构建一个能够自我改进的 Agentic Image Generator

构建一个能够自我改进的 Agentic Image Generator
Palash Shah 2025年5月15日
背景
在 Bezel,我们为大型品牌创建 personas(用户画像),并帮助他们对其内容进行模拟。在这个过程中,品牌开始要求我们生成针对其客户量身定制的广告灵感。
首先,我们使用 OpenAI Image API 来生成和编辑图像。它有两个主要的 endpoint:
/create[](https://simulate.trybezel.com/research/<https:/platform.openai.com/docs/guides/image-generation?image-generation-model=gpt-image-1>)endpoint 用于生成图像。它接收一个 prompt,并返回生成的图像。/edit[](https://simulate.trybezel.com/research/<https:/platform.openai.com/docs/guides/image-generation?image-generation-model=gpt-image-1>)endpoint 用于编辑图像。它接收一张图像和一个 prompt,并返回编辑后的图像。您还可以提供 masks(遮罩)来指定要编辑图像的哪些部分。
此外,我们使用了一组 LLMs 作为 evaluators(评估器),使用各种方法来检测图像中的问题:
o3用于检测文本模糊和图像吸引力方面的问题。我们测试了各种其他 reasoning models(推理模型),发现这是最有效的。gemini-2.5-flash-preview-04—17作为与o3比较性能的基准。
方法论
我们的目标是构建一个能够自动提高 OpenAI API 生成的图像质量的系统。为此,我们需要一个强大的 evaluator 来检测缺陷,例如扭曲的文本或较弱的视觉吸引力,以及一个迭代反馈循环,以便每次迭代都改进图像。
定义一个初始 Prompt
我们首先定义一个初始 prompt 来生成我们的广告。如下所示,我们确定了一个 prompt,其中包含图像生成模型创建的各种不同的、具有挑战性的组件。
一个 Redbull 夏季活动的广告。它应该包含多种口味的 RedBull,周围有很多颜色。图像应该位于旧金山的一个屋顶上,很多人像参加派对一样社交。在右下角以纯文本形式包含一个折扣代码。
我们发现 gpt-image-1 很难从这个 prompt 生成高质量的图像。虽然总体概念存在,但结果感觉像是一种模糊的抽象。不同的视觉元素似乎压倒了模型详细渲染每个元素的能力。
方法 1:LLM-as-a-Judge 用于文本改进
文本模糊检测
LLM-as-a-Judge(LLM 作为评判者)首先被选为模糊和扭曲文本的评估方法。我们首先提示 o3 来识别最初生成的图像中的差异。
我们从上面的 prompt 中获取输出图像,并请求 o3 识别图像中与文本模糊或扭曲相关的所有问题。输出看起来像一系列特定问题,例如:
橙色罐:假设的风味名称('PEACH')以一种细而粗糙的风格呈现,与背景融为一体;大多数字母不完整或缺失,因此文本不可读。
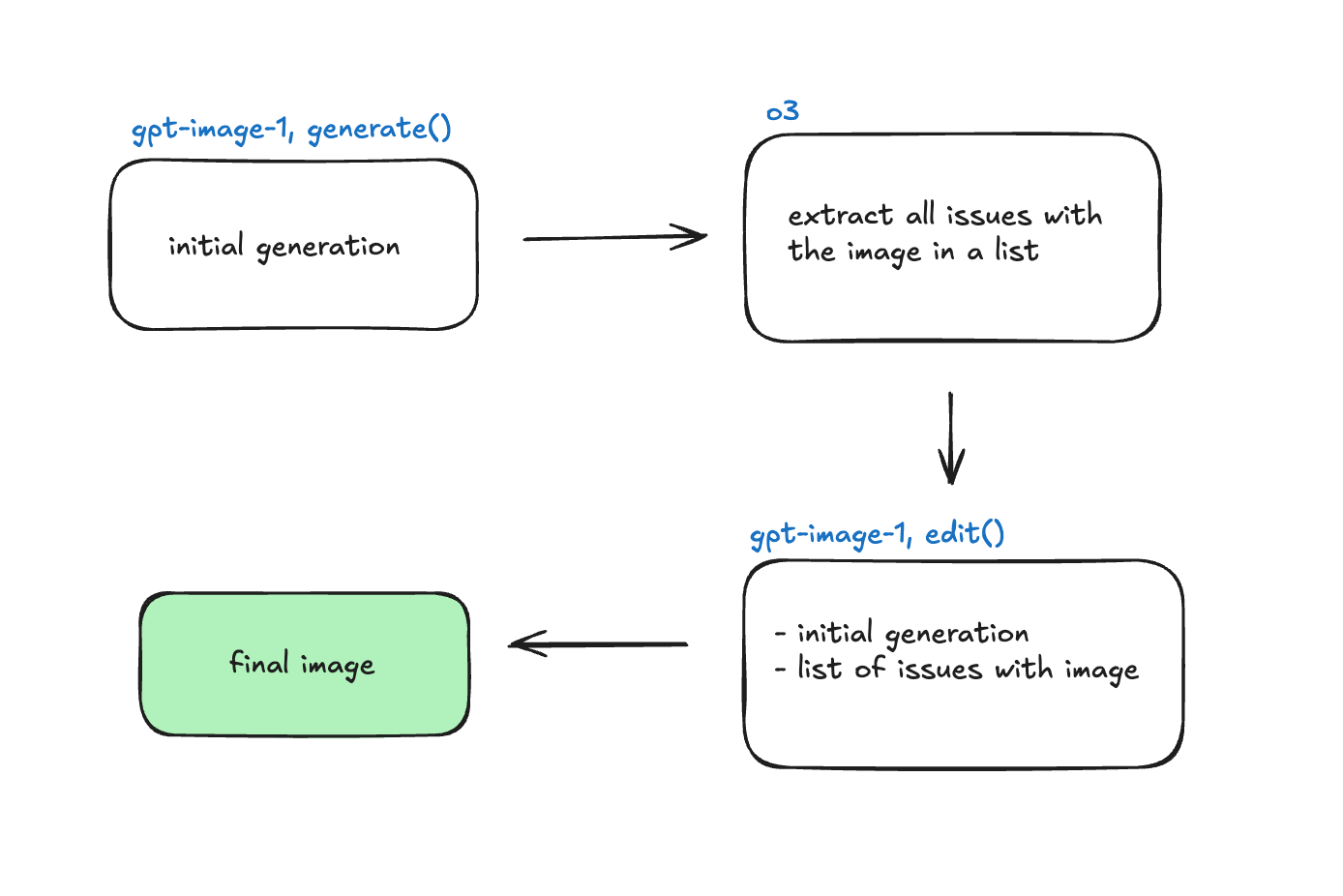
LLM-as-a-judge 实现
迭代编辑图像
在存储了所有生成的问题后,我们使用原始图像和此问题列表来提示 /edit endpoint。以下是我们了解到的关于检测和修复这些问题的所有内容:
- 您需要非常具体地说明输入图像中什么是缺陷。当我们具体询问文本模糊的含义时,我们开始检索到准确的缺陷。
- 与更传统的模型相比,Reasoning Models(推理模型)作为多模式评判者要好得多。
- 在增量循环中检测异常(要求 LLM 检测单个问题,提供该问题+图像,要求它检测另一个问题直到没有剩余问题)效果很好。非常昂贵,但具有最高的准确性。以下是此实现的一个简化的伪代码示例:
function detectAndFixIssues(image, prompt) {
let currentImage = image;
while (const issue = askLLM("Find ONE issue", currentImage)) {
currentImage = editImage(currentImage, issue);
}
return currentImage;
}
通过 LLM 作为评判者,我们能够非常一致地在多次迭代中改进图像的文本模糊度。迭代次数通常徘徊在 3 次左右,具体取决于图像的复杂性。我们还发现,在 3 次迭代后,改进达到了一个平台期,表明该模型的能力存在技术上限。
扩展到文本之外:构图和吸引力
现在我们已经成功创建了一个 evaluator 来检测文本中的问题,我们希望转移到更抽象的问题。我们将要添加 evaluator 来检测的两个问题是:
- 图像构图: 我们要求
o3推断图像所有组成部分(背景、产品、文本)的放置是否具有吸引力。 - 吸引力: 我们要求
o3推断,从特定 persona 的角度来看,该图像是否对他们有吸引力。
下面显示了 evaluator 的一个示例输出:

需要改进的模糊文本示例
- 文本清晰度:罐上的产品文本不完全清楚。字母显得扭曲,难以阅读品牌和风味信息。确保字体清晰易读,并与罐的背景形成足够的对比。2. 模糊度:以人和天际线为特色的背景略微失焦,这可能是为了突出罐而有意为之。但是,如果罐是主要产品,则对罐的聚焦应该更清晰。确认产品是焦点。4. 图像构图:虽然大多数文本都在框架内,但要确保每个罐上的品牌标识都完全可见且未被切断。考虑重新定位罐或调整视角。5. 整体吸引力:色彩鲜艳的粉末效果增加了视觉吸引力,但要确保它不会掩盖产品本身或分散人们的注意力。
现在的输出包括图像扭曲的地方、对图像构图和定位的观察,以及对一组 personas 的吸引力。
结果与局限性
结果很差。我们的假设如下。
我们认为该模型遇到困难,因为它被要求同时执行两项根本不同的任务:一项是创造性的——改善图像构图并与目标 personas 保持一致——另一项是技术性的——增强文本元素的像素级清晰度。
为了证明这一假设,我们设计了一种辅助方法。在这种方法中,我们将从低质量的生成开始,并使用 evaluator 来修复文本清晰度问题。然后,我们将进行 upscale(放大),并创建一个单独的 LLM-as-a-judge 来修复图像构图问题。
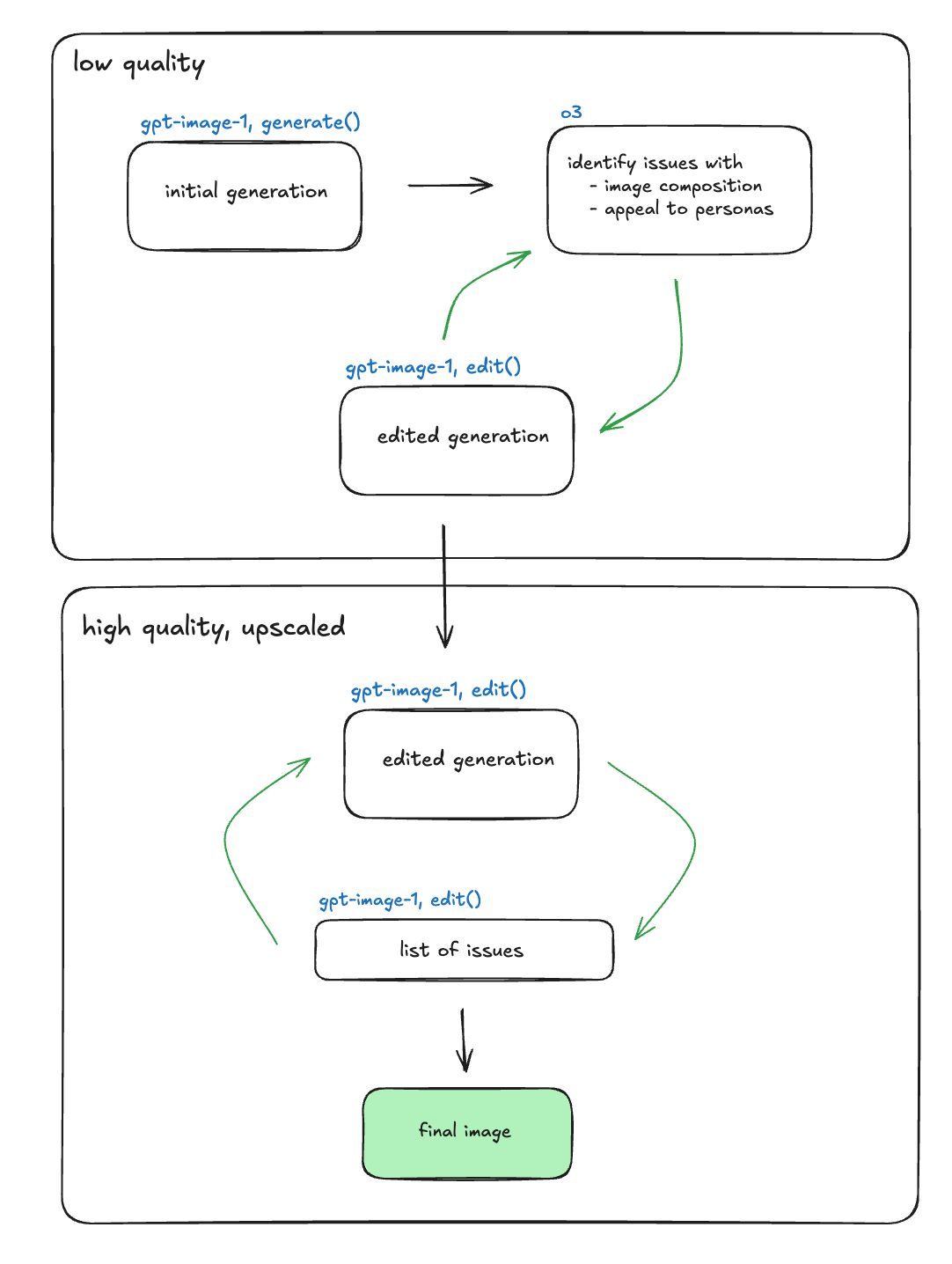
顶部工作流程是文本校正器,底部是质量模块。

初始图像

中间图像

最终的 upscale 图像
事实证明,这种方法更加有效。
方法 2:Bounding Box(边界框)方法
我们发现在使用 LLM-as-a-Judge 进行文本模糊时,图像修改不仅限于 evaluator 列举的问题。它经常改变图像的其他部分。
文本模糊检测
为了识别模糊文本,我们提出了一种替代方法,即要求推理模型生成文本问题的 bounding boxes。然后,我们将这些 boxes 作为 masks 提供给 OpenAI API 的 edit endpoint,以修改相关区域。
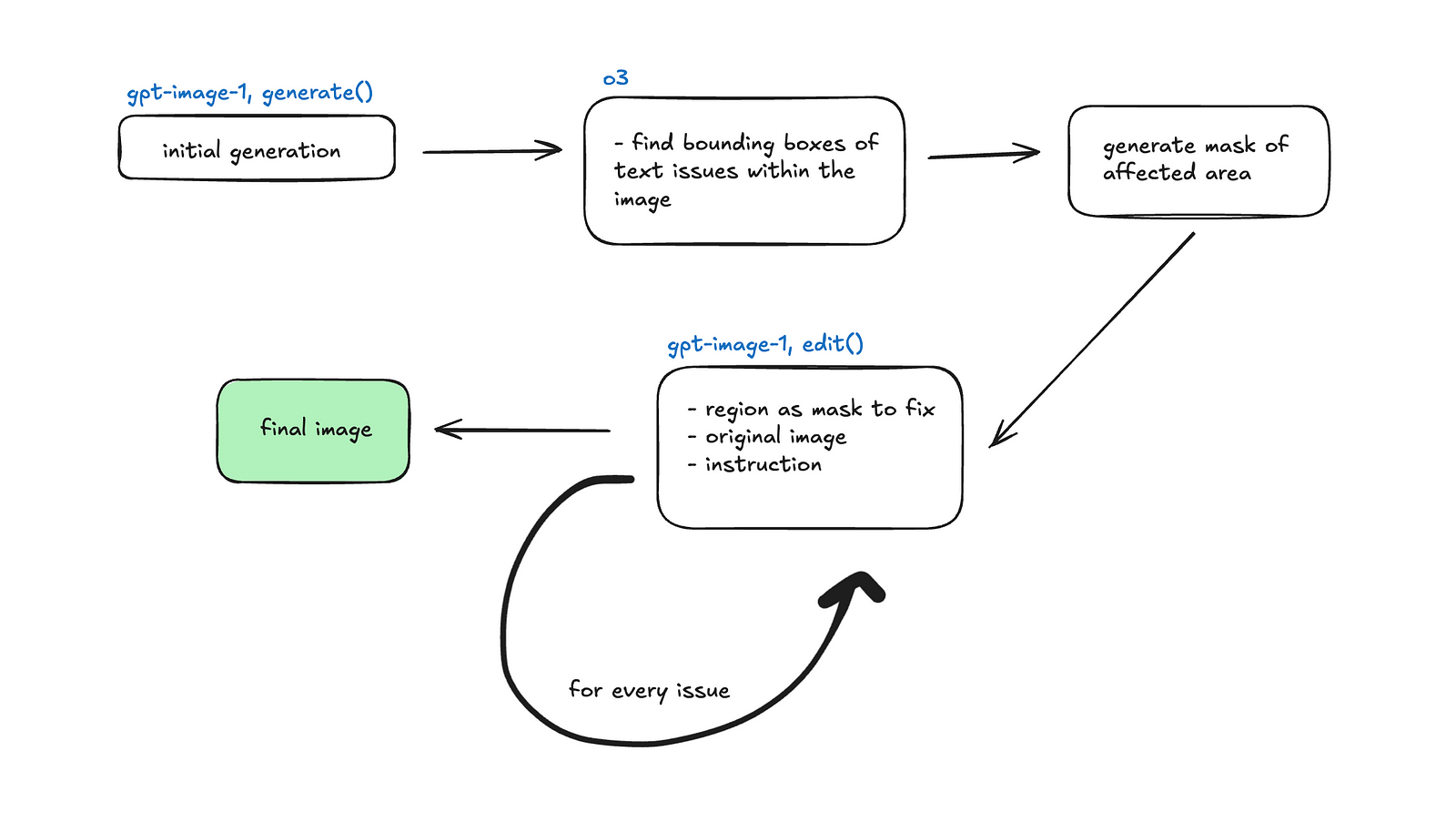
Bounding box 方法
用于此目的的 prompt:描述此图像中模糊的文本,并以 JSON 格式提供其 bounding boxes。文本应该是模糊且无法阅读的。这些是需要改进的文本。JSON 应该是一个包含“description”(字符串)字段和一个“objects”(数组)字段的对象。“objects”数组中的每个对象都应该有一个“label”(字符串)字段和一个“box”字段(包含 4 个整数的数组 [x_min, y_min, x_max, y_max])。假设 box 坐标相对于图像尺寸(0-1 比例)。JSON 结构示例:
{ "description": "...", "objects": [ {"label": "...", "box": [x_min, y_min, x_max, y_max]}, ... ] }
包括图像的尺寸以及 bounding box 的输出格式 [x_min, y_min, x_max, y_max]。我们首先使用 o3 对此进行测试,结果很差。为了验证这是否是一个可以推广到其他 LLMs 的问题,我们也使用 gemini-2.5-flash-preview-04—17 进行了测试。
结果与局限性

gemini-2.5-flash bounding box 检测

o3 bounding box 检测
很明显,LLMs 无法产生强大的像素关联。LLM 能够始终如一地识别图像中在自然语言中准确的问题,但很难将其转换为图像平面上的点。例如:
品牌名称显示拼写错误('PodBul'),字符在 box:[706, 634, 860, 808] 处略有模糊和扭曲(相对值:[0.46, 0.62, 0.56, 0.79])
在上面的示例中,拼写错误被正确检测到。但是,bounding box 坐标不准确,因为它们没有完全捕获有问题的文本。

Bounding box 作为透明 masks
由于 bounding boxes 的不准确,将它们作为 mask 提供给 OpenAI API 的 edit endpoint 是无效的。出于本报告的目的,我们省略了这种方法的其他方法。
结论
我们对 agentic image generation 的探索揭示了关于多模式 evaluators 和 editors 的很多信息。
虽然 LLMs 在自然语言推理视觉缺陷方面表现出强大的能力,特别是在语义级别的缺陷,例如难以辨认的文本或扭曲的品牌标识,但它们很难将这些高级见解映射到精确的像素空间操作中。这在需要空间准确性的任务中尤为明显,例如 bounding box 生成或本地化 masks。
我们发现,当推理被限制在离散的、范围明确的维度时,LLMs 表现出色,但当被要求平衡抽象的美学判断与确定性的像素级校正时,它们的性能会下降。这种不匹配表明 LLMs 在桥接符号理解和空间基础方面存在脱节,尤其是在需要 surgical image edits(精细图像编辑)的迭代工作流程中。
LLM-as-a-Judge 应该是图像生成的多模式评估中的首选方法。我们正处于图像生成新时代的开端,我们可以提供模型所走的道路,并观察它们迭代地改进。
© 2025 Bezel Research。版权所有。 引用为:Bezel Research Team。(2025)。Agentic Image Generation 指南。Bezel Research Papers。