我们如何提高光学字符识别 (OCR) 代码的准确性
我们如何提高光学字符识别 (OCR) 代码的准确性
了解 Pieces 如何增强其光学字符识别 (OCR) 引擎,以提高软件开发人员的准确性、速度和实际应用能力。

什么是光学字符识别?
光学字符识别 (OCR) 是一种技术,它可以识别数字图像或扫描文档中的印刷或手写字符,并将其转换为机器可读的文本。
这项技术彻底改变了文档处理,能够从纸质文档中提取信息,并将其转换为可编辑和可搜索的数字格式。
OCR 系统使用先进的算法来分析图像中字符的形状、大小和位置,并将其与已知字符的数据库进行匹配。最终将视觉数据转换为可读文本。
机器学习和 AI 驱动的 OCR 技术进步,大大提高了其准确性。
OCR 现在广泛应用于文档扫描、数据录入自动化以及为视力障碍人士提供的文本转语音技术等应用中。
Pieces 的光学字符识别
在 Pieces,我们一直致力于专门为代码微调 OCR 技术。
我们使用 Tesseract 作为主要的 OCR 引擎,它在预测字符之前_执行布局分析_,并使用在文本图像对上训练的 LSTM (Long Short-Term Memory)。
Tesseract 是最好的免费 OCR 工具之一,支持 100 多种语言,我们的一些用户 使用 OCR+Pieces 构建了自己的工具。
但是,它的开箱即用功能对于代码来说并不理想,这就是我们通过特定的预处理和后处理步骤来增强它的原因。
通过图像预处理标准化输入
为了在软件工程师想要转录图像中的代码时提供最佳支持,我们微调了我们的预处理流水线,使其适应 IDE、终端和在线资源(如 YouTube 视频和博客文章)中的代码屏幕截图。
由于编程环境可以是浅色模式或深色模式,因此这两种模式都应该产生良好的结果。
此外,我们希望支持具有渐变或嘈杂背景的图像(例如在 YouTube 编程教程或复古网站中可能找到的图像),以及低分辨率图像(例如,从上传或发送屏幕截图进行压缩的图像)。
由于 Tesseract 的图像处理中的字符识别在二值化、浅色模式图像上效果最佳,因此我们需要在预处理中反转深色模式图像。

为了确定哪些图像处于深色模式,我们的引擎首先对图像进行中值模糊以消除异常值,然后计算平均像素亮度。
如果它低于特定阈值,则确定为深色并因此反转。
为了处理渐变和嘈杂的背景,我们使用基于膨胀的方法。
我们生成图像的副本,并在其上应用膨胀内核和中值模糊。
然后,我们从原始图像中减去这个模糊的副本,以消除黑暗区域,而不会干扰图像中的文本。
对于低分辨率图像,我们使用双三次插值根据输入大小对图像进行上采样。

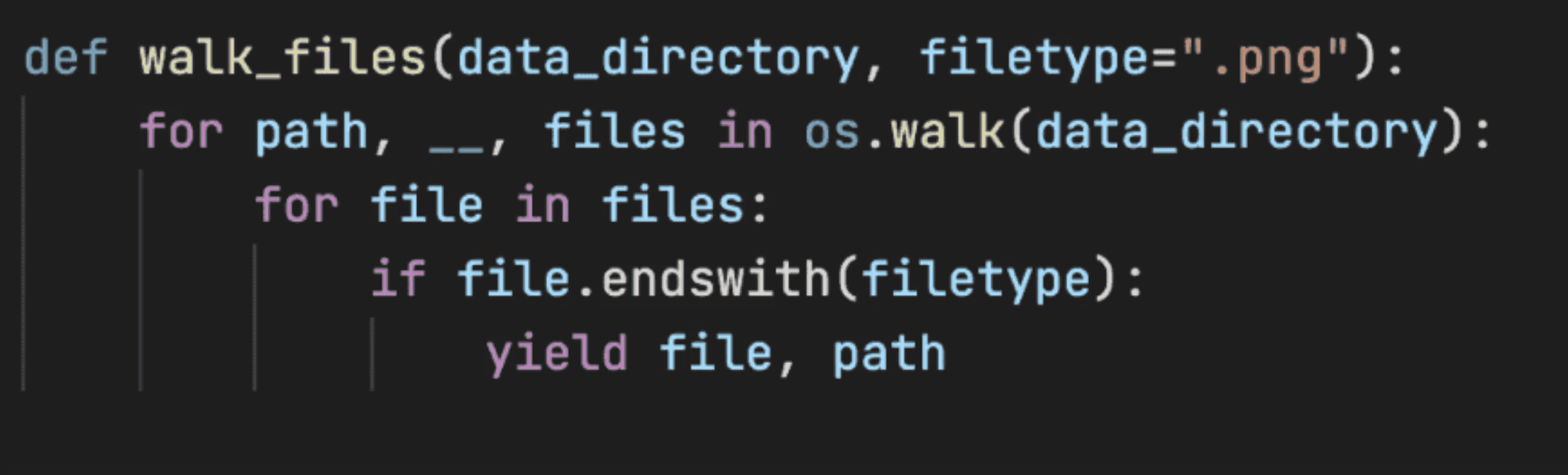
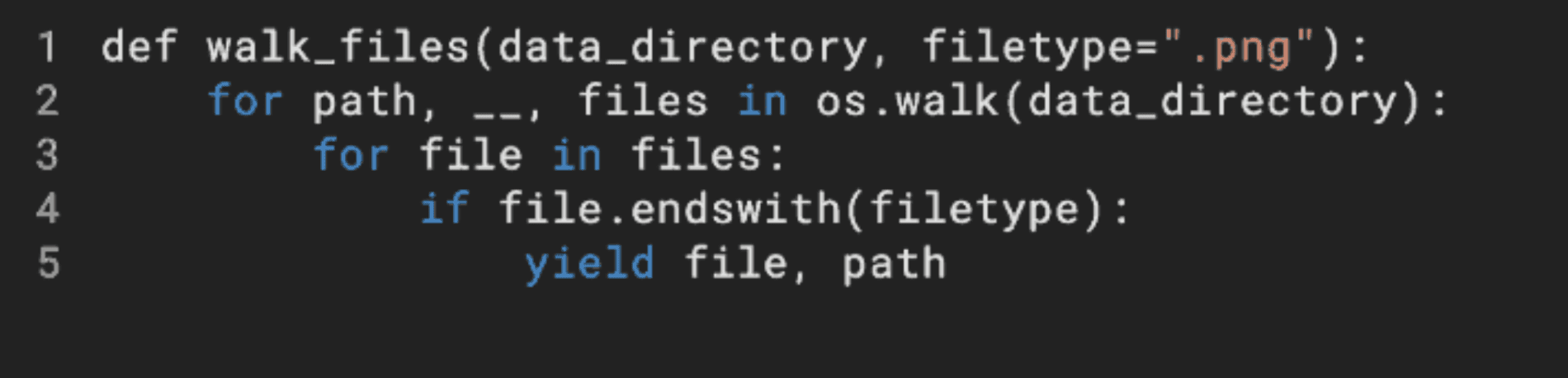
代码需要布局格式
在 Tesseract 的文本预测中,我们执行 OCR 布局分析并推断生成的代码的缩进。
默认情况下,Tesseract 不缩进任何输出,这不仅会降低代码的可读性,甚至会改变 Python 等语言中的含义。
为了添加缩进,我们使用 Tesseract 为每行代码返回的边界框。
使用框的宽度及其中的字符数,我们计算该行中字符的平均宽度。
然后,我们使用该框的起始坐标来计算与其他代码行相比,它的缩进了多少个空格。
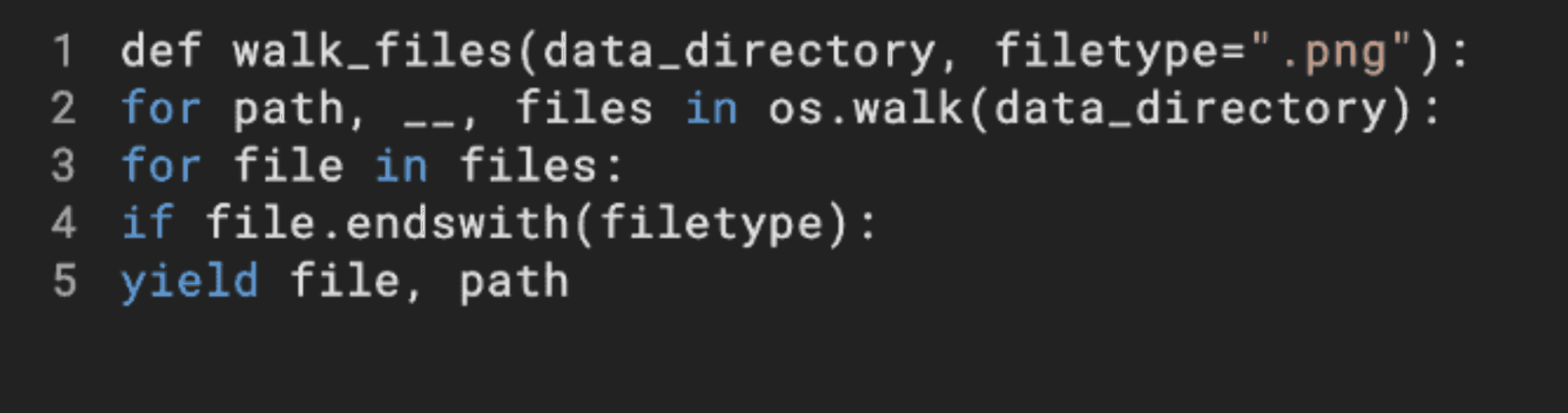
之后,我们使用一个简单的启发式方法将缩进推入偶数个空格。
评估我们的流水线
为了评估我们对 OCR 流水线的修改,我们使用多个手工制作和生成的图像文本对数据集。
通过在每个图像上运行 OCR,然后我们计算预测文本与真实文本之间的 Levenshtein 距离。
我们将每个修改视为一个研究假设,然后使用实验来验证它。
例如,对于上采样小图像,我们的研究假设是,像 SRCNN (Super-Resolution Convolutional Neural Network) 这样的超分辨率模型将比最近邻插值或双三次插值等标准上采样方法更能提高 OCR 性能。
为了测试这个假设,我们在相同的数据集上多次运行 OCR 流水线,每次都使用不同的上采样方法。
虽然我们发现最近邻上采样图像产生的结果更差,但我们没有发现基于超分辨率的上采样和双三次上采样对我们的流水线有显着差异。
鉴于超分辨率模型需要更多的存储空间并且比双三次上采样具有更高的延迟,我们决定为我们的流水线选择双三次上采样。

总的来说,正确获取 OCR 代码是一个具有挑战性的目标,因为它必须捕获高度结构化的语法和格式,同时允许非结构化的变量名和代码注释。
我们很高兴提供首批针对代码进行微调的 OCR 模型之一,并将继续改进该模型,使其更快、更准确,以便您可以从屏幕截图中获得可用的代码并继续编码。
要使用您的代码屏幕截图测试我们的模型,请下载 Pieces 桌面应用程序。
如果您是开发人员并且对我们的 API 感兴趣,请发送电子邮件至 smit@pieces.app
我们已经与 Github、Cursor 集成,最近 实现了 MCP。
如果您喜欢这篇文章,您可能想阅读我和我的一些同事撰写的以下文章:
