层层深入:Shader 编译的幕后故事
Layers All The Way Down: The Untold Story of Shader Compilation
2024-07-01
背景
作为一名主要在框架而非引擎中工作的游戏开发者,最大的痛点之一就是需要在多个平台上高效渲染。对于大多数平台级别的任务,例如窗口管理、输入处理等,SDL做得非常出色,我几乎不用为此操心。
相比之下,渲染就是一个巨大的难题。每个平台都有其独特的支持矩阵。对于 Windows,你有 D3D12/D3D11/Vulkan/OpenGL。对于 Apple 平台,你有 Metal 和 OpenGL,或者 iOS/tvOS 上的 OpenGL ES。对于 Linux 和 Nintendo,你有 Vulkan 和 OpenGL。对于 PlayStation,你有他们那边正在使用的东西。对于 Xbox,你只有 D3D12。Android 有 Vulkan 和 OpenGL ES。你明白了吧。
所有这些硬件加速 API 都有相似之处,但它们之间的差异也足够大,以至于将你所需的所有功能映射到它们上面并非易事。
我是 FNA project 的共同维护者,该项目旨在在现代平台上保留 XNA 框架。作为这项工作的一部分,几年来我一直在开发我们的跨平台图形抽象 FNA3D,特别是 Vulkan 实现。这个库允许我们将 XNA 图形调用转换为现代系统。
我在该项目上的工作促使我创建了 Refresh,它具有类似的架构,但受到 Vulkan 结构的启发,并在几个关键方面进行了现代化改造。在过去的几个月里,我一直在努力将该 API 的一个版本作为 提案提交给 SDL。Ryan C. Gordon (又名 icculus) 几年前宣布计划在 SDL 中包含一个 GPU API。Refresh 仅在一些小细节上与他的提案不同,而且实现也基本完成,因此 FNA 团队提交了我编写的内容,希望能节省一些时间和开发者精力。
在很大程度上,这得到了相当好的评价,但我们被反复问到一个问题。目前我们支持 Vulkan、Metal 和 D3D11,其他后端即将推出。在我们的 API 中,要创建一个 shader 对象,你必须提交 SPIR-V(我们在运行时对其进行转译)、特定后端支持的高级语言或特定后端支持的 bytecode。我们为什么要这样设计?为了回答这个问题,我将尝试解释当今图形领域的一些技术和政治挑战。
什么是 Shader?
在过去,图形 API 由映射到专用硬件逻辑的函数入口点组成。这被称为固定功能 API。OpenGL 在 2 版本之前是一个固定功能 API,Direct3D 在 8 版本之前也是如此。你拥有这些 API 提供的用于调制数据的函数,仅此而已。
随着 GL2 和 D3D8 的出现,引入了可编程 shader 阶段的概念。这使得渲染具有更大的灵活性。
Shader 实际上是一个在 GPU 上执行的大规模并行程序。Shader 的任务是并行转换大量数据。一个 vertex shader 接收顶点数据并并行转换每个顶点。一个 fragment shader 接收来自 vertex shader 和硬件光栅化过程的转换信息,以并行地将颜色值输出到每个光栅化像素。一个 compute shader 并行转换或多或少任意的数据。
在稍晚些的时候,这些 API 会接收高级 shader 程序。你会以文本格式编写 shader 代码,将其传递给 API,然后它会尝试在运行时编译 shader。这种方法有一些显著的缺点:这意味着驱动程序作者必须在其驱动程序中包含完整的编译器,并且解析和编译需要相当多的计算时间,这很尴尬,特别是当你试图达到每帧 16 毫秒或尽量减少前期加载时间时。这也意味着,如果驱动程序存在编译器错误,你只能在特定安装上的运行时发现。糟糕!在现代 API 中,你改为将 bytecode(或中间表示)传递给驱动程序,从而减少了大量复杂性。但是,这些 bytecode 程序仍然必须编译为本机可执行格式。
让我们稍微退一步。现在的编程语言非常抽象,因此很容易忘记程序必须转换为实际的机器代码才能执行。考虑一下两种常见的 CPU 指令集 x86 和 ARM。这些指令集已经变得如此标准,以至于我们大多数人都认为基本上每个 CPU 都会使用其中一个,这是理所当然的。当你编译程序时,你会将其编译为其中一个指令集,并且你在绝大多数实际硬件上都获得了支持。
GPU 也不例外,程序必须在实际硬件上运行。虽然 x86 和 ARM 在 CPU 领域的指令集之战中胜出,但 GPU 的情况远未达到这种标准化程度。每个制造商 都有独特的 GPU 架构和指令集架构 (ISA),并且他们通常同时支持其架构的 多个世代。Nvidia 有 Lovelace、Ampere、Turing 等。AMD 有 RDNA3、RDNA2 等。如果你认为这些很简单,AMD 会发布其 ISA 规范,而且我上次查看时,RDNA2 文档长达 290 页。
当你将 bytecode 提交给驱动程序时,它必须专门为你的机器上的图形硬件编译该 bytecode。编译后的 shader 只能在该特定设备和驱动程序版本上执行。但情况甚至更糟。每个图形 API 都有竞争形式的 bytecode。Vulkan 有 SPIR-V,D3D 有 DXIL/DXBC,Metal 有 AIR。SPIR-V 至少试图成为一种标准的、可移植的中间表示(尽管 针对其采用存在字面上的企业破坏行为),这要归功于 Khronos Group。感谢 SPIRV-Cross,我们可以将编译后的 SPIR-V bytecode 转换为 HLSL 和 MSL 等高级格式,从而实现一定程度的可移植性。
这让我想到了以下可能存在争议的声明:
Shader 是内容,不是代码
我知道,我知道。你实际上是通过编写 shader 代码来创建 shader。
如果事情如此简单就好了。让我们描述一下在 HLSL 中编写 vertex shader 并加载它的过程。
在 D3D11 上:
- 你使用 HLSL 编写你的 shader。
- 在某个时候,无论是在运行时还是在构建时,你都会调用 D3DCompile 以发出 DXBC (DirectX Bytecode)。
- 在运行时,你使用你的 bytecode 调用 ID3D11Device_CreateVertexShader 以获取一个 shader 对象。
在 Vulkan 上:
- 你使用 HLSL(带有 SPIR-V 绑定注释)编写你的 shader。
- 在构建时,你使用 glslang 等工具发出 SPIR-V bytecode。
- 在运行时,你调用 vkCreateShaderModule 以获取一个 shader 对象。
在 Metal 上:
- 你使用 HLSL 编写你的 shader。
- 在构建时,你发出 SPIR-V bytecode。
- 你使用 SPIRV-Cross 将 SPIR-V 转换为 MSL。
- 在运行时,你调用 Metal 的 newLibraryWithSource 以获取一个 shader 对象。
当然,shader 对象本身什么也不做 - 它需要成为 pipeline 对象的一部分。pipeline 需要了解顶点输入结构和 shader 使用的数据资源(纹理、采样器、缓冲区)。没有通用方法 可以从 shader 代码中提取此信息。你必须手动提供它,或者使用特定于语言的工具来反射代码(这在运行时执行起来很昂贵,并且在特定设备上发布时有时不可用)。此外,创建 pipeline 对象包含后端特定的怪癖。例如,在大多数 API 中,compute shader workgroup 大小是在 shader bytecode 中提供的。在 Metal 上,客户端应在调度时提供此信息。设计一个可以适应所有这些差异的单一接口一直是一个巨大的挑战。
Shader 是高度不灵活的程序,需要配置大量状态才能正常工作。单个 shader 程序旨在适应特定任务。以我的经验,我不会经常迭代 shader。我为几个特定的渲染任务编写几个 shader,设置我的 pipeline,然后除非某些渲染要求发生变化,否则我不会触及它们。(在现代游戏引擎上的一些艺术家驱动的 shader 工作流程中存在例外。我对这对客户来说有多好有一些想法,但简而言之,这就是为什么你在第一次运行 Unreal Engine 游戏时或每次更新图形驱动程序时都必须等待 20 分钟才能编译 shader。)
作为一个类比,考虑一下有效渲染使用 2D sprite 的游戏的过程。你可以将每个单独的 sprite 加载为单独的纹理,但现在你必须为每个绘制调用更改纹理,这非常低效。正确的方法是在构建时将 sprite 打包到 sprite sheet 中,以便它们都在同一个纹理上,然后你可以将多个 sprite 批处理到单个绘制调用中。通常,方便生产的内容对于计算机来说不是有效利用的内容。需要一个步骤来将该内容转换为有效的内容。
为了清楚地重申 shader 编译链,你有
high-level source -> bytecode compiler -> (bytecode transpiler -> bytecode compiler) -> API frontend -> driver compiler -> ISA
我的观点是:将 shader 代码转换为可执行代码的过程更像是内容烘焙和加载,而不是编译你游戏的代码库。Shader 需要复杂的转换和许多上下文依赖关系才能使用,并且它们通常不是日常代码开发工作流程的一部分。在通常的生产场景中,shader 只需要在艺术要求发生变化时编写或更新。
为什么加载 shader 如此混乱?
要回答这个问题,我们必须检查硬件和软件行业的利益相关者,以及他们的既得利益。
假设你是 Apple。你的整个商业模式都建立在将你的客户锁定在一个封闭的花园中。从创建或支持可移植 shader 格式中你能获得什么好处?你控制着你的生态系统的每个级别,从芯片制造一直到操作系统和应用程序级别。这是你的方式或高速公路。支持易于移植的软件所能为你做的就是让你的客户更容易地从 Apple 设备切换出去。
Microsoft 的情况类似,至少在 Xbox 方面是这样。他们允许你使用的唯一 API 是 D3D12。他们为什么要支持其他任何东西?他们完全控制着硬件和驱动程序。令人着迷的是,唯一采用开放标准的制造商是……Nintendo,它在 Switch 上支持 Vulkan。我不知道他们为什么要这样做,但我当然不会抱怨。
在 GPU 制造商方面,情况并没有太大差异。值得称赞的是,在 API 级别,GPU 制造商确实为开放标准做出了贡献(Vulkan 最初是 AMD 的一个名为 Mantle 的研究项目,已捐赠给 Khronos Group)。但是,通用 shader ISA 的实现希望渺茫。根据最新的 Steam 硬件调查,Nvidia 控制着 GPU 市场份额的 75%。与其他制造商合作开发标准化 ISA 只会减慢它们的速度,并让竞争对手深入了解它们的架构开发过程。
最终,这些参与者没有相互合作的经济动机。所有这些碎片化的成本都落在了希望他们的程序能够在不同的机器上运行而没有太多麻烦的开发人员身上。这就是生活。
Shader 语言问题
可移植的高级 shader 语言不是可以解决这些问题吗?我理解这种方法的吸引力。这将意味着在 API 级别,客户端不必担心所有这些不同的格式。他们可以只编写 shader 代码,将其传递给 API,然后它就可以正常工作。我们甚至可以提供一种预先查询 shader 资源使用情况的方法。一切似乎都很简单!

首先,我不确定这种方法是否真正解决了根本问题。正如我之前明确指出的那样,我们必须将代码转换为可以在各种图形设备上实际运行的东西。这并不是你可以在漫长的周末破解出来的东西。
更大的问题是:为什么一个小型的、工作过度的开源开发人员小组应该解决一个整个行业都创造了并且缺乏解决动机的问题?在这一点上,我们认真考虑我们唯一合理的解决方案是设计和维护不仅是一种完整的编程语言,而且是一种 bytecode 格式 和 一个将该 bytecode 格式转换为驱动程序可以实际加载的格式的翻译系统,我认为我们完全迷失了方向。这里的根本问题是没有标准化的 shader ISA 甚至 bytecode 存在,并且没有任何供应商有实际的动机去创建或同意一个。问题是碎片化,而碎片化在我们有能力解决的层面上极其难以解决。
我们希望通过我们的 SDL GPU 提案解决的问题是,图形 API 的碎片化程度使得编写可移植的硬件加速应用程序非常困难。在代码 调用 级别解决这种碎片化已经足够具有挑战性了 - 在代码 生成 级别解决碎片化比我们已经完成的要复杂一个数量级。
无论如何强调承担这项任务的复杂性都是困难的。采用自定义 shader 语言使 WebGPU(一个涉及一些世界上最强大的科技公司且拥有专职人员的 W3C 提案)推迟了 数年。WebGPU 仍然没有完成。(它可能永远不会完成。)
此外,可移植的高级 shader 语言已经存在。考虑 HLSL:它被广泛采用,并且可以编译为 DXBC、DXIL 和 SPIR-V,这意味着它可以(在 Apple 平台上借助 SPIRV-Cross)用作当前任何可用的桌面图形 API 的源语言。目前尚不清楚我们是否可以对已经存在的东西进行实质性的改进,当然也不可能在短时间内做到这一点。
我不想让人觉得我反对尝试高级方法。如果有一个包含电池的解决方案库,适用于 95% 的用例,那就太好了。我只是认为在我们的 API 级别强制使用高级语言会大大延迟项目,甚至可能无限期地延迟项目,并且会对工作流程施加很大的限制。开发人员对他们的工作流程非常固执己见,即使有优势,也不清楚强迫每个人都使用自定义高级语言是否会顺利进行。这可能足以阻止某些人完全使用该 API。
我们的方法不 禁止 创建可移植的 shader 语言,但这意味着我们不必 依赖 一种。我们的方法是低维护的,现在就可以工作,并且不会将你锁定到特定的工作流程中。
我们提出的方法
以下是我们当前的 shader 创建设置:
typedef enum SDL_GpuShaderStage
{
SDL_GPU_SHADERSTAGE_VERTEX,
SDL_GPU_SHADERSTAGE_FRAGMENT
} SDL_GpuShaderStage;
typedef enum SDL_GpuShaderFormat
{
SDL_GPU_SHADERFORMAT_INVALID,
SDL_GPU_SHADERFORMAT_SPIRV, /* Vulkan, any SPIRV-Cross target */
SDL_GPU_SHADERFORMAT_HLSL, /* D3D11, D3D12 */
SDL_GPU_SHADERFORMAT_DXBC, /* D3D11, D3D12 */
SDL_GPU_SHADERFORMAT_DXIL, /* D3D12 */
SDL_GPU_SHADERFORMAT_MSL, /* Metal */
SDL_GPU_SHADERFORMAT_METALLIB, /* Metal */
SDL_GPU_SHADERFORMAT_SECRET /* NDA'd platforms */
} SDL_GpuShaderFormat;
typedef struct SDL_GpuShaderCreateInfo
{
size_t codeSize;
const Uint8 *code;
const char *entryPointName;
SDL_GpuShaderFormat format;
SDL_GpuShaderStage stage;
Uint32 samplerCount;
Uint32 storageTextureCount;
Uint32 storageBufferCount;
Uint32 uniformBufferCount;
} SDL_GpuShaderCreateInfo;
extern SDL_DECLSPEC SDL_GpuShader *SDLCALL SDL_GpuCreateShader(
SDL_GpuDevice *device,
SDL_GpuShaderCreateInfo *shaderCreateInfo);
因为我们要求你提供代码旁边的格式,这使得你可以使用任何你可能需要的在线或离线编译方案。例如,在你的构建步骤中,你可以使用 HLSL 生成 SPIR-V,使用 SPIRV-Reflect 从 shader 中提取资源使用信息,然后将该数据传递给 SDL_GpuCreateShader。你还可以在构建时使用 SPIRV-Cross 从你的 SPIR-V 输出生成 MSL,然后为你的 Apple 目标加载该 MSL 代码。本着我声明 shader 是内容而不是代码的精神,我认为开发一个与你喜欢使用 shader 的方式相匹配的工作流程是有意义的。有很多权衡需要考虑,没有一个正确的答案。如果你喜欢 GLSL 而不是 HLSL,那就去吧。做对你的项目有效的事情。
这种方法可以灵活地工作的一个最好的例子是我们为 FNA3D 实现的 SDL GPU 后端。FNA 是一个保存项目,这意味着我们并不总是可以访问源代码。当你发布一个 XNA 游戏时,shader 会以一种名为 FX bytecode 的二进制格式出现。我们必须将 FX bytecode 转换为在现代图形 API 上工作的格式,我们使用一个名为 Mojoshader 的库来完成此操作。由于 Mojoshader 已经可以将 FX bytecode 转换为 SPIR-V,并且 SPIRV-Cross 存在,我们可以将 SPIR-V 用作所有 GPU 后端的真实来源。本质上,我们有一个以 FX bytecode 为源的在线 shader 编译 pipeline,并且它的工作效果很好:
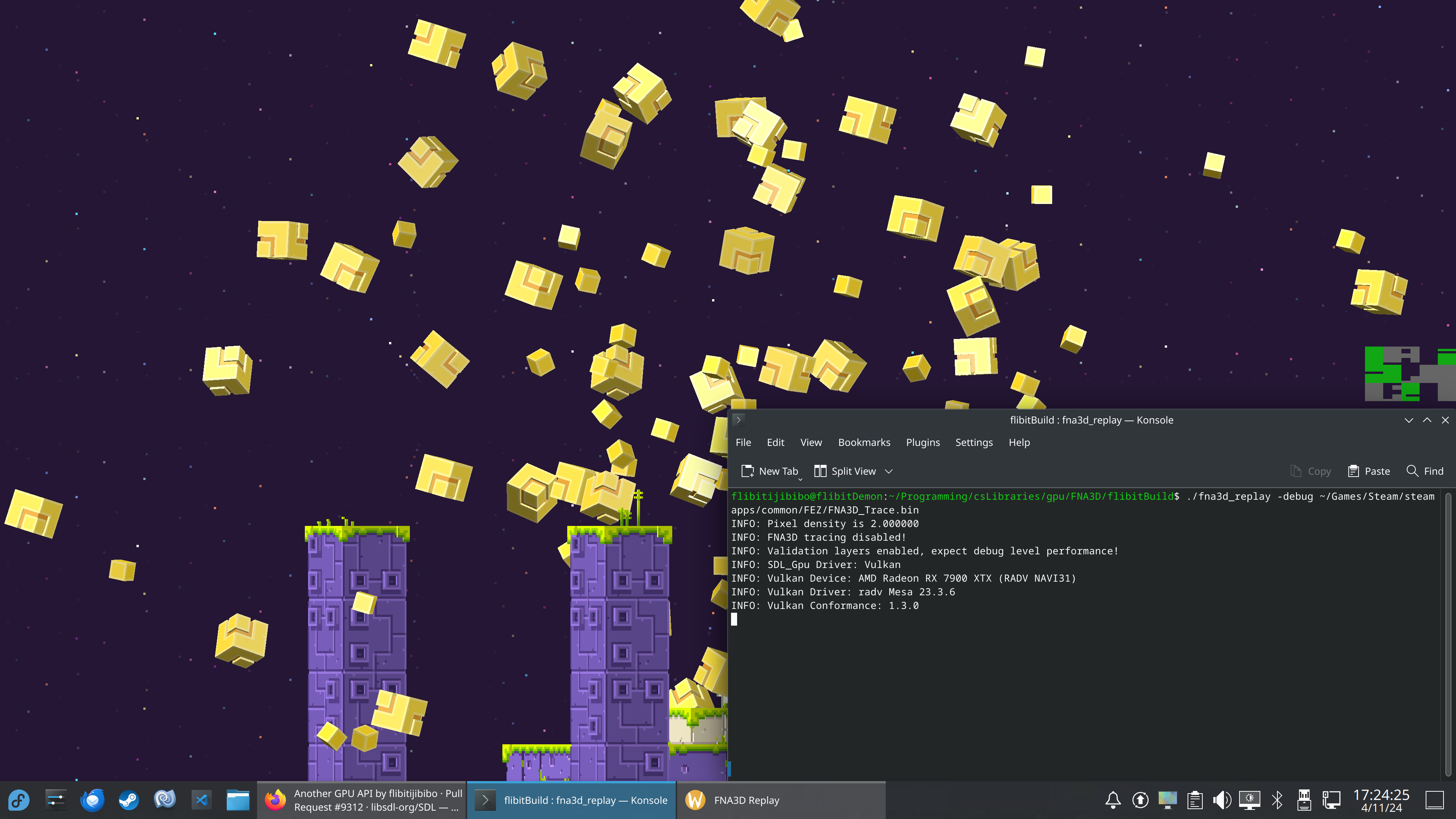
我认为考虑到我们所处的情况,我们已经尽力达成了一个体面的妥协方案。你可能会争辩说,必须为不同的后端提供不同的 shader 格式意味着 API 并非真正可移植的 - 但不存在的解决方案是最不可移植的。