Litestream:重大升级
Litestream:重大升级
作者

姓名 Ben Johnson
@benbjohnson @benbjohnson
 Image by Annie Ruygt
Image by Annie Ruygt
Litestream 是一个开源工具,它通过使 SQLite 应用能够从对象存储中可靠地恢复,从而使得在 SQLite 之上运行各种全栈应用成为可能。 这篇文章是关于我发布它以来,我们对其所做的最大改变。
大约十年前,我萌生了一个想法。我想要快速构建全栈应用。 但是传统的 n 层数据库设计要求我为我发布的每个应用做系统管理工作。 即使是最简单的应用程序也依赖于像 Postgres 或 MySQL 这样的重量级数据库服务器。
我想在 SQLite 上发布应用,因为 SQLite 很简单。 但是 SQLite 是嵌入式的,而不是服务器,这在当时意味着我的应用程序的数据仅仅存在于一台服务器上(并随着服务器消亡)。
所以在 2020 年,我编写了 Litestream 来解决这个问题。
Litestream 是一个与 SQLite 应用一起运行的工具。 在不更改正在运行的应用程序的情况下,它接管 WAL 检查点进程,以持续地将数据库更新流式传输到兼容 S3 的对象存储。 如果运行应用程序的服务器发生任何情况,整个数据库都可以有效地恢复到不同的服务器。 您可能会丢失服务器,但不会丢失数据。
Litestream 运行良好。 所以我们变得雄心勃勃。 几年后,我们构建了 LiteFS。 LiteFS 采用了 Litestream 中的思想并对其进行了改进,以便我们可以使用 SQLite 进行读取副本和主节点故障转移。 LiteFS 为 SQLite 提供了像 Postgres 这样的 n 层数据库的现代部署故事,同时保持数据库的嵌入式特性。
我们喜欢 LiteFS 和 Litestream。 但是 Litestream 是更受欢迎的项目。 它更易于部署且更易于理解。
LiteFS 中有一些很好的想法。 我们希望 Litestream 用户能够从中受益。 因此,我们采用了 LiteFS 的经验并将其应用于 Litestream 的一些新功能中。
时间点还原,但更快
这是 Litestream 最初的设计方式:您针对 SQLite 数据库运行 litestream,它会打开一个长期存在的读取事务。 此事务会阻止 SQLite WAL 检查点,即 SQLite 将 WAL 合并回主数据库文件的过程。 Litestream 构建了一个“影子 WAL”,用于记录 WAL 页面,并将它们复制到 S3。
这很简单,这很好。 但它也可能很慢。 当您想要还原数据库时,您必须拉取并重放自上次快照以来的每个更改。 如果您将单个数据库页面更改了一千次,则您将重放一千次更改。 对于频繁写入的数据库,这不是一个好方法。
在 LiteFS 中,我们采用了不同的方法。 LiteFS 具有事务感知能力。 它不仅记录原始 WAL 页面,还记录与事务关联的页面的有序范围,使用我们称之为 LTX 的文件格式。 每个 LTX 文件代表给定时间段内页面的排序变更集。
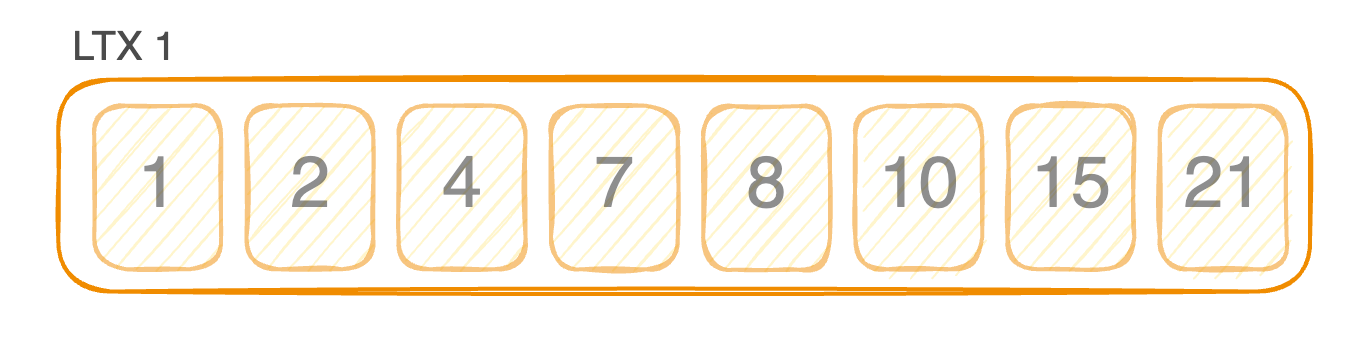
因为它们是排序的,所以我们可以轻松地将多个 LTX 文件合并在一起,并创建一个仅包含每个页面最新版本的新 LTX 文件。
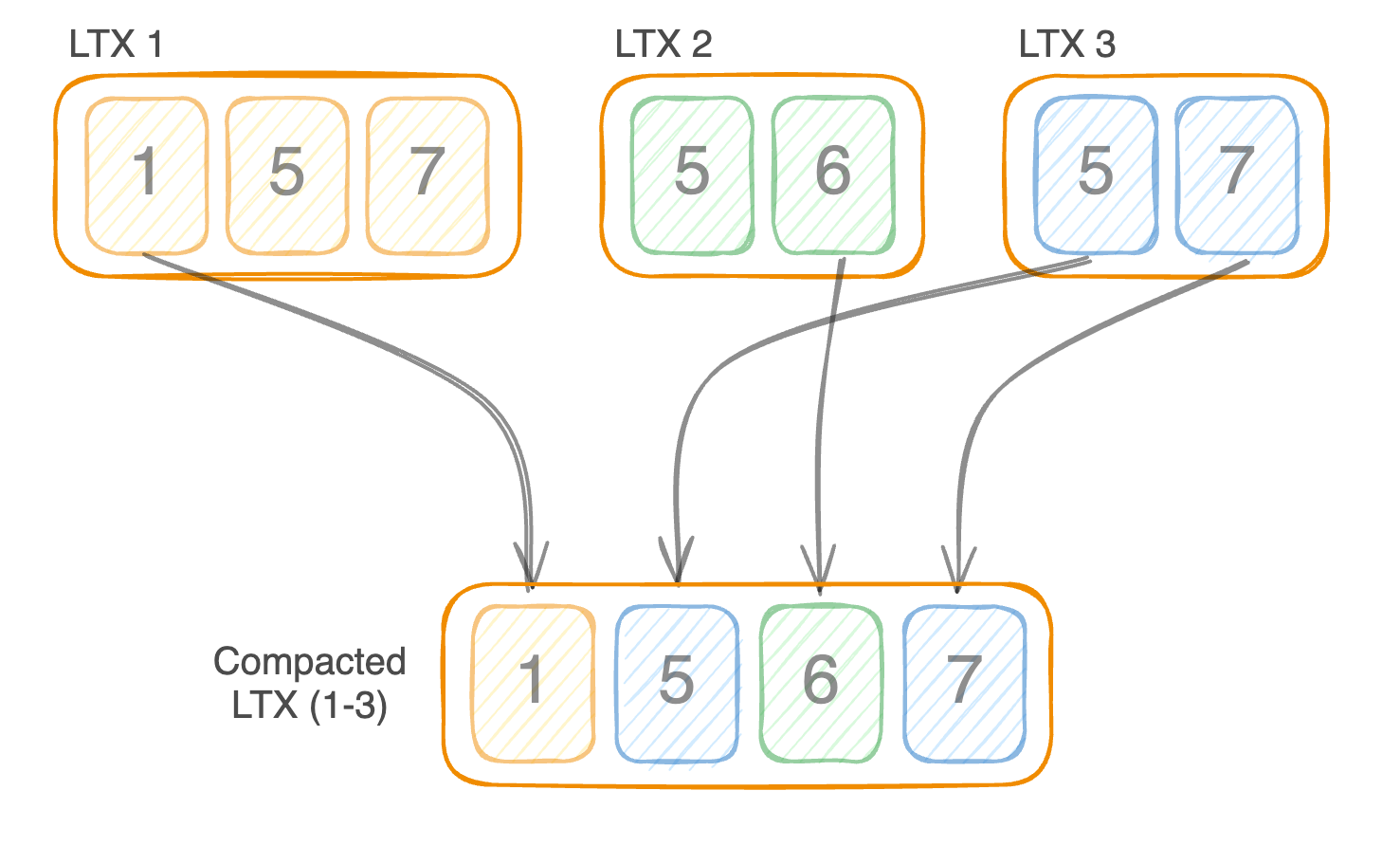
这类似于 LSM 树 的工作方式。
将较小的时间范围组合成较大的时间范围的过程称为 compaction(压缩)。 有了它,我们可以将 SQLite 数据库重放到特定的时间点,并最大程度地减少重复页面。
CASAAS:作为服务的 Compare-and-Swap(比较和交换)
Litestream 必须处理的一个挑战是不同步。 Litestream 的部分意义在于 SQLite 应用程序不必了解它。 但是 litestream 只是一个进程,与应用程序一起运行,并且它可以独立死亡。 如果在数据库更改发生时 litestream 停止运行,它将错过更改。 如果您从新服务器开始复制,也会发生同样的问题。
Litestream 需要一种从新快照重置复制流的方法。 它使用“世代”来做到这一点。 一个世代代表一个快照和一个 WAL 更新流,具有唯一的标识。 Litestream 会注意到其 WAL 序列中的任何中断并启动一个新的世代,这就是它从不同步中恢复的方式。
不幸的是,存储和管理多个世代使得实现故障转移和读取副本等功能变得困难。
解决此问题的最直接方法是确保只有一个 Litestream 实例可以复制到给定的目标。 如果您可以做到这一点,您就可以只存储一个最新的世代。 反过来,这使得很容易知道如何重新同步读取副本; 只有一代可以选择。
在 LiteFS 中,我们通过使用 Consul 解决了这个问题,Consul 保证了只有一个 leader。 这要求用户了解 Consul。 诸如“需要 Consul”之类的事情可能是 Litestream 比 LiteFS 更受欢迎的部分原因。
在 Litestream 中,我们以不同的方式解决这个问题。 像 S3 和 Tigris 这样的现代对象存储为我们解决了这个问题:它们现在提供 条件写入支持。 通过条件写入,我们可以实现基于时间的租约。 我们基本上获得了 Consul 给我们的相同约束,而无需考虑它或设置依赖项。
立即地,这意味着您可以使用具有重叠运行时间的临时节点运行 Litestream,即使它们存储到相同的目标,它们也不会相互混淆。
轻量级读取副本
Litestream 和 LiteFS 最初的设计约束是在不干扰人们构建的代码的情况下将 SQLite 扩展到现代部署场景。 这两种工具都旨在发挥作用,即使应用程序没有意识到它们。
LiteFS 比 Litestream 更雄心勃勃,并且需要事务感知能力。 为了在不干扰构建的代码的情况下获得它,我们使用了一个巧妙的技巧(又名一个糟糕的 hack):LiteFS 提供了一个 FUSE 文件系统,这使得它可以充当应用程序和后备存储之间的代理。 从这个有利位置,我们可以轻松辨别事务。
FUSE 方法给了我们很大的控制权,足以让用户像使用任何其他数据库一样使用 SQLite 副本。 但是安装和运行整个文件系统(即使是假的文件系统)对用户来说要求很高。 为了解决这个问题,我们放宽了一个约束:如果您将扩展加载到您的应用程序代码 LiteVFS 中,LiteFS 可以在没有 FUSE 文件系统的情况下运行。 LiteVFS 是一个 SQLite 虚拟文件系统 (VFS)。 它可以在各种环境中使用,包括一些 FUSE 无法使用的环境,例如浏览器内 WASM 构建。
接下来我们要做的就是采用同样的技巧并在 Litestream 上使用它。 我们正在构建一个基于 VFS 的读取副本层。 它将能够直接从兼容 S3 的对象存储中获取和缓存页面。
当然,有一个问题:这种方法不如本地 SQLite 数据库有效。 这种效率,即您甚至不需要考虑 N+1 查询,因为没有网络往返来使重复查询堆积成本,是使用 SQLite 的部分意义。
但是我们乐观地认为,通过缓存和预取,我们使用的方法将在正确的用例中产生强大的性能——同时为 SQLite 读取提供 Tigris 或 S3 的热数据。
Litestream 是完全开源的
它完全没有与 Fly.io 耦合; 你可以在任何地方使用它。

同步大量数据库
既然您在这里:我们正在敲定我们最需要的功能之一。
在旧的 Litestream 设计中,WAL 更改轮询和缓慢的还原使得从单个进程复制大量数据库变得不可行。 当用户要求我们为该工具提供“通配符”或“目录”复制参数时,这就是我们的答案。
现在我们已经切换到 LTX,这不再是一个问题了。 因此,即使该目录中有数百或数千个数据库,也可以复制 /data/*.db。
我们仍然 ❤️ SQLite
SQLite 一直是一个坚实的构建基础的数据库,并且随着行业的发展,它不断找到新的用例。 我们非常高兴能继续与它一起构建 Litestream。
我们有一种隐隐的怀疑,即编写 LLM 代码的机器人也会喜欢 SQLite。 我们认为像 Phoenix.new 这样的编码代理 需要的是一种在实时数据上尝试代码、搞砸它,然后回滚_代码和状态_的方法。 这些 Litestream 更新使我们能够将 PITR 作为原始功能提供给代理。 最重要的是,您可以构建回滚和分支。
无论您是否喝了 AI 酷爱饮料,我们都认为这种 Litestream 的新设计更好。 我们很高兴能推出它,并为它将实现的功能感到兴奋。
上次更新 • 2025 年 5 月 20 日