从零开始构建一个简单的搜索引擎:基于 Word2vec 的实践
home blog microblog favorites pl resources bread recipes rss
从零开始构建一个简单的搜索引擎*
2025年5月20日 与 Chris Gregory 共同创作! *如果你包括了 word2vec 的话。 几天前,Chris 和我花了几个小时,从“零”开始为我的博客创建了一个搜索引擎。主要是他引导我完成的,因为在这个实验之前,我对 word2vec 的了解还很模糊。
我们构建的搜索引擎基于 word embeddings(词嵌入)。它指的是某种函数,它接受一个词,并将其映射到 N 维空间(在本例中,N=300),其中每个维度模糊地对应于某种意义轴。Word2vec from Scratch 是一篇不错的博客文章,展示了如何训练你自己的迷你 word2vec 并解释其内部原理。
搜索引擎背后的想法是将我的每篇文章都嵌入到这个空间中,方法是将文章中单词的 embeddings 相加。对于给定的搜索,我们将以相同的方式嵌入搜索词。然后,我们可以根据所有文章与查询的 cosine similarities (余弦相似度) 对它们进行排序。
下面的公式看起来可能很吓人,但它是在说余弦相似度,即两个向量 cos(theta) 之间的角度的余弦,定义为点积除以每个向量的幅度的乘积。我们将详细介绍所有这些。
 来自 Wikimedia 的 Cosine similarity 页面中的公式。
来自 Wikimedia 的 Cosine similarity 页面中的公式。
余弦距离可能是比较查询 embedding 和文档 embeddings 以对文档进行排序的最简单方法。另一种直观的选择可能是欧几里得距离,它会测量两个向量在空间中的距离(而不是它们之间的角度)。
我们更喜欢余弦距离,因为它保留了我们的直觉,即如果两个向量具有相同比例的每个 embedding 维度,则它们具有相似的含义。如果你有两个指向相同方向的向量,但一个非常长,一个非常短,则应将它们视为具有相同的含义。(如果两个文档都关于猫,但一个文档中“cat”这个词出现的频率更高,那么它们仍然都只是关于猫的)。
让我们打开 word2vec 并嵌入我们的第一个单词。
Embedding
我们理所当然地使用了这个包含前 10,000 个最流行的词 embeddings 的数据库,它是一个 12MB 的 pickle 文件,大致如下所示:
couch [0.23, 0.05, ..., 0.10]
banana [0.01, 0.80, ..., 0.20]
...
Chris 通过互联网发给了我。如果你 unpickle 它,它实际上是一个 NumPy 数据结构:一个将字符串映射到 numpy.float32 数组的字典。我编写了一个脚本,将这个 pickle 文件转换为普通的 Python floats 和 lists,因为我想手动完成所有这些操作。
加载代码很简单:使用 pickle 库。通常的安全注意事项适用,但我信任 Chris。
import pickle
def load_data(path):
with open(path, "rb") as f:
return pickle.load(f)
word2vec = load_data("word2vec.pkl")
你可以打印出 word2vec,但会产生大量的输出。我从惨痛的经历中学到了这一点。也许可以打印 word2vec["cat"]。这将打印出 embedding。
要嵌入一个单词,我们只需要在庞大的字典中查找它。但是,一个无意义或不常见的单词可能不在其中,因此我们返回 None,而不是引发错误。
def embed_word(word2vec, word):
return word2vec.get(word)
要嵌入多个单词,我们分别嵌入每个单词,然后成对地将 embeddings 相加。如果给定的单词无法嵌入,则忽略它。只有当我们无法理解任何单词时,才会出现问题。
def vec_add(a, b):
return [x + y for x, y in zip(a, b)]
def embed_words(word2vec, words):
result = [0.0] * len(next(iter(word2vec.values())))
num_known = 0
for word in words:
embedding = word2vec.get(word)
if embedding is not None:
result = vec_add(result, embedding)
num_known += 1
if not num_known:
raise SyntaxError(f"I can't understand any of {words}")
return result
这就是 embeddings 的基础知识:它是一个字典查找和向量加法。
embed_words([a, b]) == vec_add(embed_word(a), embed_word(b))
现在让我们制作我们的“搜索引擎索引”,或者说是我所有帖子的 embeddings。
嵌入所有帖子
嵌入所有帖子是一个递归的目录遍历,我们在其中构建一个将路径名映射到 embedding 的字典。
import os
def load_post(pathname):
with open(pathname, "r") as f:
contents = f.read()
return normalize_text(contents).split()
def load_posts():
# Walk _posts looking for *.md files
posts = {}
for root, dirs, files in os.walk("_posts"):
for file in files:
if file.endswith(".md"):
pathname = os.path.join(root, file)
posts[pathname] = load_post(pathname)
return posts
post_embeddings = {pathname: embed_words(word2vec, words)
for pathname, words in posts.items()}
with open("post_embeddings.pkl", "wb") as f:
pickle.dump(post_embeddings, f)
我们还做了另一件事:normalize_text。这是因为博客文章很混乱,包含标点符号、大写字母和各种其他无意义的东西。为了获得最佳匹配,我们希望将诸如“CoMpIlEr”和“compiler”之类的内容放在同一个 bucket 中。
import re
def normalize_text(text):
return re.sub(r"[^a-zA-Z]", r" ", text).lower()
我们也将对每个查询执行相同的操作。说到这,我们应该测试一下。让我们做一个小的搜索 REPL。
一个小的搜索 REPL
我们将从使用 Python 的内置 REPL 创建库 code 开始。我们可以创建一个定义 runsource 方法的子类。它真正需要做的就是处理 source 输入并返回一个 falsy 值(否则它会等待更多输入)。
import code
class SearchRepl(code.InteractiveConsole):
def __init__(self, word2vec, post_embeddings):
super().__init__()
self.word2vec = word2vec
self.post_embeddings = post_embeddings
def runsource(self, source, filename="<input>", symbol="single"):
for result in self.search(source):
print(result)
然后我们可以定义一个 search 函数,它将我们现有的函数组合在一起。就这样,我们有了一个搜索功能:
class SearchRepl(code.InteractiveConsole):
# ...
def search(self, query_text, n=5):
# Embed query
words = normalize_text(query_text).split()
try:
query_embedding = embed_words(self.word2vec, words)
except SyntaxError as e:
print(e)
return
# Cosine similarity
post_ranks = {pathname: vec_cosine_similarity(query_embedding,
embedding) for pathname,
embedding in self.post_embeddings.items()}
posts_by_rank = sorted(post_ranks.items(),
reverse=True,
key=lambda entry: entry[1])
top_n_posts_by_rank = posts_by_rank[:n]
return [path for path, _ in top_n_posts_by_rank]
是的,我们必须进行余弦相似度计算。值得庆幸的是,维基百科上的数学片段几乎可以 1:1 地翻译成 Python 代码:
import math
def vec_norm(v):
return math.sqrt(sum([x*x for x in v]))
def vec_cosine_similarity(a, b):
assert len(a) == len(b)
a_norm = vec_norm(a)
b_norm = vec_norm(b)
dot_product = sum([ax*bx for ax, bx in zip(a, b)])
return dot_product/(a_norm*b_norm)
最后,我们可以创建并运行 REPL。
sys.ps1 = "QUERY. "
sys.ps2 = "...... "
repl = SearchRepl(word2vec, post_embeddings)
repl.interact(banner="", exitmsg="")
这就是与之交互的样子:
QUERY.type inference
_posts/2024-10-15-type-inference.md
_posts/2025-03-10-lattice-bitset.md
_posts/2025-02-24-sctp.md
_posts/2022-11-07-inline-caches-in-skybison.md
_posts/2021-01-14-inline-caching.md
QUERY.
这是来自一个非常小的数据集(我的博客)的示例查询。这是一个非常好的搜索结果,但它可能不能代表整体搜索质量。Chris 说我应该挑挑拣拣,“因为人工智能领域的每个人都这样做”。
好的,这真的很简洁。但是,大多数想在我的网站上查找内容的人都不会运行他们的终端。虽然我的网站明确设计为可以在诸如 Lynx 之类的终端浏览器中良好运行,但大多数人已经在图形 Web 浏览器中。因此,让我们制作一个搜索前端。
一个小的 Web 搜索
到目前为止,我们一直在我的本地机器上运行,在那里我不介意有一个 12MB 的权重文件。既然我们要迁移到 Web,我宁愿不让休闲浏览者承担意外的大型下载负担。因此,我们需要变得聪明。
幸运的是,Chris 和我都看到了这篇非常酷的博客文章,它讨论了在 GitHub Pages 上托管 SQLite 数据库。该博客文章详细介绍了作者如何:
- 将 SQLite 编译为 Wasm,以便它可以在客户端上运行,
- 构建一个虚拟文件系统,以便它可以从 Web 读取数据库文件,
- 使用现有的 SQLite 索引进行一些智能页面提取,
- 构建额外的软件,以使用 HTTP Range 请求仅提取数据库的小块
这非常酷,但再次:SQLite 虽然小,但对于此项目来说相对较大。我们想从头开始构建东西。幸运的是,我们可以模仿主要的想法。
我们可以给 word2vec 字典一个稳定的顺序,并将其拆分为两个文件。一个文件可以只包含 embeddings,没有名称。另一个文件,即索引,可以将每个单词映射到该单词的权重的字节开始和字节长度(我们认为 start&length 可能比 start&end 在线上传输更小)。
#vecs.jsonl[0.23,0.05,...,0.10][0.01,0.80,...,0.20]...
#index.json{"couch":[0,20],"banana":[20,30],...}
这样做的好处是 index.json 比 word2vec blob 小得多,只有 244KB。既然它不会经常更改(word2vec 多久更改一次?),我不会对用户急切地下载整个索引感到难过。同样,post_embeddings.json 只有 388KB。它们甚至可以缓存。并且由服务器和浏览器自动(解)压缩(分别为 84KB 和 140KB)。如果我们选择二进制格式,两者都会更小,但出于本文的目的,我们将推迟这样做。
然后,我们可以向服务器发出 HTTP Range 请求,并且只下载我们需要的权重部分。甚至可以将所有范围捆绑到一个请求中(称为多部分范围)。不幸的是,GitHub Pages 似乎不支持多部分,因此我们改为在单独的请求中下载每个单词的范围。
这是相关的 JS 代码,省略了(简短、非常熟悉的)向量函数:
(async function() {
// Download stuff
async function get_index() {
const req = await fetch("index.json");
return req.json();
}
async function get_post_embeddings() {
const req = await fetch("post_embeddings.json");
return req.json();
}
const index = new Map(Object.entries(await get_index()));
const post_embeddings = new Map(Object.entries(await get_post_embeddings()));
// Add search handler
search.addEventListener("input", debounce(async function(value) {
const query = search.value;
// TODO(max): Normalize query
const words = query.split(/\s+/);
if (words.length === 0) {
// No words
return;
}
const requests = words.reduce((acc, word) => {
const entry = index.get(word);
if (entry === undefined) {
// Word is not valid; skip it
return acc;
}
const [start, length] = entry;
const end = start+length-1;
acc.push(fetch("vecs.jsonl", {
headers: new Headers({
"Range": `bytes=${start}-${end}`,
}),
}));
return acc;
}, []);
if (requests.length === 0) {
// None are valid words :(
search_results.innerHTML = "No results :(";
return;
}
const responses = await Promise.all(requests);
const embeddings = await Promise.all(responses.map(r => r.json()));
const query_embedding = embeddings.reduce((acc, e) => vec_add(acc, e));
const post_ranks = {};
for (const [path, embedding] of post_embeddings) {
post_ranks[path] = vec_cosine_similarity(embedding, query_embedding);
}
const sorted_ranks = Object.entries(post_ranks).sort(function(a, b) {
// Decreasing
return b[1]-a[1];
});
// Fun fact: HTML elements with an `id` attribute are accessible as JS
// globals by that same name.
search_results.innerHTML = "";
for (let i = 0; i < 5; i++) {
search_results.innerHTML += `<li>${sorted_ranks[i][0]}</li>`;
}
}));
})();
你可以看看实际的 搜索页面。特别是,打开浏览器控制台的网络请求选项卡。惊叹于它只下载几个 4KB 的 embeddings 块。
那么我们的搜索技术效果如何?让我们尝试构建一个客观的评估。
评估
我们将设计一个指标,粗略地告诉我们何时我们的搜索引擎比没有词 embeddings 的幼稚方法更好或更差。
我们首先收集一个 (document, query) 对的评估数据集。从一开始,我们将通过自己收集此数据集来偏向此评估,但希望它仍然可以帮助我们了解搜索的质量。在这种情况下,查询只是我们认为应该成功检索文档的几个搜索词。
sample_documents = {
"_posts/2024-10-27-on-the-universal-relation.md": "database relation universal tuple function",
"_posts/2024-08-25-precedence-printing.md": "operator precedence pretty print parenthesis",
"_posts/2019-03-11-understanding-the-100-prisoners-problem.md": "probability strategy game visualization simulation",
# ...
}
现在我们已经收集了我们的数据集,让我们实现一个 top-k 准确性指标。此指标衡量给定其对应查询,文档出现在前 k 个搜索结果中的百分比。
def compute_top_k_accuracy(
# Mapping of post to sample search query (already normalized)
# See sample_documents above
eval_set: dict[str, str],
max_n_keywords: int,
max_top_k: int,
n_query_samples: int,
) -> list[list[float]]:
counts = [[0] * max_top_k for _ in range(max_n_keywords)]
for n_keywords in range(1, max_n_keywords + 1):
for post_id, keywords_str in eval_set.items():
for _ in range(n_query_samples):
# Construct a search query by sampling keywords
keywords = keywords_str.split(" ")
sampled_keywords = random.choices(keywords, k=n_keywords)
query = " ".join(sampled_keywords)
# Determine the rank of the target post in the search results
ids = search(query, n=max_top_k)
rank = safe_index(ids, post_id)
# Increment the count of the rank
if rank is not None and rank < max_top_k:
counts[n_keywords - 1][rank] += 1
accuracies = [[0.0] * max_top_k for _ in range(max_n_keywords)]
for i in range(max_n_keywords):
for j in range(max_top_k):
# Divide by the number of samples to get the average across samples and
# divide by the size of the eval set to get accuracy over all posts.
accuracies[i][j] = counts[i][j] / n_query_samples / len(eval_set)
# Accumulate accuracies because if a post is retrieved at rank i,
# it was also successfully retrieved at all ranks j > i.
if j > 0:
accuracies[i][j] += accuracies[i][j - 1]
return accuracies
让我们首先评估一个基线搜索引擎。此实现根本不使用词 embeddings。我们只是规范化文本,并计算每个查询词在文档中出现的次数,然后按查询词出现次数对文档进行排序。绘制各种 k 值的 top-k 准确率会给出以下图表。请注意,当我们增加 k 时,我们会获得更高的准确率 - 在极限情况下,当 k 接近我们的文档数量时,我们接近 100% 的准确率。
您可能还会注意到,随着我们增加关键字的数量,准确率也会提高。我们还可以看到,随着关键字数量的增加,线条越来越接近,这表明每个新关键字的边际收益递减。
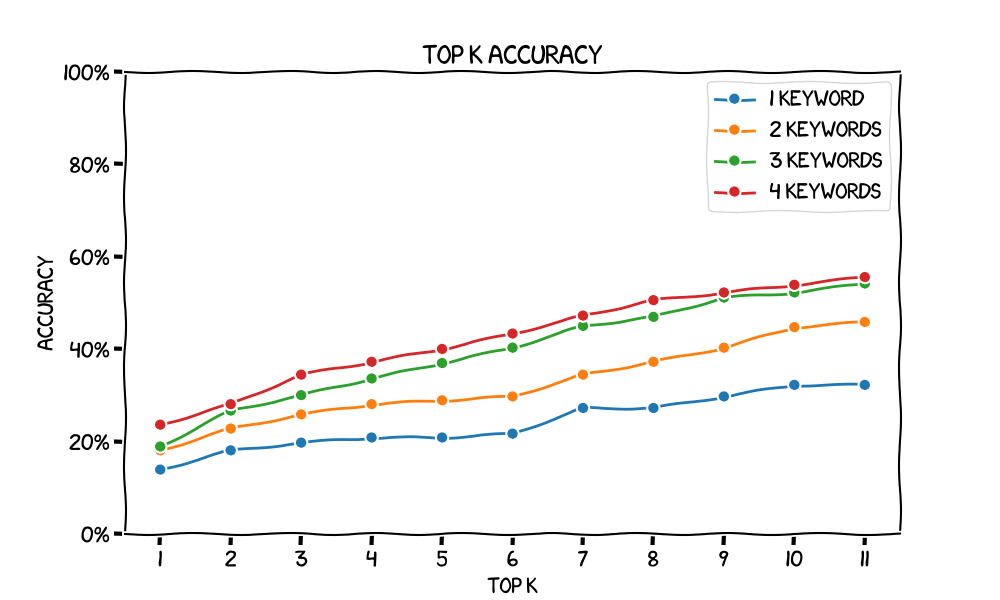
这些兆字节的词 embeddings 实际上是否可以提高我们的搜索效果?我们必须与基线进行比较。也许该基线是将每个文档中所有关键字的计数相加来对其进行排序。我们将其作为读者的练习,因为我们的时间已经不多了:)
看看更大的 word2vec 如何帮助提高准确性也会很有趣。在为 top-k 采样时,会产生很多错误输出(I can't understand any of ['prank', ...])。这些未知的单词将从搜索中删除。更大的 word2vec(超过 10,000 个单词)可能包含这些不太常见的单词,因此搜索效果更好。
总结
您只需一百行左右的代码就可以从“头”构建一个小型搜索引擎。请参阅完整的 search.py,其中包括用于评估和绘图的一些额外功能。
未来的想法
我们可以比简单的余弦相似度更花哨。让我们想象一下,我们所有的文档都讨论计算机,但只有一个文档讨论编译器(那会很悲伤)。如果我们的搜索词之一是“计算机”,那么它实际上无助于缩小搜索范围,并且是我们的 embeddings 中的噪声。为了减少噪声,我们可以采用一种称为 TF-IDF(词频逆文档频率)的技术,我们在其中分解跨文档的常见词,并更多地关注每个文档特有的词。

