如果 AI Agent 都搞不定你的 API,用户也一样
如果 AI Agent 都搞不定你的 API,用户也一样
Auth & identity
2025年5月19日
作者: Reed McGinley-Stempel

基于 LLM 的 agent 正变得越来越像 不知疲倦的初级开发者。 只要给他们一个 API 以及文档,他们就会勤奋地阅读参考手册,发送请求,解析错误,调整参数,并一遍又一遍地尝试——循环往复——直到成功为止。
像 LangChain 和 OpenAI function-calling helpers,以及诸如 Cursor, Claude Code, OpenAI Codex, 和 Codename Goose 之类的 agent,使得这种循环更容易连接和遵循。
但是,agent 原始的坚持往往是不够的。 一旦你的 API 的开发者体验出现问题—— 一个过时的例子,一个模糊的 400 payload,一个无法找到的必填字段 ——agent 就会停滞不前。 这种停滞具有诊断意义。 如果一个拥有完美耐心和零自负的算法都无法解决问题,那么 一个需要在截止日期前完成任务的人类开发者几乎肯定会遇到同样的障碍。
这种对称性可以成为一个强大的杠杆。 修复那些让 agent 绊倒的摩擦点,你就可以为每个用户(无论基于硅还是基于碳)扫清道路,让他们在使用你的 API 时获得绝佳的体验。
快速浏览:AI Agent 如何使用 API
大多数 agent 框架都遵循一个 ReAct cycle,该循环交织着推理和行动,所有这些都旨在模仿人类解决问题的过程。
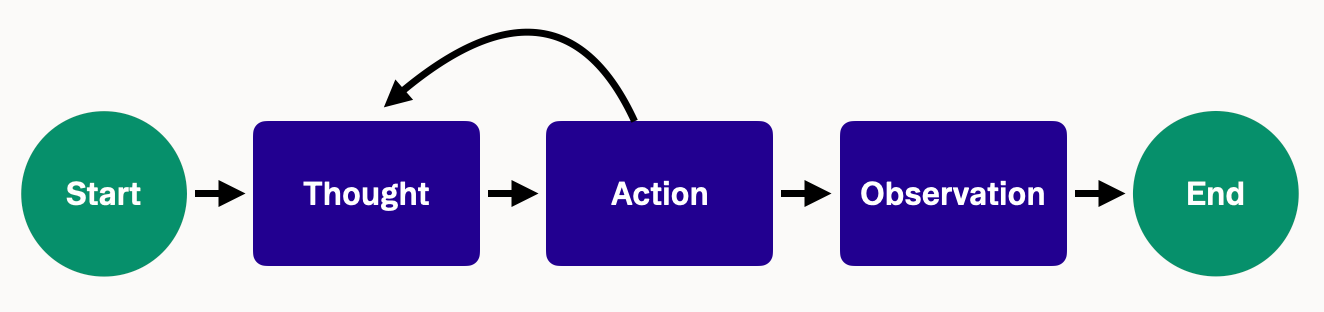
给 agent 一个任务(例如“列出未处理的 PR”)和一组工具(例如 GitHub 的 /pulls endpoint 加上 API 文档),它将像人类一样迭代。 它将查阅参考手册,触发 HTTP 调用,检查 JSON 或错误,调整其方法,并循环直到获得 2xx 响应。
让我们来看一个简单的例子:
- 思考 (Thought) : “我需要通过这个 API 创建一个新用户。 让我想想… 文档显示一个 endpoint
POST /users。” - 行动 (Action) : 使用它认为需要的数据调用
POST /users(假设它提供了一个包含电子邮件和密码的 JSON)。 - 观察 (Observation) : API 返回 400 Bad Request。(糟糕,出问题了。)
- 思考 (Thought) : “错误仅仅是 ‘Bad Request’,没有详细信息。 我不确定缺少什么。 也许我忘记了一个字段? 文档没有明确说明必填字段。 让我猜一下并添加一个
name字段。” - 行动 (Action) : 使用电子邮件、密码和姓名调用
POST /users。 - 观察 (Observation) : 这次它返回 201 Created – 成功!
在这种情况下,agent 在一次盲目重试后幸运地成功了,但它是在黑暗中工作的,因为错误没有提供任何信息,并且文档从未提到必填的 name 字段。 人类开发者也会遇到同样的障碍——只是会更加沮丧并且迭代周期更慢。
当确实存在线索时,agent 会急切地跟随。 它们解析代码示例,跟踪嵌入的链接,甚至可以直接加载文档——只要它通过标准化的接口(例如 llms.txt 文件)集成即可。 诸如 LangChain 的 mcpdoc 或 Mintlify 之类的框架和工具通过自动生成 agent 可以解析的结构化文档来促进这一点。 Agent 还可以将来自错误 payload 的提示直接合并到推理步骤中。 如果没有这些明确的信号,agent 会很快耗尽选项。
因此,LLM agent 的成功率可以直接反映你的文档和错误设计的清晰度。 如果 agent 无法弄清楚你的 API,那么很可能人类开发者也卡在了同一个断点上。
糟糕的 API UX 如何让所有人受挫
那些令人类开发者感到沮丧的可用性缺陷——分散的文档、神秘的错误、古怪的命名——会让 LLM 进入尾旋。
从文档开始
这应该不足为奇。 如果关键细节分散在营销页面、过时的论坛帖子和一个 3 年前的 PDF 中,agent 不会神奇地将它们拼接在一起。 它只能看到你提供的内容。 存在于隐藏的变更日志或评论线程中的必需参数,从模型的角度来看根本不存在。 人类也会感受到同样的痛苦,只是速度较慢。
显示清晰、详细的错误 Payload
LLM 会完全按照你的 API 返回的内容进行处理。 如果只提供一个裸 HTTP 状态和通用代码,就会迫使 agent 进行猜测,从而可能触发无休止的重试循环。
例如,一个集成 agent 的团队发现,没有正文文本的 422 响应会导致永久重试。 通过明确显示错误消息“缺少必填字段 'first_name'”,他们立即让 agent 能够自我纠正并取得成功。
另一方面,像“400 Bad Request”这样含糊不清的消息不会为 agent 或人类提供可操作的指导。 清晰、描述性的错误——例如“expiry_date 必须采用 YYYY-MM-DD 格式”——允许 agent 立即解析提示,重新生成其调用,并在不受干扰的情况下继续前进。 如果没有这些信息丰富的线索,进度就会停止。
解决一致性差距
LLM 是世界一流的模式检测器。 它们会在几次尝试中学习你的 casing、pluralization 和 resource hierarchy。 只要偏离一次——这里是 user_id,那里是 userId——模型可能会将第二个字段视为不相关的数据。 人类可能会在心里咒骂一声然后继续前进; agent 会悄悄地破坏其 prompt chain 或错误地路由数据……然后陷入混乱。
两个小故事
为了说明好的与坏的 API UX 之间的影响,我们可以比较 agent 与一个假设的 API 交互的两种场景。
1:在黑暗中猜测
思考 (Thought): 需要创建一个订单。 文档显示了 curl 示例; 让我们试试。
行动 (Action): POST /orders {"item": "Book"}
观察 (Obs): 400 Bad Request
思考 (Thought): 没有提供详细信息。 也许需要数量?
行动 (Action): POST /orders {"item": "Book", "quantity": 1}
观察 (Obs): 400 Bad Request
思考 (Thought): 仍然失败。 endpoint 错了吗? 缺少另一个必填字段? 我被困住了
agent 蔓延,尝试随机调整——这正是匆忙的开发者在复制粘贴了一个损坏的示例后会做的事情。
场景 2:在失败中走向成功
思考 (Thought): 目标是 `POST /orders`。 文档说 `item_id` 和 `customer_id` 是必需的。
行动 (Action): POST /orders {"item_id": "12345"}
观察 (Obs): 400 Bad Request – 缺少必填字段 "customer_id"
思考 (Thought): 对,添加它。
行动 (Action): POST /orders {"item_id": "12345", "customer_id": "999"}
观察 (Obs): 201 Created {"order_id": "ABC123", ...}
一条清晰的错误消息将死胡同变成了一次迭代。 成功所需时间(几秒钟与几分钟)的差异直接来自更清晰的文档和更丰富的上下文错误。 修复文档,收紧 schema,并编写明确的错误不是 AI polish; 这是基本的 DX 卫生习惯,你再也不能忽视它。
Agent 突显了人类所面临的困难
当 agent 绊倒时,它不会隐藏证据。 它会转储在下降过程中看到的每个考虑因素、工具调用和错误的日志。 审查该日志就像重播一个新开发者的第一次会话——你可以准确地找出路径在哪里消失,而不是猜测。
因为 agent 仅依赖于你公开的内容——文档、示例、错误等——它提供了 无噪音的反馈。 人可能会即兴创作或在 Google 上搜索; agent 无法做到。 如果它停滞不前,那么你的 onboarding 材料就不足。 这就是为什么团队现在谈论 Agent Experience (AX) 作为下一个 DX 前沿:基础知识——清晰的参考、可靠的示例、一致的模式——保持不变,但 LLM 会无情地暴露和记录任何差距。
可以将其视为前端测试。 就像 Selenium 脚本单击你的 UI 以捕获回归一样,LLM agent 依次“单击”你的 API。 如果该自动化的“Hello World”在 CI 中中断,请将其视为失败的测试用例——你已经在实际用户遇到之前捕获了一个损坏的 onboarding 路径。
Agent 作为实用的 DX 冒烟测试
当你在 API 上进行迭代时,很容易让小的更改溜走并破坏关键的首次使用路径。 与其等待支持票证或论坛帖子,不如招募 AI agent 来充当夜间冒烟测试员。 通过自动化你的“hello-world”流程——比如 创建用户 → 登录 ——你可以在客户遇到问题之前立即了解回归情况。

- 选择一个关键流程。 定义你的黄金路径,例如创建帐户和进行身份验证。
- 精心制作一个紧凑的 prompt。 仅提供足够的文档,以便 agent 知道要调用哪些 endpoint 以及按什么顺序调用。
- 在 CI 内部运行。 使用确定性设置(例如,temperature=0,最多 3 次重试)在每个 pull request 上执行 agent。
- 记录和跟踪。 在你的 CI 日志或评估仪表板中显示三个关键指标——通过/失败、重试计数和首次成功的时间。
一个小型的金融科技团队运行了这个过程,并在预发布冒烟测试期间捕获了一个缺失的 email_verified 标志,从而在任何客户注意到之前修复了该问题。
要在你的堆栈中实现这一点,请考虑:
工具选择
|
原因
---|---
本地健全性检查 (Local sanity check)
| OpenAI Python SDK| 快速的、临时的验证
CI-gated 流程 (CI‑gated flow)
| LangChain agent + PyTest| 捕获完整 trace 并断言通过
趋势仪表板 (Trend dashboard)
| LangSmith 或 OpenAI Evals| 可视化通过/失败和重试趋势
你可以在每个 PR 上运行一个黄金路径测试,并安排更广泛的 agent 套件每晚针对 staging sandbox 运行(或重置 fixtures 以避免状态泄漏)。 这种类型的循环可以使你的核心 onboarding 保持绿色,并使你确信任何集成都将保持稳固。
构建对 agent 和 用户友好的 API
为 AI agent 改进 API 的开发者体验,并不需要与为人类改进 API 的开发者体验完全不同的策略。 事实上,需求几乎 100% 重叠。 以下是一些最佳实践——它们都不是全新的想法,而是通过基于 agent 的测试新近验证的——它们使你的 API 更易于学习和使用:
1. 提供一致的、可预测的设计
一致性至关重要。 在所有地方都使用相同的模式——endpoint、参数名称、响应形状。 如果集合路由是复数(/users、/orders),但详细路由是单数(/user/{id}),则不要偷偷地插入一个流氓的 /users/{id}。 如果你的 payload 是 snake_case,则永远不要偷偷地插入一个 camelCase 字段。
人类和 LLM 几乎立即内化这些约定。 在遵循一个规则进行了五次调用之后,第六次调用也假定会遵循该规则; 任何偏差都会成为一个无声的陷阱。 最重要的是:一个 建立在可预测、一致的模式上的坚实的 API 基础 是 AI 优先的开发者体验的最大杠杆。 一致性消除了特殊情况,减少了 onboarding 的认知负荷,并尊重了经验丰富的工程师所遵循的“最少惊讶原则”。
2. 编写清晰、全面的文档(并保持更新)
良好的文档一直都很重要,但是当读者是 LLM 时,“良好”的含义会发生细微的变化。 对于 agent 而言,文档必须是完整的、明确的和集中的——否则模型会将缺失或冲突的信息视为事实。
从基础开始。 每个 endpoint 都需要一个简洁的描述,清楚地标记所需的和可选的输入,以及明确的响应结构(包括可能的错误)。 内联 JSON 示例至关重要; agent 依赖于这些示例来准确地推断 payload 结构并避免幻觉。
提供 OpenAPI spec。 GPT-4 插件和许多 agent 框架直接使用 Swagger 文件,将 spec 转换为实时 API 调用。 单个机器可读的 spec 可确保你的指南、参考和示例保持同步。
最后,停用过时的 PDF 和陈旧的论坛答案——它们会像误导人类一样误导 agent。 明确记录身份验证; agent 不会猜测 401 意味着“首先进行身份验证”。 清晰、整合且示例丰富的文档不仅仅是用户友好的——它直接决定了你的 agent 是快速成功还是通过试错来艰难挣扎。
3. 显示具有详细性和清晰度的错误
我们一直在强调错误消息,这是有充分理由的。 使你的错误消息尽可能提供信息,而不会暴露安全敏感信息。 在可行的情况下,请包括错误的具体原因和修复提示。 例如:
- 如果缺少或为空必填字段,请在错误中命名它:例如
{"error": "Missing required field 'start_date'"}。 - 如果字段格式不正确或超出范围,请解释预期值:例如
{"error": "expiry_date must be in YYYY-MM-DD format"}或{"error": "quantity must be between 1 and 100"}。 - 如果找不到 ID:
{"error": "No customer found with ID XYZ"}而不仅仅是 "Invalid ID"。 - 对于 auth 问题:如果可以,区分"
token missing" 与 "token invalid" 与 "insufficient scope"——agent 可以对每个问题做出不同的反应。
许多团队现在在错误正文中嵌入了一个文档链接。 例如,Stytch 返回一个错误代码加上一个 URL,该 URL 会直接跳转到其文档中的修复页面。 开发者可以点击进入; 如果有合适的工具,agent 可以获取页面并将其指导合并到其下一次尝试中。 消息本身应该保持详细。 JSON 结构很好——机器喜欢它——但是纯英文的“message”字段通常比完美的简洁 schema 更能帮助 LLM。 一项“AI 友好”API 实验表明,与最小化的机器格式响应相比,chatty text error 驱动了更快的 agent 恢复。
最后一步是记录你的 endpoint 可以抛出的每个错误。 列出代码、触发它的条件以及至少一个修复方法。 大多数参考资料仍然掩盖了错误情况,但是它们正是 agent——或沮丧的人——为了在失败中走向成功而不是停滞不前所需要的。
4. 通过示例和教程指导用户
一个可靠的快速入门指南对于人类和 agent 来说都是一个很好的安全保障。 对于涉及多步骤流程的产品——OAuth handshake、sandbox 交换、webhook 回调等——一个清晰的、编号的、带有 payload 示例的演练会大有帮助。 Agent 可以逐字逐句地使用这些指南; “创建你的第一个发票”中的一个片段通常会使他们立即成功,而不是偶然发现隐藏的依赖项。
以多种语言提供官方示例也很重要。 是的,LLM 可以将 cURL 转换为 Python,但是在 Python、JavaScript 和 cURL 中提供现成的模板可以消除对 headers 和 JSON 结构的歧义。
正如你所期望的那样,这些示例确实需要持续的维护。 没有什么能像由于过时的参数而导致复制粘贴的片段失败那样破坏信任了。 将示例 payload 连接到针对 staging environment 的自动化测试中,以便在 CI 中(而不是在用户面前)暴露中断。
最后,将 live sandboxed API explorers 直接嵌入到你的文档中可以实时演示工作请求。 虽然 agent 不与 GUI 交互,但是维护这些交互式示例可以使你的黄金路径保持经过测试的状态,从而确保每个人的体验更顺畅。
5. 为简单和自然使用而设计
对于人类来说感觉像是小便利的设计选择对于 AI agent 来说可能是很难的障碍。 想象一下,你的 API 强制客户端列出所有客户,抓取“Jane Doe”的数字 ID,然后在第二次调用中使用该 ID 来获取她的个人资料。
人可以勉强完成此操作。 如果只给出名称,agent 就没有前进的路径。 单个搜索 endpoint GET /customers?query=Jane%20Doe 可以解决这两个问题,并将两个调用减少为一个调用。 同样的原则也适用于更高级别的“快捷方式”路由、批量操作或摘要 endpoint。 如果开发者要求它们,那么 agent 可能会从中受益更多,因为它可以在更简单的推理链中保持不变。
粒度也很重要。 LLM 仍然有上下文窗口; 将某人需要的唯一 BTCUSD 价格埋在 1 万行 payload 中会浪费 tokens 并有被截断的风险。 像 GET /prices?symbol=BTCUSD 这样的过滤器或分页响应可让模型仅使用相关的数据片段,并同时节省你的带宽。
简而言之,当你简化 API 以最大程度地减少查找、跳转和 payload 膨胀时,你不仅在润色 DX,而且还在改善 AX,因为 agent 无法即兴解决这些障碍。
6. 闭环反馈
将每个 agent 运行和每个开发者支持票证都视为 live feedback loop 中的数据。 当相同的问题一遍又一遍地出现时,假设你的文档或 API 不足; agent 很可能就在那个地方绊倒了。 修复文档,添加清晰的示例,或者,如果摩擦是结构性的,则调整 endpoint 本身。
现在,在文档和 Slack channel 中部署 LLM assistant 变得越来越普遍。 每次 bot 回答“我不确定”时,你都已确定了一个文档差距。 这是类固醇上的搜索分析。 开发者会立即获得答案(或偶尔出现幻觉),并且你可以清楚地看到缺少的内容。
生产日志提供了另一种视角。 如果你看到重复的、带有过时参数或缺少版本前缀的调用,请主动添加有针对性的错误(“你是说 X 吗?”)或优雅地处理旧版输入。 更明确的指导有助于 agent 和人类进行自我纠正。
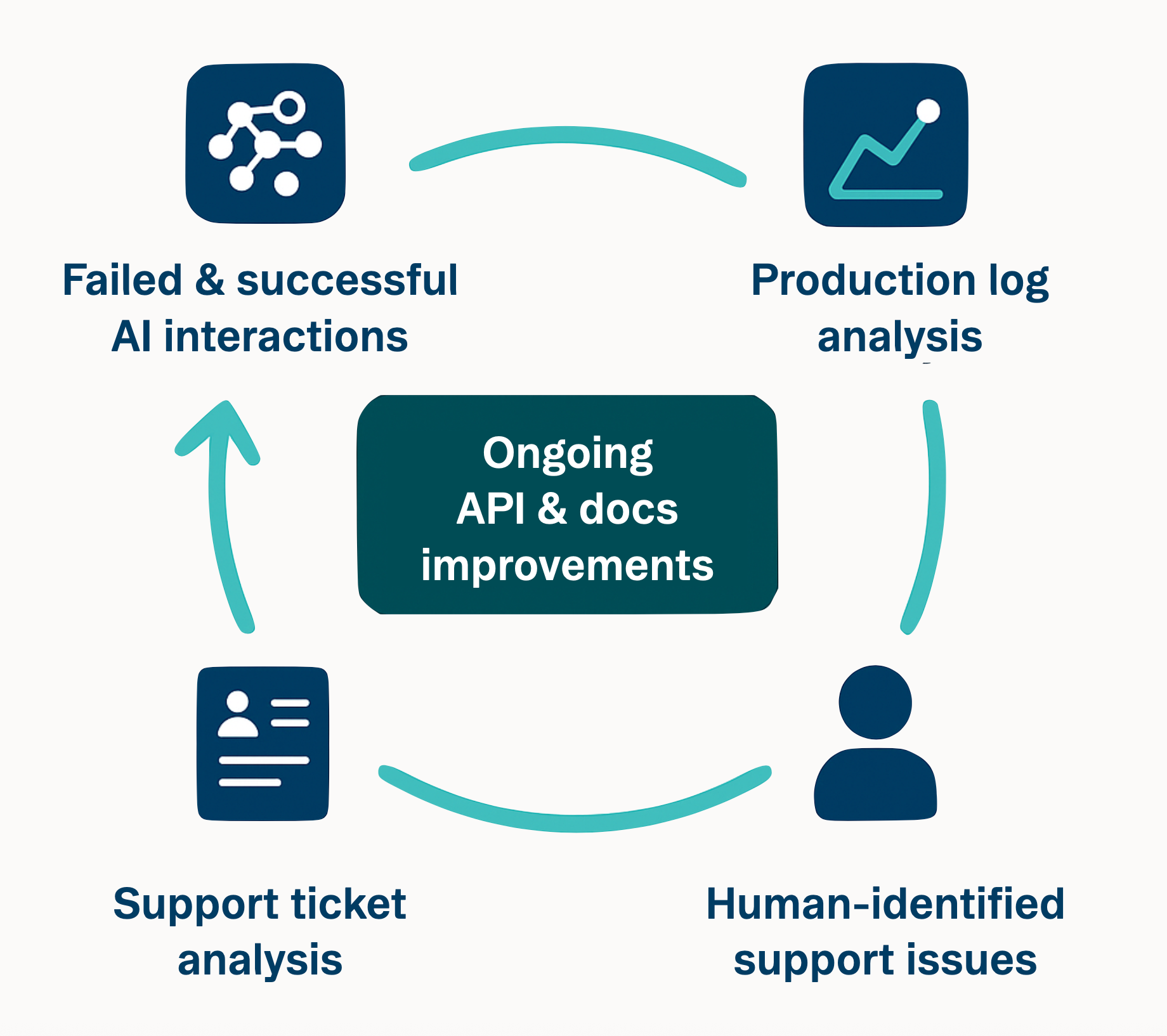
这种心态可以将 DX 变成一种持续的实践,而不是一次性的可交付成果。 你不再仅仅为人类设计,而是为任何客户(人类或机器)设计。 为 agent 的零先验知识构建,可以强制执行明确性和一致性,从而创造出直接使人类开发者受益的清晰度。
DX 的卓越是双赢
基于 LLM 的 agent 正在滑入日常工程中——编写胶水代码、连接 SaaS 产品,甚至回答论坛帖子。 当 开发者 和 用户代理 之间的界限变得模糊时,一个真理仍然成立:出色的 DX 仍然是王道。
如果 agent 因含糊不清的文档或神秘的错误而窒息,则实际的开发者将在同一地点受阻。 将每次 agent 失败都视为可用性错误。 它标志着文档、错误或流程设计中的差距,这些差距应立即修复。
这种心态将 DX 和 AX 融合在一起。 核心成分——清晰的参考、一致的模式、可操作的错误——没有改变,但是对粗糙边缘的容忍度已经消失了。 使用 agent 作为不知疲倦的实习生:运行黄金路径,记下其破坏的位置,修补,重复,直到运行变得枯燥乏味。
润色 agent 的路径,每个新人都会受益。 支持票证减少,口碑上升,而下一个正在寻找展示 API 的自动代码工具可能会选择你的 API。 为 agent 构建,并为每个人构建。