Telum II at Hot Chips 2024: Mainframe with a Unique Caching Strategy
标题:Hot Chips 2024 上的 Telum II:具有独特缓存策略的大型主机
Chips and Cheese
Chester Lam Sep 08, 2024
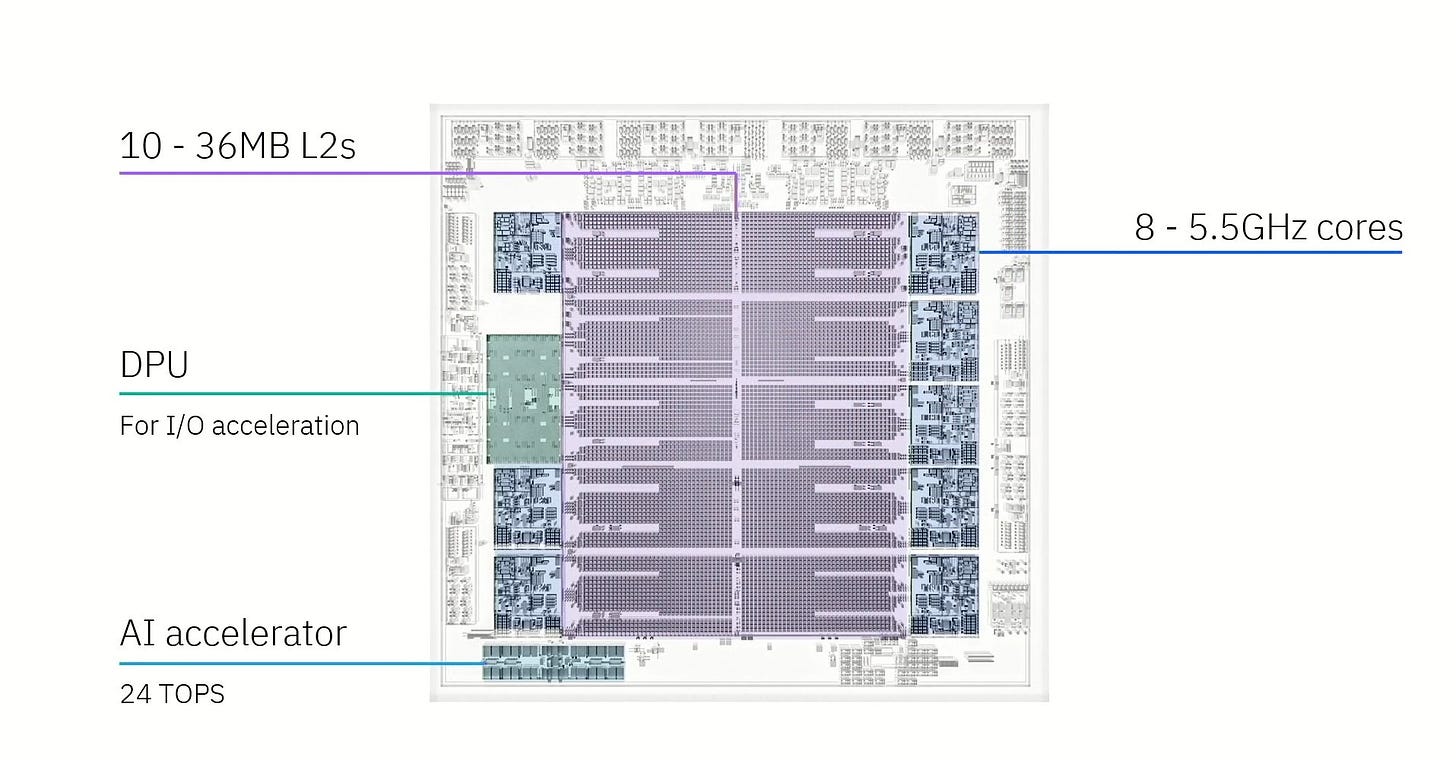
大型主机在当今仍然发挥着至关重要的作用,为金融交易提供极高的正常运行时间和低延迟。Telum II 是 IBM 最新的大型主机处理器,其设计与其他任何服务器 CPU 都不同。它只有八个核心,但以非常高的 5.5 GHz 运行,并为其提供 360 MB 的片上缓存。IBM 还包括一个 DPU 用于加速 IO,以及一个板载 AI 加速器。Telum II 采用 Samsung 领先的 5 nm 工艺节点实现。
IBM 的演示文稿已经被其他媒体报道过。因此,我将重点介绍我认为 Telum (II) 最有趣的特性。DRAM 延迟和带宽限制通常意味着良好的缓存对于性能至关重要,而 IBM 经常部署有趣的缓存解决方案。Telum II 也不例外,它延续了之前 IBM 芯片的虚拟 L3 和虚拟 L4 策略。
虚拟 L3
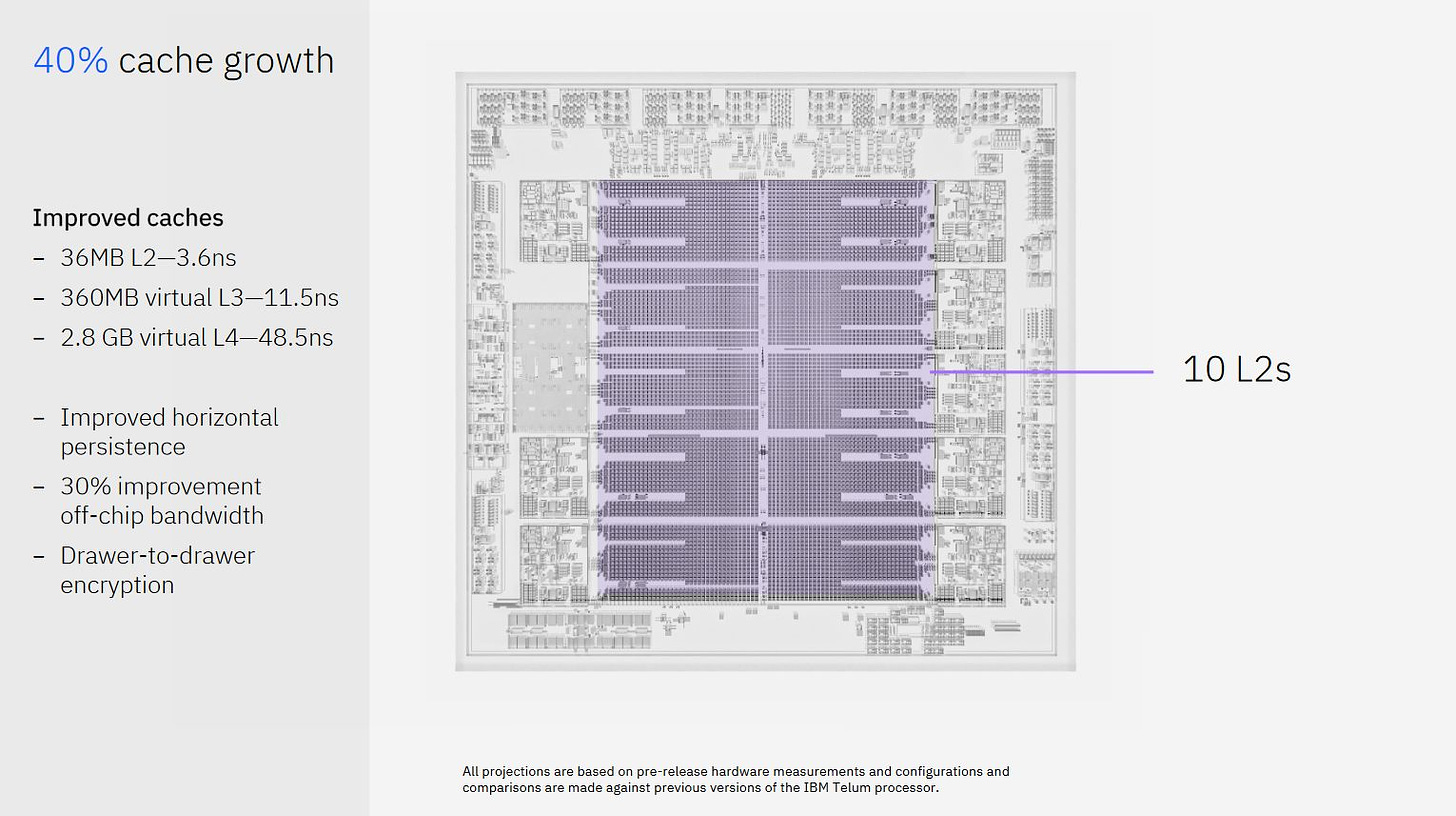
Telum II 具有十个 36 MB 的片上 L2,这绝对是巨大的。从对比的角度来看,AMD 的 Zen 3 桌面和服务器 CPU 上的 L3 缓存通常为 32 MB。Telum II 的八个 L2 缓存连接到核心,另一个连接到 DPU,最后一个没有连接到任何东西。另一个比较是 Qualcomm 的 Snapdragon X Elite 中的 Oryon 核心,它具有 12 MB 的 L2 缓存,延迟为 5.29 ns。Qualcomm 认为这是一个紧密集成了高容量的缓存。Telum II 具有 3.6 ns 的 L2 延迟,并且具有更大的容量。
Qualcomm 的 Oryon 具有 5.28 ns 的 L2 延迟
这些巨大的 L2 对于减少内存访问延迟非常有用,但也使 Telum II 处于一个有趣的境地。现代 CPU 通常具有一个在多个核心之间共享的大型缓存。共享缓存可以在低线程负载下为单个线程提供更大的容量,并减少多线程负载中共享数据的重复。但是 Telum II 中的八个核心已经使用了 288 MB 的 SRAM 容量,以及相关的面积和功耗成本。即使对于专用的大型主机芯片,更大的 L3 也会非常昂贵。
 绿色 = L2,红色 = L3
绿色 = L2,红色 = L3
IBM 的解决方案是减少其缓存中的数据重复,并重复利用芯片的大量 L2 容量来创建虚拟 L3 缓存。根据 IBM 的专利,每个 L2 都有一个“饱和度指标”,该指标基于其核心将数据带入其中的频率(以满足未命中)。当 L2 逐出缓存行以为传入数据腾出空间时,该逐出的行将转到具有较低饱和度指标的另一个 L2。这样,已经达到自身 L2 容量限制的核心可以将该容量保留给自己。没有附加核心的 L2 切片始终具有可能的最低饱和度指标,使其成为从 L2 逐出的行的首选目的地。如果另一个 L2 已经具有逐出行的一个副本,则 Telum II 将该行的所有权授予该 L2,而不是将其放入虚拟 L3 中,从而减少数据重复。
 绿色 = L2,红色 = 虚拟 L3(从 L2 逐出的行保留在其他 L2 中)
绿色 = L2,红色 = 虚拟 L3(从 L2 逐出的行保留在其他 L2 中)
跟踪饱和度指标并不是 IBM 阻止虚拟 L3 垄断 L2 容量的唯一方法。IBM 的专利还提到将虚拟 L3 行插入到中间 LRU 位置。替换策略是缓存选择逐出哪一行以换取新行调入的策略。LRU 代表最近最少使用,是一种替换策略,其中最近最少使用的行将被逐出。通常,新插入的行将被放入 MRU(最近最多使用)位置,使其在要替换的队列中排在最后。但是虚拟 L3 行可以被放置在中间位置,从而优先考虑核心带入的 L2 行。

使用中间位置还使 IBM 可以控制虚拟 L3 可以使用多少 L2 容量。例如,将虚拟 L3 填充放置在 LRU 和 MRU 位置之间的一半处,会将虚拟 L3 限制为使用 L2 容量的一半。很容易看出 IBM 如何使用它来优雅地适应不断变化的应用程序需求。如果一个核心进入空闲状态,则其 L2 可以开始在 LRU 位置插入虚拟 L3 填充,从而使虚拟 L3 使用该切片中的所有可用容量。
除了防止 L2 容量被挤出外,虚拟 L3 还面临另一个挑战。虚拟 L3 中的行可能位于 Telum II 的十个 L2 切片中的任何一个中。在 AMD、Arm 和 Intel 的 L3 缓存中,地址始终转到同一切片。核心可以查看地址的子集,并且确切地知道要将请求发送到哪个 L3 切片。IBM 的情况并非如此。显然,IBM 通过可能检查所有 L2 切片以进行虚拟 L3 访问来处理此问题。我问他们是否担心更多标签比较带来的开销,但他们说这不是问题,因为 L2 未命中率很低。重要的是要记住,工程师会尝试保持 CPU 设计的平衡,而不是投入资源来确保它在每一件事上都表现出色。Telum II 核心最多可以使用 36 MB 的 L2 容量。在其他因素相同的情况下,它的 L2 未命中率应低于 Zen 5 核心在其 32 MB L3 中的未命中率。Zen 5 上的 L3 访问可能花费更少的功率,但 AMD 需要这样做,因为 Zen 5 核心的 L2 容量比 Telum II 核心小一个数量级。
为什么止步于 L3?
IBM 的大型主机芯片不是孤立部署的。最多可以将 32 个 Telum II 处理器连接起来,以形成一个大型共享内存系统。同样,IBM 正在关注大量的缓存容量,这次是在一个系统中而不是在单个 Telum II 芯片中。同样,他们也应用了相同的虚拟缓存概念。Telum II 通过将 L3 的牺牲品发送到具有备用缓存容量的其他 Telum II 芯片来创建一个 2.8 GB 的虚拟 L4。
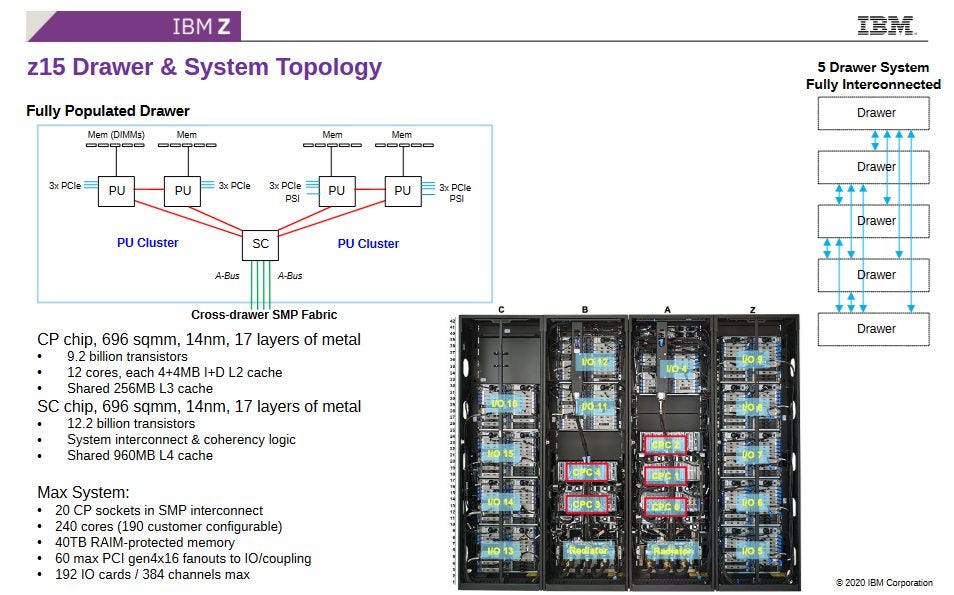
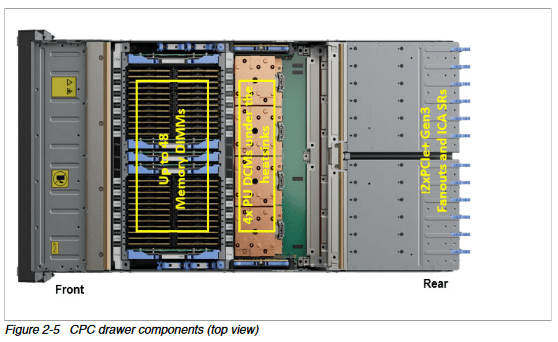 先前的 Z16/Telum 上的 CPC(中央处理器复合体)抽屉
先前的 Z16/Telum 上的 CPC(中央处理器复合体)抽屉
我不确定 IBM 如何实现虚拟 L4,但是先前的 IBM 大型主机设计可能会提供一些线索。IBM 将大型主机 CPU 组织成 CPC 抽屉,这有点像机架式服务器。CPC 无法像服务器一样独立运行,因为它不包括非易失性存储或电源单元,但它的确将一组 CPU 和 DRAM 放置在彼此靠近的物理位置。先前的 IBM 设计具有整个抽屉范围的 L4,而 Telum II 可能会做同样的事情。2.8 GB 的 L4 与八个 Telum II 芯片的片上缓存容量一致。如果一个抽屉有八个 Telum II 裸片,就像 Z16 抽屉有八个 Telum 裸片一样,那么 IBM 可能会在整个抽屉中保留 L3 的牺牲品。
 再往前追溯一代,
再往前追溯一代,z15 具有一个系统控制器 (SC) 芯片,该芯片具有一个巨大的 960 MB 的 L4,该 L4 在整个抽屉中共享
IBM 声称虚拟 L4 访问的延迟为 48.5 ns。在抽屉边界上实现这一点将是一个相当大的挑战。尽管 Telum II 雄心勃勃,但我认为这将是过于夸张了。关于延迟问题,IBM 可能是在打赌 L3 未命中非常罕见,以至于 48.5 ns 的 L4 延迟无关紧要。IBM 还应该因在跨越芯片边界时使延迟如此之低而受到赞扬。从对比的角度来看,Nvidia 的 Grace 超级芯片的单片模具的 L3 延迟超过 42 ns。
回顾 Telum
在谈论 Telum II 的缓存策略时,不可能忽略原始的 Telum/Z16。IBM 在那里将其虚拟 L3 和 L4 缓存引入到其大型主机系列中。Telum 在去年的 Hot Chips 2023 上进行了介绍。从那时起,IBM 发布了更多关于 Telum 的虚拟 L3/L4 设置如何工作的信息。这是一个相当简单的方案,其中每个 32 MB 的 L2 切片被分成两个 16 MB 的段。如果核心不需要其所有 L2 容量,则一个段可以成为虚拟 L3/L4 的一部分。如果核心空闲,则所有 32 MB 都可以用于虚拟 L3/L4。

IBM 的技术概述进一步阐明,虚拟 L4 是在整个抽屉中实现的。Z16 抽屉有八个 Telum 芯片,每个芯片具有 256 MB 的 L2 容量。在抽屉上运行的单线程工作负载获得其自己的 32 MB 的 L2。所有其他片上 L2 缓存都成为该线程的 224 MB L3,并且抽屉内的其他 L2 缓存合并以形成一个 1.75 GB 的虚拟 L4。
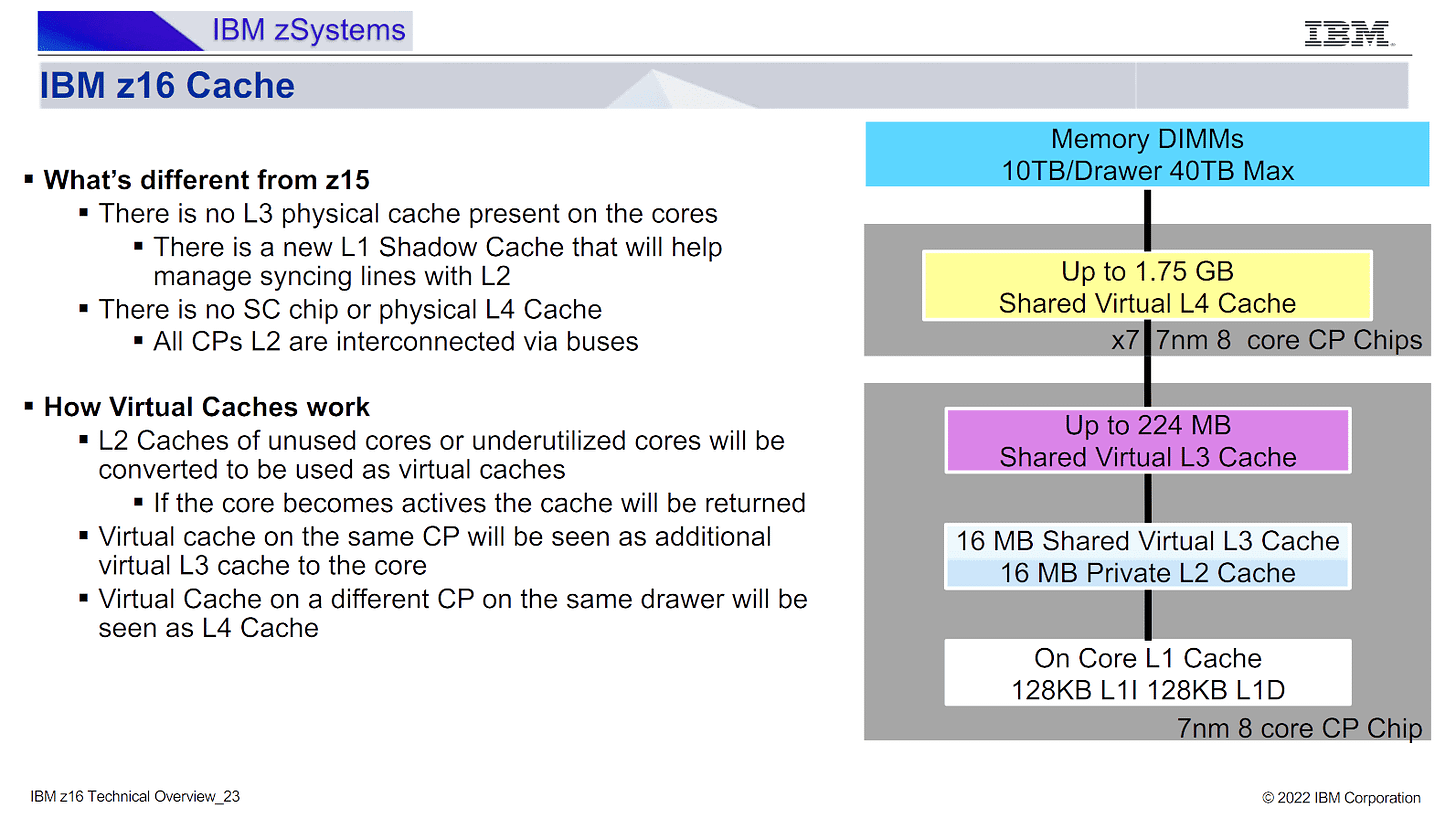
Telum II 进一步发展了该策略,在 L2、虚拟 L3 和虚拟 L4 方面具有更高的缓存容量。当我问 Cheese 在完成他的采访后 Telum II 如何处理其虚拟 L3 时,他们提到了同余类。我不知道什么是同余类。毕竟,IBM 使用了我不太熟悉的不同的术语,并且经过一番搜索才弄清楚同余类基本上是一个缓存集。

有趣的是,我问 IBM 为什么与行业其他公司相比有不同的术语。他们说 IBM 首先提出了这些术语,后来该行业采用了不同的术语。这都是轻松而有趣的。但这也提醒我们,IBM 是一家开发高性能 CPU 的先驱公司。
总结
CPU 设计人员必须在单线程和多线程性能之间取得平衡。服务器 CPU 倾向于专注于后者,而客户端设计则相反。Telum II 和之前的 IBM 大型主机芯片处理诸如金融交易之类的服务器任务,但奇怪的是,它们似乎优先考虑单线程性能。IBM 实际上已经将每个芯片的核心数从 Z15 中的 12 个减少到 Telum 和 Telum II 中的 8 个。对单线程性能的关注在 IBM 的缓存策略中也很明显。在 Telum II 上运行的单线程可以享受客户端类的 L2 和 L3 访问延迟,但在每个级别上的容量却要大一个数量级。
 来自
来自 IBM 网站的 Telum II 芯片的渲染图
我想知道 IBM 的策略是否适用于客户端设计。值得注意的是,AMD 的最高端 CPU 在芯片上具有大量的 L3 缓存容量。例如,Ryzen 9 9950X 每个 CCD 具有 32 MB 的 L3 和 8 MB 的 L2。两个 CCD 加在一起将提供 64 MB 的 L3 和 16 MB 的 L2,总共 80 MB 的缓存容量。如果所有这些都可以用于单个线程,那么它与 VCache 部件获得的 96 MB L3 缓存相差不远。一个假设的双 CCD 部件,两个模具上都有 VCache,可以具有超过 200 MB 的虚拟 L3 容量。
当然,实现这一点并非易事。IBM 的大型主机芯片使用非常快的跨芯片互连。Zen 5 CCD 的 Infinity Fabric 链接仅分别提供 64 GB/s 和 32 GB/s 的读取和写入带宽。IBM 的上一代 Telum 已经在双芯片模块之间具有两倍的带宽,甚至在位于同一模块上的 Telum 芯片之间具有更多的带宽。

也许 AMD 认为消费者不愿意为客户端 CPU 中的高级封装技术支付高价。但我确实想知道,如果 AMD 可以成为 GPU 市场的 Nvidia 会发生什么,在 GPU 市场中,发烧友不反对为高端 SKU 支付超过 2000 美元的价格。游戏往往对缓存敏感,正如 VCache 所显示的那样。也许具有 CoWoS-R RDL 中介层或类似封装技术和虚拟 L3 的部件可以进一步提高游戏性能。
我要感谢 IBM 在 Hot Chips 2024 上做出的精彩演讲,以及在场外对话中讨论他们架构的部分内容。