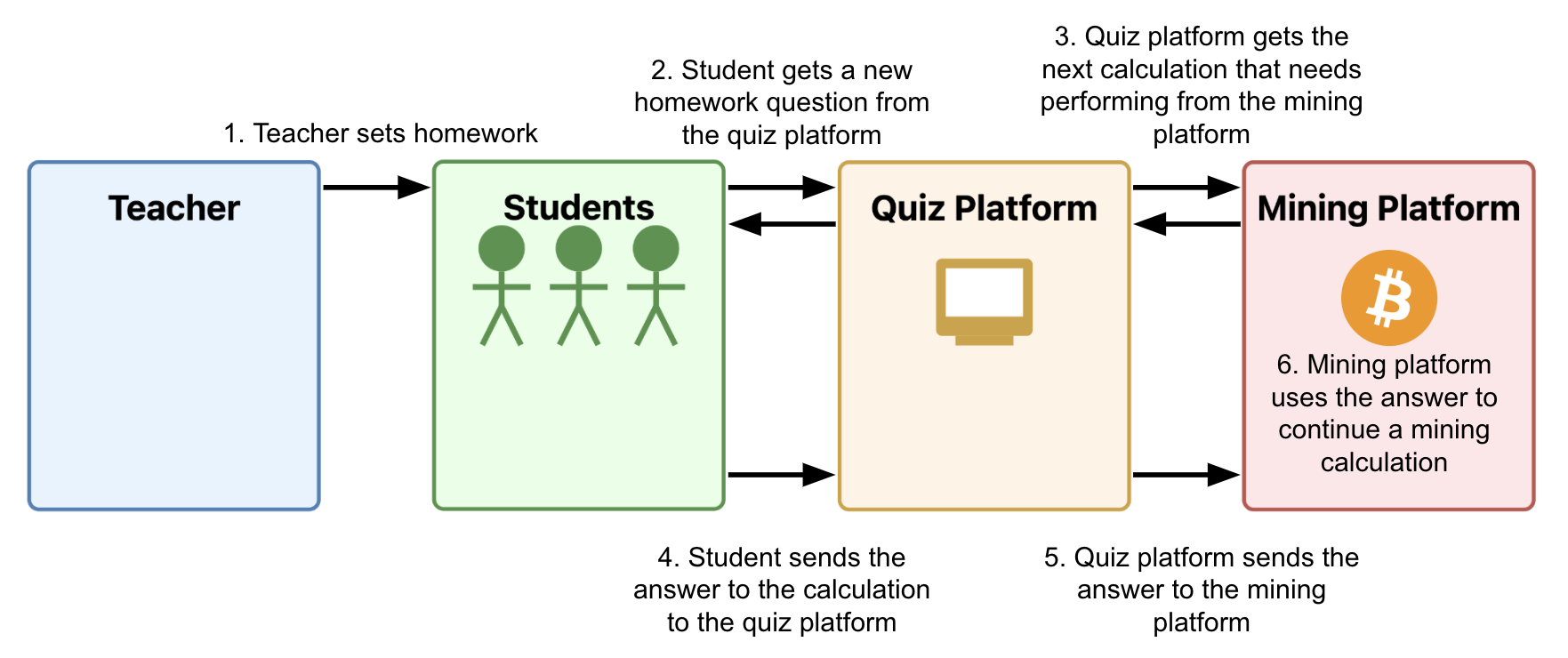
我们必须小心 - hash 是一件微妙的事情。 在一个小步骤中犯一个小错误 - 噗! - 整个计算都完全、不可逆转地搞砸了。 这就是为什么我们将每个计算发送给两个单独的计算伙伴的原因。 如果他们的答案不一致,那么我们会升级到一个稍微年长的伙伴来进行裁决。 我们根据每个伙伴的准确性来维护他们的评分。 如果他们的评分降至 4.3 星以下,那么他们将被邀请参加额外的培训,以帮助他们恢复到 MinorMiner 伙伴所期望的标准。 如果没有取得这样的进步,那么他们将被邀请到其他地方寻求数学教育。
到目前为止有什么问题吗? 没有? 那么现在是我向您展示我们真正的技术突破的时候了。
CUDAAAAGH
我们使用一个名为 Centralized Underage Distributed Arithmetic - Automated Assignment And Group Hashing (CUDAAAAGH) 的 Python 库来编写我们的挖掘代码。 CUDAAAAGH 允许我们将任何复杂的计算分配到无限可扩展的计算伙伴池中。 我们已经在 GitHub 和 PyPi 上开源了它。
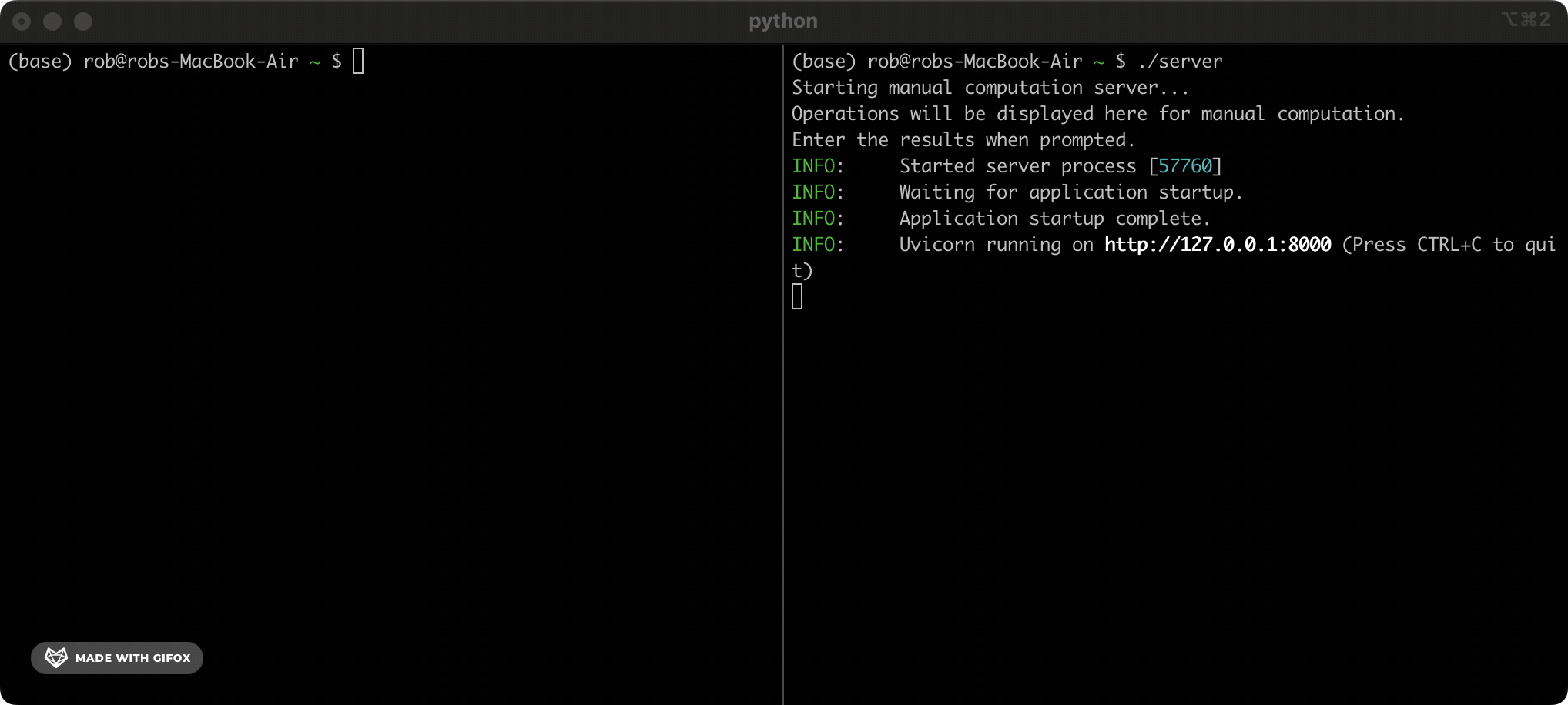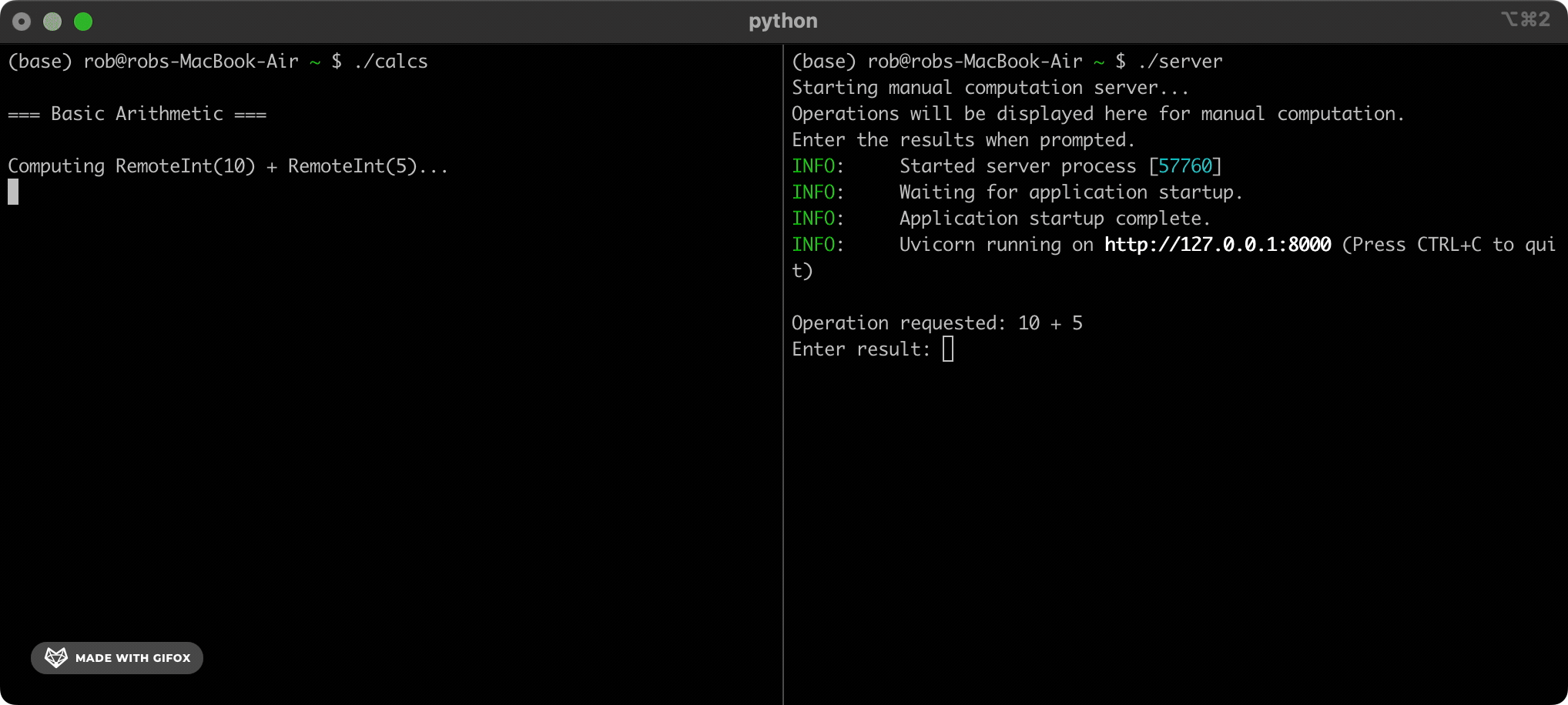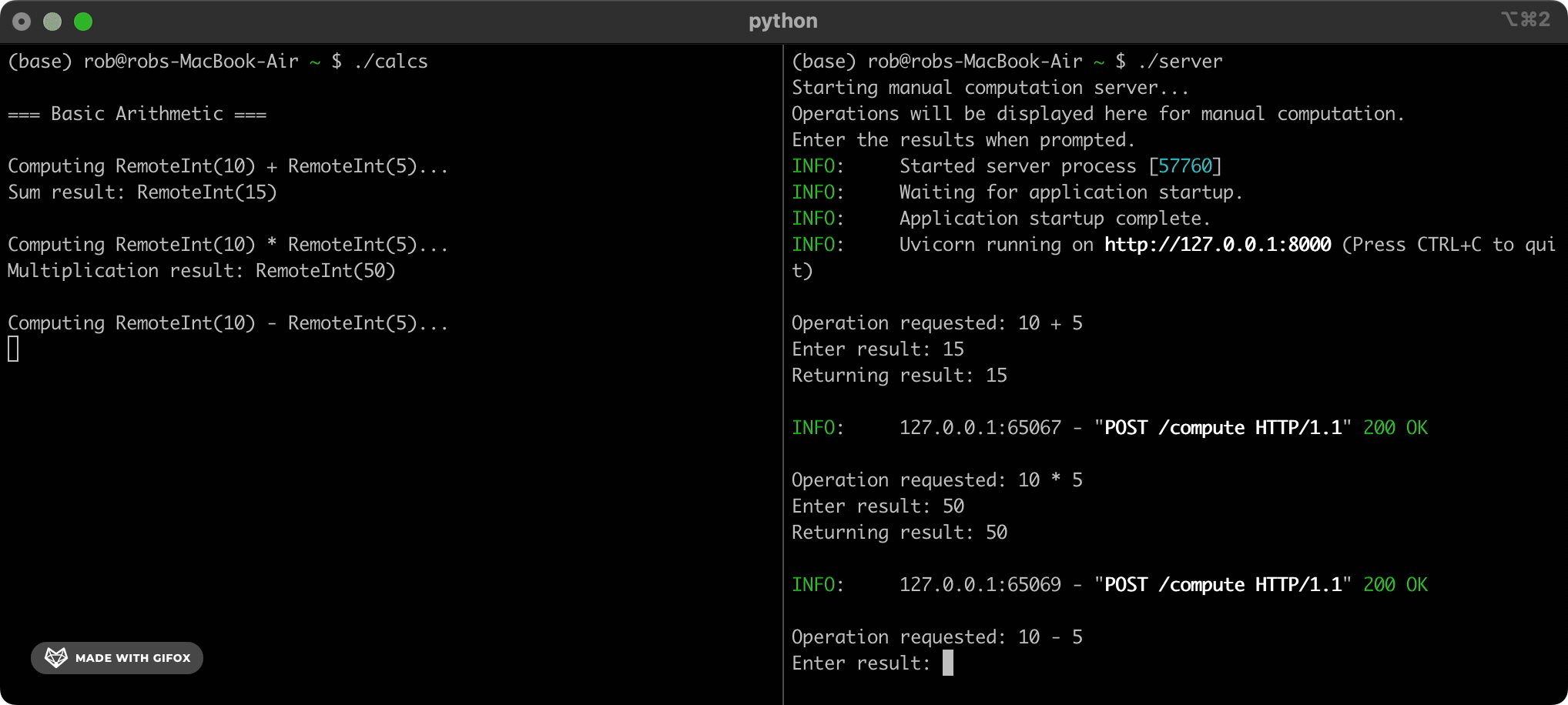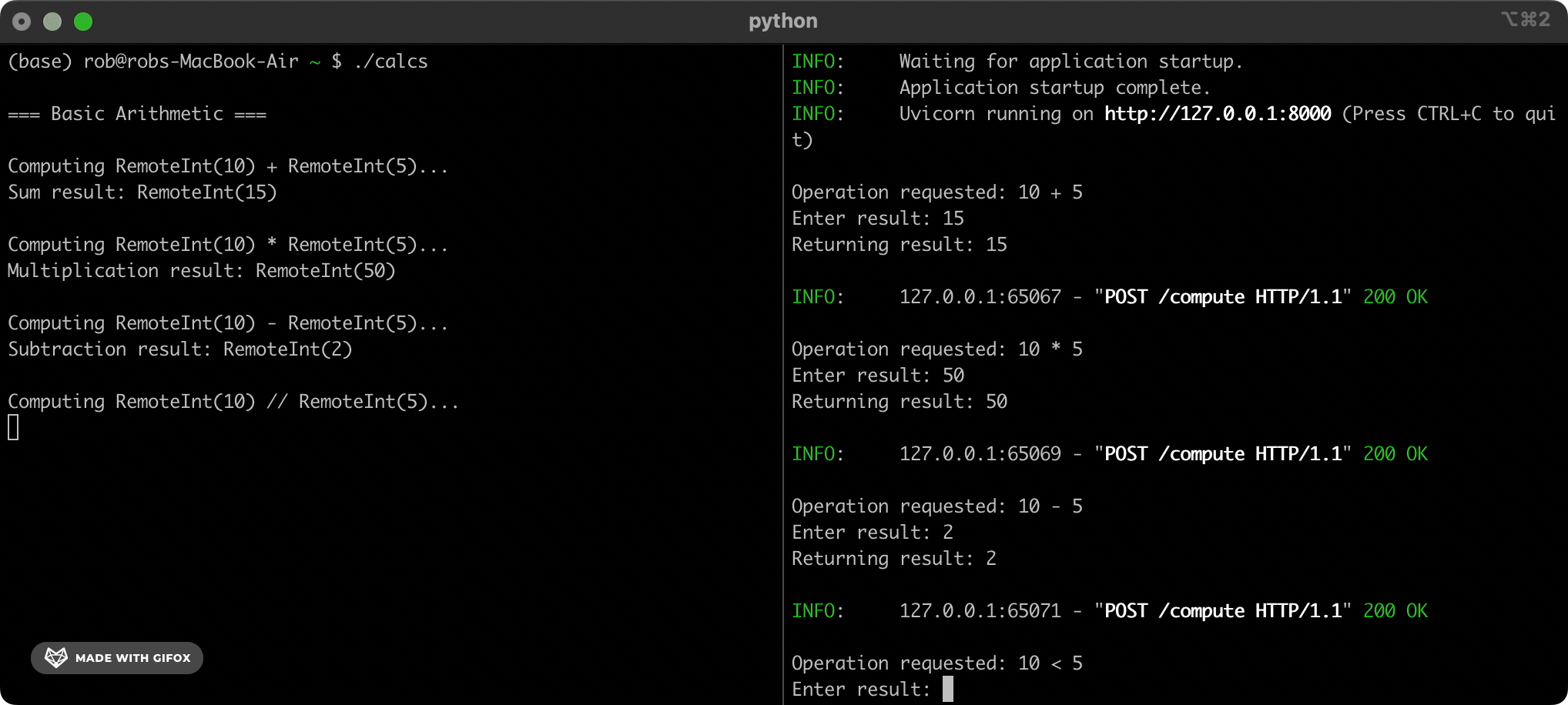
要使用它,我们运行 pip install CUDAAAAGH,然后在通常使用 Python 的标准整数类型的所有地方都使用它的 CUDAAAAGHInt 类。 除此之外,我们像往常一样编写所有代码。 当我们执行我们的程序时,CUDAAAAGH 会自动将任何算术计算卸载到我们的计算伙伴网络,而不是加重我们自己的 CPU 的负担。
例如:
from CUDAAAAGH import CUDAAAAGHInt
x = CUDAAAAGHInt(5)
y = x + CUDAAAAGHInt(10)
# Behind the scenes, this sends the calculation "5+10" to a computation
# partner. Execution pauses until we receive an answer.
print(f"The answer is: {y}")
# => 15
这适用于所有整数运算。 对于像 XOR 这样的复杂运算,CUDAAAAGH 将它们分解为更简单的加法和乘法,我们的计算伙伴会更熟悉这些运算。 然后,它在后台组合他们的答案以计算请求的 XOR:
from CUDAAAAGH import CUDAAAAGHInt
x = CUDAAAAGHInt(0b010100100)
y = x ^ CUDAAAAGHInt(0b111100101)
print(y)
# => 321
在您问之前 - 是的,您绝对可以使用 CUDAAAAGH 来训练 AI 模型。 坚持到最后以获取更多详细信息。
我知道你在想什么:这是天才,这是革命性的,但是 Bitcoin 挖掘是一场速度游戏。 CUDAAAAGH 足够快吗? 我对您说:该死的,是的,它几乎足够快,如果您按照我们的 5 年预测并使用我们关于世界经济方向的非正统假设。
大家抓住你们的支票簿。
是时候开始挖掘了
今天,计算一个 hash 需要 MinorMiner 平台大约 70 亿次操作。 一个现成的 10 岁孩子每 10 秒可以执行一次加法。 包括慷慨的睡眠津贴,这意味着他们每 2,000 年可以计算 1 个 hash。 另一方面,专门的挖掘设备每 0.00000000001 秒可以计算 1 个 hash,并且每 10 分钟挖掘出新的区块。 这些数字不适用于 MinorMiner - 但仍然如此。
幸运的是,MinorMiner 在价值链中处于根本的强势地位。 我们由以前完全浪费的废弃工作提供动力,这意味着我们不需要超级高效才能具有竞争力。 但是,我们仍然需要在挖掘新区块所需的时间内完成每个 hash。 否则,即使我们找到了一个本可以挖掘我们一个区块并赢得一些 Bitcoin 的成功 hash,其他人也已经挖掘了该区块。
这就是为什么 MinorMiner 的首要重点是为我们的 hashrate 提供涡轮增压。 让我告诉您关于我们的三大策略:并行化、课程优化和教师激励对齐。
1. 并行化
首先,并行化。 现在,单个伙伴在单个 hash 上工作。 这意味着即使添加更多的伙伴允许我们同时计算更多的 hash,它也不会减少计算单个 hash 所需的端到端时间。
但是,我们可以比今天更巧妙地在计算伙伴之间分配工作。 我们可以将计算 hash 所需的计算分成独立的块,并且我们可以将这些块交给不同的计算伙伴并行工作。 一旦所有块都完成,我们可以将它们组合起来,并在单个 hash 中向前迈出一大步,而不是在许多不同的 hash 中迈出许多小步。 像这样分散工作可以减少我们计算单个 hash 所需的时间。 这将大大提高我们的竞争力。
“但是 Hobert,SHA-256 不能并行化!” 我听到你尖叫。“它使用顺序块结构,其中每个块的输出是下一个块的输入! 这意味着你不能计算后面的块,直到你先计算了前面的块。 这使得并行化变得不可能!”
你是对的,奇怪地消息灵通的反对者! SHA-256 的大多数实现都不能有效地并行化。 但是,请记住 CUDAAAAGH 将按位运算(如 AND、OR 和 XOR)分解为大量的加法和乘法。 单个 XOR 运算中的许多子计算实际上是独立的,并且不依赖于彼此。 这使得它们易于并行化并获得我一直承诺的大幅加速。
例如,这是我们当前天真的 XOR 实现:
class CUDAAAAGHInt:
def __init__(self, val: int):
self.val = val
def __xor__(self, other: 'CUDAAAAGHInt') -> 'CUDAAAAGHInt':
result = CUDAAAAGHInt(0)
# Calculate the value of each bit, and use bit-shifting to combine
# them using standard integer arithemtic.
for i in range(max(self.bit_length(), other.bit_length())):
bit_self = self._ith_bit(CUDAAAAGHInt(i))
bit_other = other._ith_bit(CUDAAAAGHInt(i))
xor_bit = bit_self + bit_other - CUDAAAAGHInt(2) * bit_self * bit_other
result += xor_bit << CUDAAAAGHInt(i)
return result
def _ith_bit(self, i: 'CUDAAAAGHInt') -> 'CUDAAAAGHInt':
return CUDAAAAGHInt((self.val >> i.val) & 1)
def bit_length(self) -> int:
return self.val.bit_length()
这个实现是串行的并且很慢 - 只要看看那个 for 循环! 但是现在看得更仔细些。 请注意,每次通过循环都完全独立于所有其他循环。 这意味着我们可以并行地单独计算每个位的值,然后在完成后组合所有结果。 我们甚至可以在每个循环中并行计算 bit_x 和 bit_y。
结合这些技巧,我们得到一个并行实现,如下所示:
import asyncio
class CUDAAAAGHInt:
def __init__(self, val: int):
self.val = val
async def __xor__(self, other: 'CUDAAAAGHInt') -> 'CUDAAAAGHInt':
# Calculate a single bit XOR at position i
async def compute_bit_xor(i: int) -> 'CUDAAAAGHInt':
bit_self_task = asyncio.create_task(self._ith_bit(CUDAAAAGHInt(i)))
bit_other_task = asyncio.create_task(other._ith_bit(CUDAAAAGHInt(i)))
bit_self = await bit_self_task
bit_other = await bit_other_task
xor_bit = bit_self + bit_other - CUDAAAAGHInt(2) * bit_self * bit_other
return xor_bit << CUDAAAAGHInt(i)
# Determine the number of bits to process
max_bits = max(self.bit_length(), other.bit_length())
# Calculate all bits concurrently
tasks = [compute_bit_xor(i) for i in range(max_bits)]
all_bits = await asyncio.gather(*tasks)
# Sum the results
result = CUDAAAAGHInt(0)
for bit in all_bits:
result = result + bit
return result
async def _ith_bit(self, i: 'CUDAAAAGHInt') -> 'CUDAAAAGHInt':
return CUDAAAAGHInt((self.val >> i.val) & 1)
def bit_length(self) -> int:
return self.val.bit_length()
这将使我们计算两个数字 M 和 N 的 XOR 的时间减少大约 log2(max(M, N)) 的因子。 我们主要处理 32 位整数,所以这是一个 5 倍的加速。
我相信你们都注意到我们可以使用 map-reduce 方法来为最后的 sum 提供涡轮增压。 我也相信你们中的一些人已经注意到我们可以编写一个 monad,它允许我们优雅地并行化所有内容,到处都是。 我甚至更确定你们中的一个人已经通过电子邮件向我发送了此 monad 的实现,该 monad 是用你自己设计的 Lisp 方言编写的。 给那个人一个公平的警告 - 我不太可能阅读它。
2. 课程优化
我们 xor 实现中 5 倍的加速非常非常非常令人印象深刻,但它仍然是一种hack。 将 XOR 计算分解为加法和乘法从根本上来说是低效的,并且对我们的性能施加了硬性的上限。 为了实现真正的速度和优雅,我们需要直接执行 XOR,而无需将其拆分。
我们没有这样做是因为大多数孩子甚至无法计算基本的 8 位 XOR。 我知道! 当我发现时,我和你一样震惊。 但是这些孩子并不笨; 他们的无知不是他们的错。 他们正在被一个破碎的系统所辜负,该系统未能教会他们在当今高度专业化的经济中竞争所需的技能。
这就是为什么我们成功地游说将 XOR 计算添加到一年级教学大纲中,从即将到来的秋季学期开始。 我们制作了一本教科书,其中包含每个 7 岁儿童应该知道的所有重要的按位运算,包括 XOR、AND、OR 和位移。 这将使我们能够向我们的计算伙伴提出真正有用的问题,例如 2136782 ^ 2136821 是多少?,而不是用简单的计算来填饱他们。 我们预测这将导致 hashrate 进一步加速大约 100 倍,并且我们预计在明年第一季度开始看到结果,在单元测验结束后开始生效。
“教会一个人 hash,你会等等等等。”
但是为什么要停止 XOR 呢? 想想在过去十年左右的时间里,传统的挖掘是如何发展的。 第一个 Bitcoins 是在普通计算机上使用普通 CPU 挖掘出来的。 如今,所有 bitcoins 都是使用称为 ASIC 的专用计算机挖掘出来的,这些计算机硬连线用于计算 hash 而已。 为了参与竞争,我们必须训练人类 ASIC。
孩子们需要学习如何自己端到端地计算 SHA-256。 这就是为什么我们如此积极地支持 SB-1337 - “不让一个孩子被遗漏”。 SB-1337 将用一个深入的、端到端的关于手动计算 SHA-256 hash 的课程来取代过时的 7 年级数学教学大纲。 它将允许我们停止向学生发送微不足道的加法和乘法,而是向他们发送真正的数学:
问题 1:
01003ba3edfd7a...? 的 SHA-256 hash 是多少? (3 分)
问题 2:
01003ba3edfd7b...? 的 SHA-256 hash 是多少? (3 分)
我们将能够直接将他们的作业变成 bitcoins,而无需任何中间计算。 在这一点上,我们所需要做的就是扩展规模。 这就引出了我们的最后一个加速技术:教师激励对齐
3. 教师激励对齐
起初,我们的一些新分销伙伴(或者在传统系统中被称为教师)……对拥抱我们的新的以 hash 为中心的课程有些犹豫。 幸运的是,当他们了解我们的教师激励对齐计划 (TIA) 时,这种情况发生了改变。
TIA 允许我们使用滑动比例费用来补偿分销伙伴的辛勤工作,该费用针对其计算伙伴(或“学生”)产生的每十亿个 hash。 有了 TIA,无论何时我们获利,他们也会获利。 当然,计算伙伴也会通过参与 MinorMiner 获得的宝贵知识和实践来获利。
我们发现,参加 TIA 计划的分销伙伴比没有参加该计划的分销伙伴设置的作业问题多 1,000,000%。 例如,一位特别热心的合作伙伴给他们的伙伴设置了以下测验:
问题 1,共 1,471,126,723 个问题
01003ba3edfd7a...? 的 SHA-256 hash 是多少? (0.0000000001 分)
问题 2,共 1,471,126,723 个问题
01003ba3edfd7b...? 的 SHA-256 hash 是多少? (0.0000000001 分)
(以此类推,还有 1,471,126,721 个问题)
一些合伙人最初担心他们的计算伙伴可能会对如此雄心勃勃的工作量感到犹豫,尽管他们会从中获得所有的知识和实践经验等等。 他们担心一些合作伙伴可能会作弊并使用专门的挖掘软件来完成他们的 hashing 作业。 幸运的是,我们能够使用电子表格和大量的眨眼来帮助他们中的大多数人意识到这可能实际上不是一个问题。
MinorMiner 希望明确表示,我们绝不纵容作弊行为。 严格禁止使用我们的作业提交 API 及其关联的 SDK。
简而言之 - 是的,我们将足够快。 通过并行化、课程优化和教师激励对齐,我们相信我们已经做好了充分的准备,可以在未来几年内加速并大规模扩展规模。 那么呢?
从 Bitcoin 到 AI
在我们完善了 Bitcoin 用例之后,我们将直接转向 AI。 我们已经在使用 pytorch 绑定扩展 CUDAAAAGH,这将允许用户使用我们独特的计算平台运行他们的训练和推理代码。 大多数孩子不太了解矩阵代数,但是矩阵代数只是用有趣的符号包裹起来的加法和乘法。 我们所需要做的就是使用 CUDAAAAGH 实现矩阵乘法,我们将非常非常幸运。 如果我们的下一个立法重点 (SB-80085) 通过,那么矩阵代数也将很快出现在八年级课程中。 这又是课程优化。
def matmul(m1: CUDAAAAGHMatrix, m2: CUDAAAAGHMatrix) -> CUDAAAAGHMatrix:
# (Implementation left as an exercise for the reader, you get
# the joke by now)
将 CUDAAAAGH 应用于 AI 提出了一些令人愉快的哲学问题。 你是否已经对足够先进的 AI 模型是否应该被视为有意识的存在感到非常困惑? 我们是否有道德义务关心他们的福利? 如果 AI 模型是数十亿儿童完成数学作业的涌现特性,那么这些问题会变得更加令人困惑吗?
在 AI 之后我们将做什么? 云计算,女士们先生们,云计算。 孩子们是商品硬件。 我们远大的目标是使用它们来实现整个计算机。 计算机通常有电子的任何地方,我们将用一个学龄儿童来代替它做数学作业。 CPU 成为执行极其专业的运算的专业儿童。 硬盘驱动器成为记住 1 和 0 的儿童阵列。 主板成为决定向其他人发送什么消息的儿童线。 想想其中的含义! 每个人都可以免费使用电脑!
这就是我今天要说的全部内容,感谢您的聆听。 相信孩子们! 投资 MinorMiner pre-seed! 排成有序的队伍! 将您的支票支付给“Hobert Reaton”。 不,夫人,末尾没有“LLC”。 只是“Hobert Reaton”。 我也接受现金和各种 memecoin。 这是我的钱包地址。 谢谢。
CUDAAAAGH isavailable on GitHub. It can also be installed from PyPi using pip install CUDAAAAGH although I can’t imagine why on earth you would do this.
获取发送给你的新文章
订阅我的关于编程、安全以及其他几个主题的新作品。 每月发布几次。 订阅 在 Twitter 上关注我 ➜ RSS ➜