Ruby 3.5 中的快速分配(Fast Allocations)

Ruby 3.5 中的快速分配(Fast Allocations)
2025-05-21 • Aaron Patterson 许多 Ruby 应用程序都会分配对象。如果我们可以将对象分配速度提高六倍呢? 我们可以! 阅读更多以了解详情!
加速 Ruby 中的对象分配
Ruby 3.5 中的对象分配将比以前的 Ruby 版本快得多。 我想从基准测试和图表开始这篇文章,但如果你继续阅读,我还会解释我们是如何实现这种加速的。
对于分配基准测试,我们将比较不同类型的参数(位置参数和关键字参数),无论是否启用 YJIT 。 我们还将改变传递给 initialize 的参数数量,以便我们可以看到性能如何随着参数数量的增加而变化。
完整的基准测试代码可以在下面展开找到,但基本如下所示:
class Foo
# 衡量参数增加时的性能
def initialize(a1, a2, aN)
end
end
def test
i = 0
while i < 5_000_000
Foo.new(1, 2, N)
Foo.new(1, 2, N)
Foo.new(1, 2, N)
Foo.new(1, 2, N)
Foo.new(1, 2, N)
i += 1
end
end
test
完整基准测试代码 位置参数基准测试:
N = (ARGV[0] || 0).to_i
class Foo
class_eval <<-eorb
def initialize(#{N.times.map { "a#{_1}" }.join(", ") })
end
eorb
end
eval <<-eorb
def test
i = 0
while i < 5_000_000
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
Foo.new(#{N.times.map { _1.to_s }.join(", ") })
i += 1
end
end
eorb
test
关键字参数基准测试:
N = (ARGV[0] || 0).to_i
class Foo
class_eval <<-eorb
def initialize(#{N.times.map { "a#{_1}:" }.join(", ") })
end
eorb
end
eval <<-eorb
def test
i = 0
while i < 5_000_000
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
Foo.new(#{N.times.map { "a#{_1}: #{_1}" }.join(", ") })
i += 1
end
end
eorb
test
我们想衡量这个脚本需要多长时间,但要改变我们传递的参数的数量和类型。 为了强调对象分配的成本,同时尽量减少循环执行的影响,该基准测试每次迭代分配多个对象。
运行带有 0 到 8 个参数的基准测试代码,改变参数类型以及是否启用 YJIT 将产生以下图表:
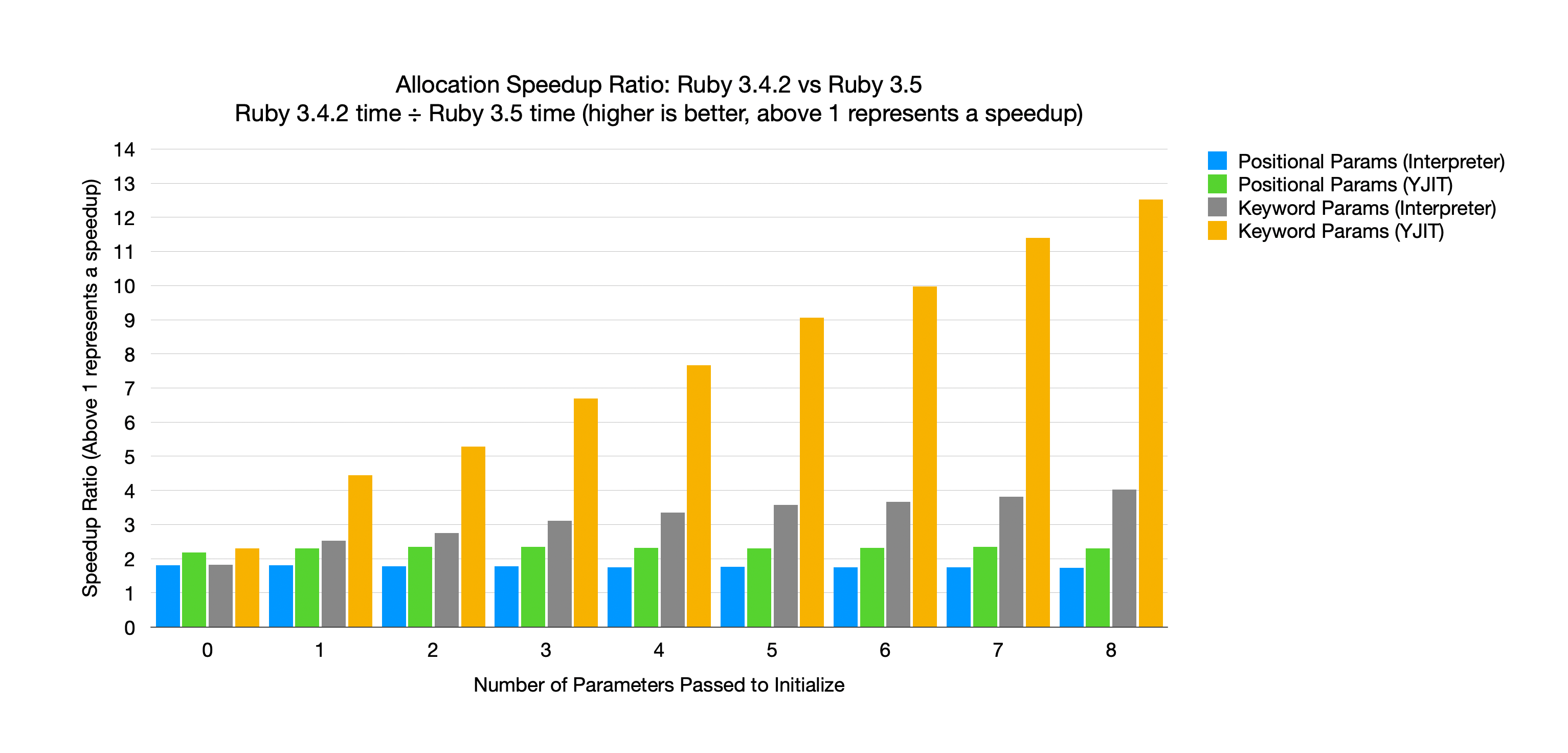 该图表说明了加速比,通过将 Ruby 3.4.2 上花费的时间除以 Ruby 3.5 上花费的时间来计算。 这意味着任何低于 1 的值都表示减速,而任何高于 1 的值都表示加速。 当我们将 Ruby 3.5 与 Ruby 3.4.2 进行比较时,我们要么在两个版本上都禁用 YJIT ,要么在两个版本上都启用 YJIT 。 换句话说,我们将 Ruby 3.5 与 Ruby 3.4.2 进行比较,并将 Ruby 3.5+YJIT 与 Ruby 3.4.2+YJIT 进行比较。
该图表说明了加速比,通过将 Ruby 3.4.2 上花费的时间除以 Ruby 3.5 上花费的时间来计算。 这意味着任何低于 1 的值都表示减速,而任何高于 1 的值都表示加速。 当我们将 Ruby 3.5 与 Ruby 3.4.2 进行比较时,我们要么在两个版本上都禁用 YJIT ,要么在两个版本上都启用 YJIT 。 换句话说,我们将 Ruby 3.5 与 Ruby 3.4.2 进行比较,并将 Ruby 3.5+YJIT 与 Ruby 3.4.2+YJIT 进行比较。
X 轴显示传递给 initialize 的参数数量,Y 轴是加速比。 蓝色条是不带 YJIT 的位置参数,绿色条是带 YJIT 的位置参数。 灰色条是不带 YJIT 的关键字参数,黄色条是带 YJIT 的关键字参数。
首先,我们可以看到所有条都高于 1,这意味着 Ruby 3.5 上的每种分配类型都比 Ruby 3.4.2 快。 位置参数具有恒定的加速比,而与参数数量无关。
位置参数比较
对于位置参数,加速比保持不变,而与参数数量无关。 在没有 YJIT 的情况下,Ruby 3.5 始终比 Ruby 3.4.2 快约 1.8 倍。 当我们启用 YJIT 时,Ruby 3.5 始终快约 2.3 倍。
关键字参数比较
关键字参数更有趣一些。 对于解释器和 YJIT ,随着关键字参数数量的增加,加速比也会增加。 换句话说,使用的关键字参数越多,此更改就越有效。
仅将 3 个关键字参数传递给 initialize ,Ruby 3.5 比 Ruby 3.4.2 快 3 倍,如果我们启用 YJIT ,则快超过 6.5 倍。
Class#new 中的瓶颈
我对加速分配(从而加速 Class#new)很感兴趣已经有一段时间了。 但是什么让它变慢了?
Class#new 是一个非常简单的方法。 它所做的只是分配一个实例,将所有参数传递给 initialize ,然后返回该实例。 如果我们要用 Ruby 实现 Class#new ,它看起来像这样:
class Class
def self.new(...)
instance = allocate
instance.initialize(...)
instance
end
end
该实现有两个主要部分。 首先,它使用 allocate 分配一个裸对象,其次,它调用 initialize 方法,转发 new 收到的所有参数。 因此,要加速此方法,我们可以加速对象分配,或者加速调用 initialize 方法。
加速 allocate 意味着加速垃圾收集器,虽然这样做有优点,但我希望专注于等式的运行时方面。 这意味着试图降低调用另一个方法的开销。 那么是什么让方法调用变慢呢?
从 Ruby 调用 Ruby 方法
Ruby 的虚拟机 YARV 使用堆栈作为处理值的暂存空间。 我们可以将此堆栈视为一个真正大的堆分配数组。 每次我们处理一个 YARV 指令时,我们都会读取或写入这个堆分配数组。 对于在函数之间传递参数也是如此。
当我们在 Ruby 中调用一个函数时,调用者在调用被调用者之前将参数推送到堆栈。 然后,被调用者从堆栈中读取其参数,进行任何它需要的处理,然后返回。
def add(a, b)
a + b
end
def call_add
add(1, 2)
end
例如,在上面的代码中,调用者 call_add 将在调用 add 函数之前将参数 1 和 2 推送到堆栈。 当 add 函数读取其参数以执行 + 时,它从堆栈中读取 a 和 b 。 调用者推送的值成为被调用者的参数。 你可以在我们最近的 关于启动 ZJIT 的文章 中看到这一点。
这种“调用约定”很方便,因为当参数变成被调用者的参数时,推送到堆栈的参数不需要复制到任何地方。 如果你检查存储 1 和 2 的内存地址,你会看到它们与用于 a 和 b 的值的地址相同。
从 Ruby 调用 C 方法
不幸的是,C 函数不使用与 Ruby 函数相同的调用约定。 这意味着当我们从 Ruby 调用 C 函数,或者从 C 调用 Ruby 函数时,我们必须将方法参数转换为它们各自的调用约定。
在 C 中,参数通过寄存器或机器堆栈传递。 这意味着当我们从 Ruby 调用 C 函数时,我们需要将值从 Ruby 堆栈复制到寄存器中。 或者当我们从 C 调用 Ruby 函数时,我们必须将寄存器值复制到 Ruby 堆栈。
这种调用约定之间的转换需要一些时间,所以这是一个我们可以进行优化的目标。
当从 Ruby 调用 C 函数时,位置参数可以直接复制到寄存器。
static VALUE
foo(VALUE a, VALUE b)
{
return INT2NUM(NUM2INT(a) + NUM2INT(b));
}
# 调用 `foo` C 函数
foo(1, 2)
在上面的例子中,在 ARM64 上,参数 a 和 b 将分别位于 X0 和 X1 寄存器中。 当我们从 Ruby 调用 foo 函数时,参数可以直接从 Ruby 堆栈复制到 X0 和 X1 寄存器。
不幸的是,对于关键字参数,转换并没有那么简单。 由于 C 不支持关键字参数,我们必须将关键字参数作为哈希传递给 C 函数。 这意味着分配一个新的哈希,迭代参数,并在哈希中设置它们。
当在 Ruby 3.4.2 上运行时,我们可以通过以下程序看到这一点:
class Foo
def initialize(a:)
end
end
def measure_allocations
x = GC.stat(:total_allocated_objects)
yield
GC.stat(:total_allocated_objects) - x
end
def test
measure_allocations { Foo.new(a: 1) }
end
# 在测量之前,我们需要预热调用点,因为内联缓存是 Ruby
# 对象,所以它们会扭曲我们的结果
test # 预热
test # 预热
p test
如果我们使用 Ruby 3.4.2 运行上面的程序,我们会看到 test 方法分配了 2 个对象: Foo 的一个实例,以及一个用于将关键字参数传递给 Class#new 的 C 实现的哈希。
实现分配加速
我想首先从一点历史开始。
我对加速分配很感兴趣已经有一段时间了。 我们知道从 Ruby 调用 C 函数会产生一些开销,并且开销取决于我们传递的参数类型。 所以我最初的倾向是用 Ruby 重写 Class#new 。 由于 Class#new 只是将其所有参数转发给 initialize ,因此使用三点转发语法 ( ... ) 似乎很自然。 你可以在这里找到我的初始实现的残余。 不幸的是,我发现使用 ... 非常昂贵,因为当时它是 *, **, & 的语法糖,Ruby 会分配额外的对象来表示这些 splat 参数。
这导致我实现了 ... 的优化。 ... 的优化允许我们使用参数转发而不分配任何额外的对象。 我认为这种优化通常很有用,但我想到的是将其用于 Class#new 。 几个月后,我能够使用这种新的优化在 Ruby 中实现 Class#new 。 最初的基准测试还不错,它消除了分配并降低了将参数从 new 传递到 initialize 的成本。 但我有点担心 这个调用点 的内联缓存未命中。
上面链接的 Class#new 实现有点复杂,但如果我们将其归结为本质,它本质上与我们在文章开头看到的 Class#new 实现相同:
class Class
def self.new(...)
instance = allocate
instance.initialize(...)
instance
end
end
上面代码的问题是 initialize 调用点的内联缓存。 当我们进行方法调用时,Ruby 会尝试缓存该调用的目标。 这样我们就可以加速在该调用点对相同类型的后续调用。
CRuby 只有一个单态内联缓存,这意味着它在任何特定的调用点只能存储一个内联缓存。 内联缓存用于帮助查找我们将要调用的方法,并且缓存的键是接收者的类(在本例中是 instance 局部变量的类)。 每次接收者的类型发生变化时,缓存就会未命中,我们必须对该方法进行慢速路径查找。
代码连续多次分配完全相同类型的对象的情况非常罕见,因此 instance 局部变量的类会非常频繁地变化。 这意味着我们可能会有非常糟糕的缓存命中率。 即使调用点可以支持多个缓存条目(一个“多态”内联缓存),这个特定调用点的基数也会非常高,以至于缓存命中率仍然会很差。
我向 Koichi Sasada (YARV 的作者)展示了这个 PR,他建议我们不要用 Ruby 实现 Class#new ,而是添加一个新的 YARV 指令并“内联” Class#new 的实现。 我与 John Hawthorn 合作实现了它,并且在一周内完成了原型实现。 幸运的是(或不幸的是),这个原型被证明比 Ruby 的 Class#new 实现_快得多_,所以我决定放弃这个努力。
内联 Class#new
那么什么是内联? 内联几乎只是从被调用者复制/粘贴代码到调用者。
Foo.new
每当编译器看到像上面这样的代码时,它不会生成一个简单的 new 方法调用,而是生成 new _本会使用_的指令,但在 new 的调用点。
为了使这更具体,让我们看看内联前后上面代码的指令。
以下是内联之前 Foo.new 的字节码:
> ruby -v --dump=insns -e'Foo.new'
ruby 3.4.2 (2025-02-15 revision d2930f8e7a) +PRISM [arm64-darwin24]
== disasm: #<ISeq:<main>@-e:1 (1,0)-(1,7)>
0000 opt_getconstant_path <ic:0 Foo> ( 1)[Li]
0002 opt_send_without_block <calldata!mid:new, argc:0, ARGS_SIMPLE>
0004 leave
以下是内联之后 Foo.new 的字节码:
> ./ruby -v --dump=insns -e'Foo.new'
ruby 3.5.0dev (2025-04-29T20:36:06Z master b5426826f9) +PRISM [arm64-darwin24]
== disasm: #<ISeq:<main>@-e:1 (1,0)-(1,7)>
0000 opt_getconstant_path <ic:0 Foo> ( 1)[Li]
0002 putnil
0003 swap
0004 opt_new <calldata!mid:new, argc:0, ARGS_SIMPLE>, 11
0007 opt_send_without_block <calldata!mid:initialize, argc:0, FCALL|ARGS_SIMPLE>
0009 jump 14
0011 opt_send_without_block <calldata!mid:new, argc:0, ARGS_SIMPLE>
0013 swap
0014 pop
0015 leave
在内联之前,这些指令查找常量 Foo ,然后调用 new 方法。 内联之后,我们仍然查找常量 Foo ,但不是调用 new 方法,而是有一堆其他的指令。
这些新指令中最重要的是 opt_new 指令,它分配一个新的实例并将该实例写入堆栈。 紧接在 opt_new 指令之后,我们看到一个对 initialize 的方法调用。 这些指令有效地分配了一个新实例并在该实例上调用 initialize ,与 Class#new _本会做_的事情相同,但实际上并没有调用 Class#new 。
真正好的是,任何推送到堆栈的参数_都留在堆栈上_以供 initialize 方法使用。 在我们必须在 C 实现中进行复制的地方,不再有任何复制! 此外,我们不再为 Class#new 推送和弹出堆栈帧,这进一步加速了我们的代码。
最后,由于每次调用 new 都包含对 initialize 的另一次调用,因此与纯 Ruby 的 Class#new 实现相比,我们具有非常好的缓存命中率。 不是_一个_ initialize 调用点,而是在每次调用 new 时都有一个 initialize 调用点。
消除堆栈帧,消除参数复制,并提高内联缓存命中率是这种优化的主要优势。
内联的缺点
当然,这种优化并非没有缺点。
首先,有更多的指令,所以它需要更多的内存使用。 然而,这种内存增加仅与使用 new 的调用点数量成比例增长。 我们在我们的 monolith 中测量了这一点,并且仅看到指令序列大小增长了 0.5%,这甚至只是总体堆大小的一小部分。
其次,这种优化引入了一个小的向后不兼容性。 考虑以下代码:
class Foo
def initialize
puts caller
end
end
def test
Foo.new
end
test
如果我们使用 Ruby 3.4 运行此代码,则输出如下所示:
> ruby -v test.rb
ruby 3.4.2 (2025-02-15 revision d2930f8e7a) +PRISM [arm64-darwin24]
test.rb:8:in 'Class#new'
test.rb:8:in 'Object#test'
test.rb:11:in '<main>'
如果我们使用 Ruby 3.5 运行此代码,则输出如下所示:
> ./ruby -v test.rb
ruby 3.5.0dev (2025-04-29T20:36:06Z master b5426826f9) +PRISM [arm64-darwin24]
test.rb:8:in 'Object#test'
test.rb:11:in '<main>'
Class#new 帧从 Ruby 3.5 中消失了,那是因为该帧已被消除。
结论
如果你已经看到了这里,我希望你觉得这个话题有趣。 我真的很高兴 Ruby 3.5 将于今年晚些时候发布,我希望你也一样! 我要感谢 Koichi Sasada 提出内联(以及 opt_new 指令)并感谢 John Hawthorn 帮助我进行实现。
如果你好奇,请查看pull request中的实现以及RedMine ticket中的讨论。 我没有解释此补丁的每个细节(例如,如果你在不是类的事物上调用 new 会发生什么?),因此,如果你有任何疑问,请随时通过电子邮件或社交媒体提问。
祝你愉快! Subscribe
- Shopify Engineering
The Ruby and Rails Infrastructure team at Shopify exists to help ensure that Ruby and Rails are 100-year tools that will continue to merit being our toolchain of choice.
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.