内存一致性模型:教程
James Bornholt
- GitHub
- Google Scholar
- DBLP
- Blog
- CV
 2016年2月17日
2016年2月17日
内存一致性模型:一个教程
当然,计算机科学中只有两件难事:缓存失效、命名以及差一错误。但还有另一个难题潜伏在计算机科学的茂盛杂草中:按顺序观察事物。 无论是排序、乱序还是发推,按顺序观察事物始终是一项挑战。
一个常见的排序挑战是内存一致性,它是定义并行线程如何观察其共享内存状态的问题。 关于内存一致性有很多资源,但大多数要么是幻灯片(比如我的!),要么是晦涩难懂的大部头。我的目标是编写一个入门指南,并说明为什么内存一致性是多核系统的问题。 对于详细信息,你当然应该查阅这些其他优秀的资源。
使线程达成一致
一致性模型处理的是多个线程(或工作程序、节点或副本等)如何看待世界。 考虑这个简单的程序,它运行两个线程,其中 A 和 B 最初都是 0:
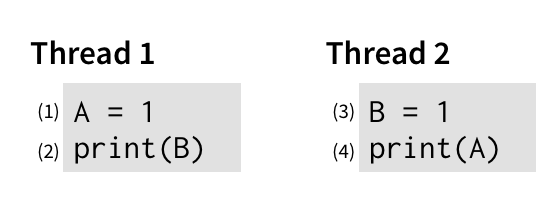
要理解这个程序可以输出什么,我们应该考虑它的事件可能发生的顺序。 直观地说,这个程序有两种明显的运行顺序:
- (1) → (2) → (3) → (4):第一个线程在第二个线程之前运行其所有事件,因此程序输出
01。 - (3) → (4) → (1) → (2):第二个线程在第一个线程之前运行其所有事件。 程序仍然输出
01。
还有一些不太明显的顺序,其中指令彼此交错:
- (1) → (3) → (2) → (4):每个线程中的第一条指令在任何线程中的第二条指令之前运行,输出
11。 - (1) → (3) → (4) → (2):运行来自第一个线程的第一条指令,然后运行来自第二个线程的两条指令,然后运行来自第一个线程的第二条指令。 程序仍然输出
11。 - 还有一些其他具有相同效果的指令。
不应该发生的事情
直观地说,这个程序不应该输出 00。 对于第 (2) 行输出 0,我们必须在第 (3) 行将 1 写入 B 之前输出 B。 我们可以用一条边以图形方式表示这一点:
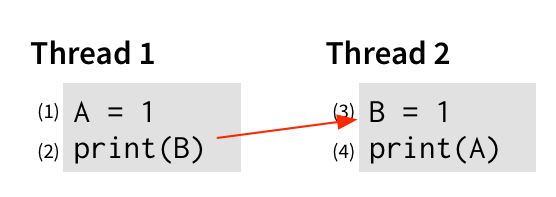
从操作 x 到操作 y 的边表示 x 必须先于 y 才能获得我们感兴趣的行为。 类似地,对于第 (4) 行输出 0,该输出必须在第 (1) 行将 1 写入 A 之前发生,因此让我们将其添加到图中:
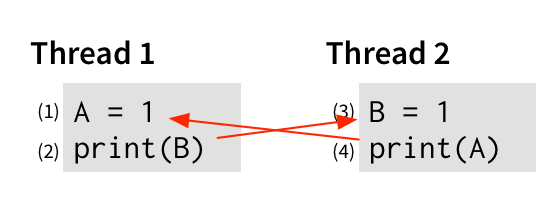
最后,当然,每个线程的事件应该按顺序发生——(1) 在 (2) 之前,(3) 在 (4) 之前——因为这是我们对命令式程序的期望。 所以让我们也添加这些边:
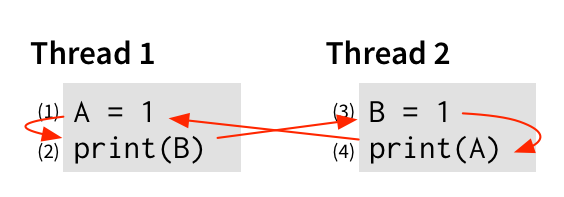
但现在我们遇到了问题。 如果我们从 (1) 开始,并沿着边——到 (2),然后到 (3),然后到 (4),然后……再次回到 (1)! 请记住,边表示哪些事件必须先于其他事件发生。 因此,如果我们从 (1) 开始,并最终回到 (1),则该图表示 (1) 必须先于自身发生! 如果没有物理学上非常令人担忧的进步,这不太可能实现。
由于此执行需要时间扭曲,因此我们可以得出结论,该程序无法输出 00。 可以将其视为反证法:假设该程序可以输出 00。 那么我们刚刚展示的所有排序规则都必须成立。 但是这些规则会导致矛盾(事件 (1) 在其自身之前发生)。 所以假设是错误的。
顺序一致性:一种直观的并行模型
架构师和编程语言设计者认为我们刚刚探索的规则对于程序员来说是直观的。 其思想是,并行运行的多个线程正在操作单个主内存,因此所有事情都必须按顺序发生。 没有两个事件可以“同时”发生的想法,因为它们都在访问单个主内存。
请注意,此规则没有说明事件发生的顺序——只是它们以某种顺序发生。 这种直观模型的另一部分是事件以程序顺序发生:单个线程中的事件以编写它们的顺序发生。 这就是程序员所期望的:如果我的程序允许在检查密钥是否已转动之前发射导弹,那么各种糟糕的事情就会开始发生。
这两个规则——单个主内存和程序顺序——共同定义了顺序一致性。定义顺序一致性是 Leslie Lamport 在 2013 年获得 图灵奖 的众多成就之一。1
顺序一致性是我们第一个内存一致性模型的示例。 内存一致性模型(我们通常只称其为“内存模型”)定义了多处理器上多个线程的允许排序。 例如,在上面的程序中,顺序一致性禁止任何导致输出 00 的排序,但允许一些输出 01 和 11 的排序。
内存一致性模型是硬件和软件之间的契约。 硬件承诺仅以模型允许的方式重新排序操作,作为回报,软件承认所有此类重新排序都是可能的,并且需要考虑它们。
顺序一致性的问题
一种思考顺序一致性的好方法是将其视为开关。 在每个时间步,开关选择一个线程来运行,并完全运行其下一个事件。 该模型保留了顺序一致性的规则:事件正在访问单个主内存,因此按顺序发生;并且通过始终运行来自所选线程的下一个事件,每个线程的事件都按程序顺序发生。
该模型的问题在于它极其、灾难性地慢。 我们一次只能运行一条指令,因此我们失去了并行运行多个线程的大部分好处。 更糟糕的是,我们必须等待每条指令完成才能开始下一条指令——在当前指令的效果对所有其他线程变为可见之前,无法运行更多指令。
一致性
有时,这种等待的要求是有道理的。 考虑两个线程都想要写入变量 A,而另一个线程想要读取变量 A 的情况:
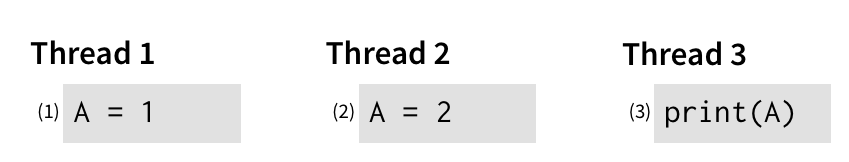
如果我们放弃单个主内存的想法,以允许 (1) 和 (2) 并行运行,那么突然不清楚事件 (3) 应该读取哪个 A 值。 单个主内存保证始终会有一个“赢家”:每个变量的单个最后一次写入。 如果没有此保证,在 (1) 和 (2) 都发生后,(3) 可以看到 1 或 2,这令人困惑。
我们将此保证称为一致性,它表示对同一位置的所有写入都由每个线程以相同的顺序看到。 它不规定实际顺序((1) 或 (2) 都可以先发生),但确实要求每个人都看到相同的“赢家”。
放松的内存模型
除了一致性之外,通常不需要单个主内存。 再次考虑以下示例:
没有理由执行事件 (2)(从 B 读取)需要等到事件 (1)(写入 A)完成。 它们根本不相互干扰,因此应该允许并行运行。 事件 (1) 特别慢,因为它是一个写入操作。 这意味着,使用单个内存视图,我们无法在 (1) 对所有其他线程变为可见之前运行 (2)。 在现代 CPU 上,由于缓存层次结构,这是一个非常昂贵的操作:
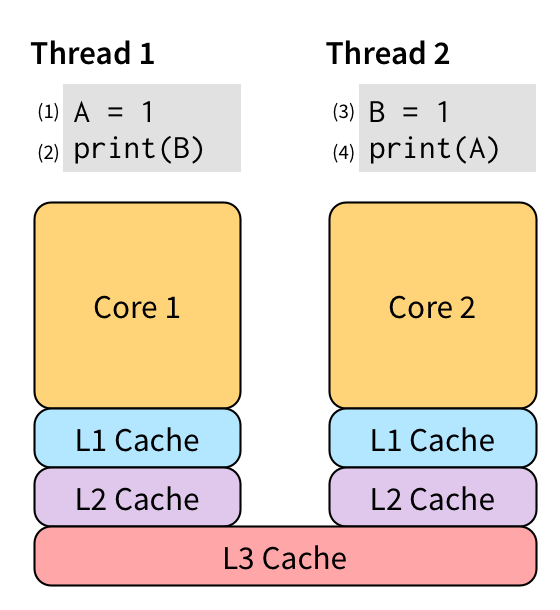
两个内核之间唯一的共享内存一直返回到 L3 缓存,通常需要 90 多个周期才能访问。
总存储顺序 (TSO)
我们可以不等待写入 (1) 变为可见,而是将其放入存储缓冲区中:
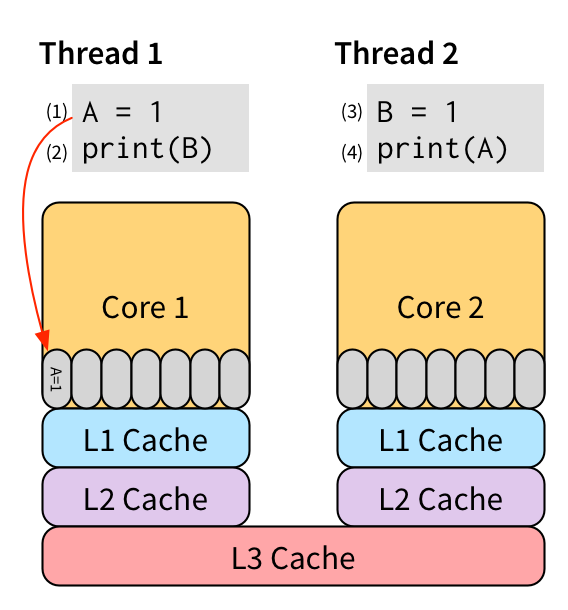
然后 (2) 可以在将 (1) 放入存储缓冲区后立即开始,而不是等待它到达 L3 缓存。 由于存储缓冲区位于核心上,因此访问速度非常快。 将来,缓存层次结构将从存储缓冲区中提取写入操作并将其传播到缓存中,以便对其他线程可见。 存储缓冲区允许我们隐藏通常需要使写入 (1) 对所有其他线程可见的写入延迟。
存储缓冲很好,因为它保留了单线程行为。 例如,考虑这个简单的单线程程序:
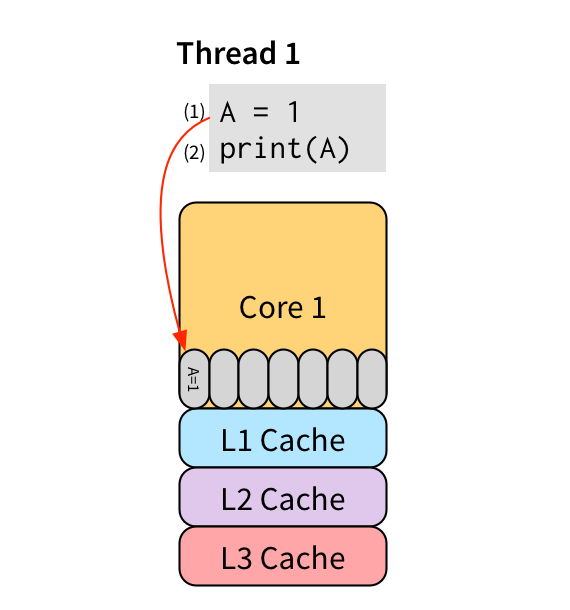
(2) 中的读取需要看到 (1) 写入的值,以便该程序保留预期的单线程行为。 写入 (1) 尚未进入内存——它位于核心 1 的存储缓冲区中——因此如果读取 (2) 只是查找内存,它将获得一个旧值。 但是,因为它在同一 CPU 上运行,所以读取可以直接检查存储缓冲区,查看其中包含对它正在读取的位置的写入,并改为使用该值。 因此,即使有存储缓冲区,该程序也可以正确输出 1。
允许存储缓冲的一种流行的内存模型称为总存储顺序 (TSO)。 TSO 大部分保留了与 SC 相同的保证,只是它允许使用存储缓冲区。 这些缓冲区隐藏了写入延迟,从而使执行速度显着加快。
注意事项
存储缓冲区听起来像是一个很棒的性能优化,但有一个注意事项:TSO 允许 SC 不允许的行为。 换句话说,在 TSO 硬件上运行的程序可能会表现出程序员会觉得令人惊讶的行为。
让我们看看上面相同的第一个示例,但这次在具有存储缓冲区的机器上运行。 首先,我们执行 (1) 然后执行 (3),它们都将其数据放入存储缓冲区而不是将其发送回主内存:
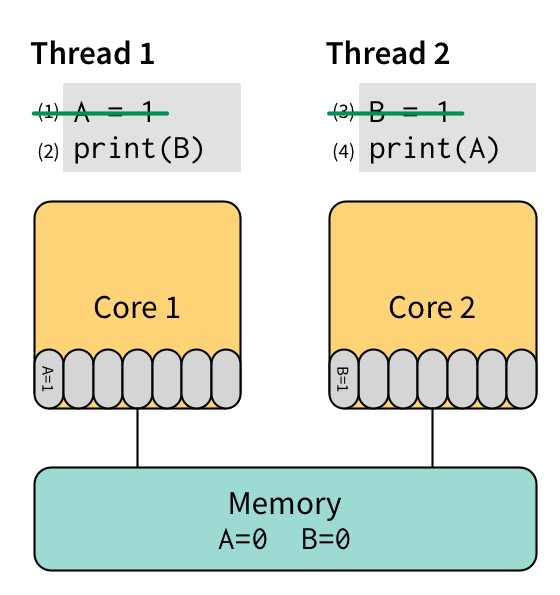
接下来,我们在核心 1 上执行 (2),它将读取 B 的值。 它首先检查其本地存储缓冲区,但那里没有 B 的值,因此它从内存中读取 B 并获取值 0,然后将其输出。 最后,我们在核心 2 上执行 (4),它将读取 A 的值。 核心 2 的存储缓冲区中没有 A 的值,因此它从内存中读取并获取值 0,然后将其输出。 在未来的某个不确定的时间点,缓存层次结构会清空两个存储缓冲区并将更改传播到内存。
因此,在 TSO 下,该程序可以输出 00。 这是我们上面展示的被 SC 明确排除的行为! 因此,存储缓冲区会导致程序员不期望的行为。
是否有任何架构愿意采用与程序员直觉背道而驰的优化? 是的! 事实证明,实际上每个现代架构都包含一个存储缓冲区,因此具有至少与 TSO 一样弱的内存模型。
特别是,历史悠久的 x86 架构指定了一个非常接近 TSO 的内存模型。 英特尔(x86 的发起者)和 AMD(x86-64 的发起者)都使用示例短小测试指定其内存模型,类似于上面的程序,这些测试描述了小型测试的可观察结果。 不幸的是,使用少量示例指定复杂系统的行为会留下歧义空间。 剑桥的研究人员投入了大量精力形式化 x86-TSO,以明确 x86 的 TSO 实现的预期行为(特别是,它与存储缓冲的概念的不同之处)。
变得更弱
即使 x86 放弃了顺序一致性,它在允许的疯狂行为方面也是行为最好的架构之一。 大多数其他架构实现更弱的内存模型,这意味着它们允许更多非直观的行为。 存在此类模型的完整范围——SPARC 架构允许程序员在运行时在三种不同的模型之间选择。
一个值得指出的架构是 ARM,它除其他外,可能为你的智能手机提供动力。 ARM 内存模型以不充分指定而闻名,但本质上是弱排序的一种形式,它提供的保证很少。 弱排序允许几乎任何操作重新排序,这支持各种硬件优化,但也是在最低级别进行编程的噩梦。
通过屏障逃脱
幸运的是,所有现代架构都包含同步操作,以便在必要时控制其宽松的内存模型。 最常见的此类操作是屏障(或栅栏)。 屏障指令强制其之前的所有内存操作在开始其之后的任何内存操作之前完成。 也就是说,屏障指令有效地在程序执行的特定点恢复顺序一致性。
当然,这正是我们试图通过引入存储缓冲区和其他优化来避免的行为。 屏障是一种谨慎使用的逃生舱:它们可能会花费数百个周期。 正确使用它们也非常微妙,尤其是在与模糊的内存模型定义结合使用时。 还有一些更可用的原语,例如原子比较和交换,但应真正避免直接使用低级同步。 真正的同步库将为你节省无数的痛苦。
语言也需要内存模型
不仅硬件会重新排序内存操作——编译器也会一直这样做。 考虑以下程序:
X = 0
for i in range(100):
X = 1
print X
此程序始终输出 100 个 1 的字符串。 当然,循环内的写入 X 是多余的,因为没有其他代码会更改 X 的值。 标准的 循环不变代码移动 编译器传递会将写入移动到循环外以避免重复,并且 死存储消除 然后将删除 X = 0,留下:
X = 1
for i in range(100):
print X
这两个程序完全等效,因为它们都将产生相同的输出。2
但是现在假设还有另一个线程与我们的程序并行运行,并且它对 X 执行一次写入:
X = 0
通过并行运行这两个线程,第一个程序的行为会发生变化:现在,它可以输出像 11101111... 这样的字符串,只要只有一个零(因为它会在下一次迭代时重置 X=1)。 第二个程序的行为也会发生变化:它现在可以输出像 11100000... 这样的字符串,一旦它开始输出零,它就永远不会回到一。
但是这两个改变的行为对于两个程序来说并不常见:第一个程序永远无法输出 11100000...,第二个程序也永远无法输出 11101111...。 这意味着在存在并行性的情况下,编译器优化不再产生等效的程序!
这个示例表明,在程序级别也有内存一致性的概念。 此处的编译器优化实际上是一种重新排序:它正在重新排列(并删除一些)内存访问,程序员可能会或可能看不到这些内存访问。 因此,为了保留直观的行为,编程语言需要自己的内存模型,以便向程序员提供有关如何重新排序其内存操作的合同。 这种想法在语言设计界越来越普遍。 例如,最新版本的 C++ 和 Java 具有严格定义的内存模型来管理其操作。
计算机坏了!
所有这些重新排序似乎都疯狂了,没有人能够一直保持清晰。 另一方面,如果你反思你的编程经验,内存一致性可能不是你经常遇到的问题,如果不是根本没有遇到(除非你是低级内核黑客)。 我如何调和这两个极端?
诀窍在于我在这里提到的每个示例都涉及数据竞争。 数据竞争是指对同一内存位置的两次访问,其中至少一个是写入操作,并且没有同步引起的排序。 如果没有数据竞争,那么重新排序行为就无关紧要,因为所有非直观的重新排序都会被同步阻止。 请注意,这并不意味着无竞争程序是确定性的:不同的线程可以在每次执行时赢得竞争。
事实上,C++ 和 Java 等语言提供了一种称为无数据竞争程序的顺序一致性(或流行语版本“SC for DRF”)的保证。 此保证表示,如果你的程序没有数据竞争,编译器将插入所有必要的栅栏以保留顺序一致性的外观。 但是,如果你的程序确实有数据竞争,那么一切都无效,编译器可以自由地做任何它喜欢的事情。 直觉是,具有数据竞争的程序很可能存在错误,并且没有必要为此类存在错误的程序提供强大的保证。 如果一个程序有故意的数据竞争,程序员可能知道他们在做什么,因此可以自己负责内存排序问题。
使用同步库
现在你已经看到了所有这些混乱,最重要的经验是你应该使用同步库。 它会为你处理丑陋的重新排序问题。 操作系统也经过大量优化,只在特定平台上进行必要的同步。 但是现在你已经知道了当这些库和内核处理微妙的同步问题时,幕后会发生什么。
如果出于某种原因,你想更多地了解计算机架构对世界造成的各种令人憎恶的内存模型,那么 Morgan & Claypool 关于计算机架构的综合讲座中有一个关于内存一致性和一致性的不错的条目。
1
虽然 Lamport 最初是关于多处理器的,但他后来的工作转向了分布式系统。 在现代分布式系统上下文中,“顺序一致性”的含义与架构师的意图略有不同(并且更弱)。 架构师所说的“顺序一致性”更像是分布式系统人员所说的“线性化”。
2
让我们暂时停止怀疑,并假设编译器不够聪明,无法将此程序优化为对 print 的单个调用。