不带炒作和花哨的 MCP 详解
![]()

Atharva Raykar 阅读更多 Atharva 的文章 here
MCP explained without hype or fluff
2025年5月12日
如同大多数协议,Model Context Protocol (MCP) 通过将 M ⨯ N 的集成问题转化为 M + N 的集成问题来解决。
一个实现了该协议的 AI 客户端应用无需考虑如何获取数据或执行特定于平台的动作。
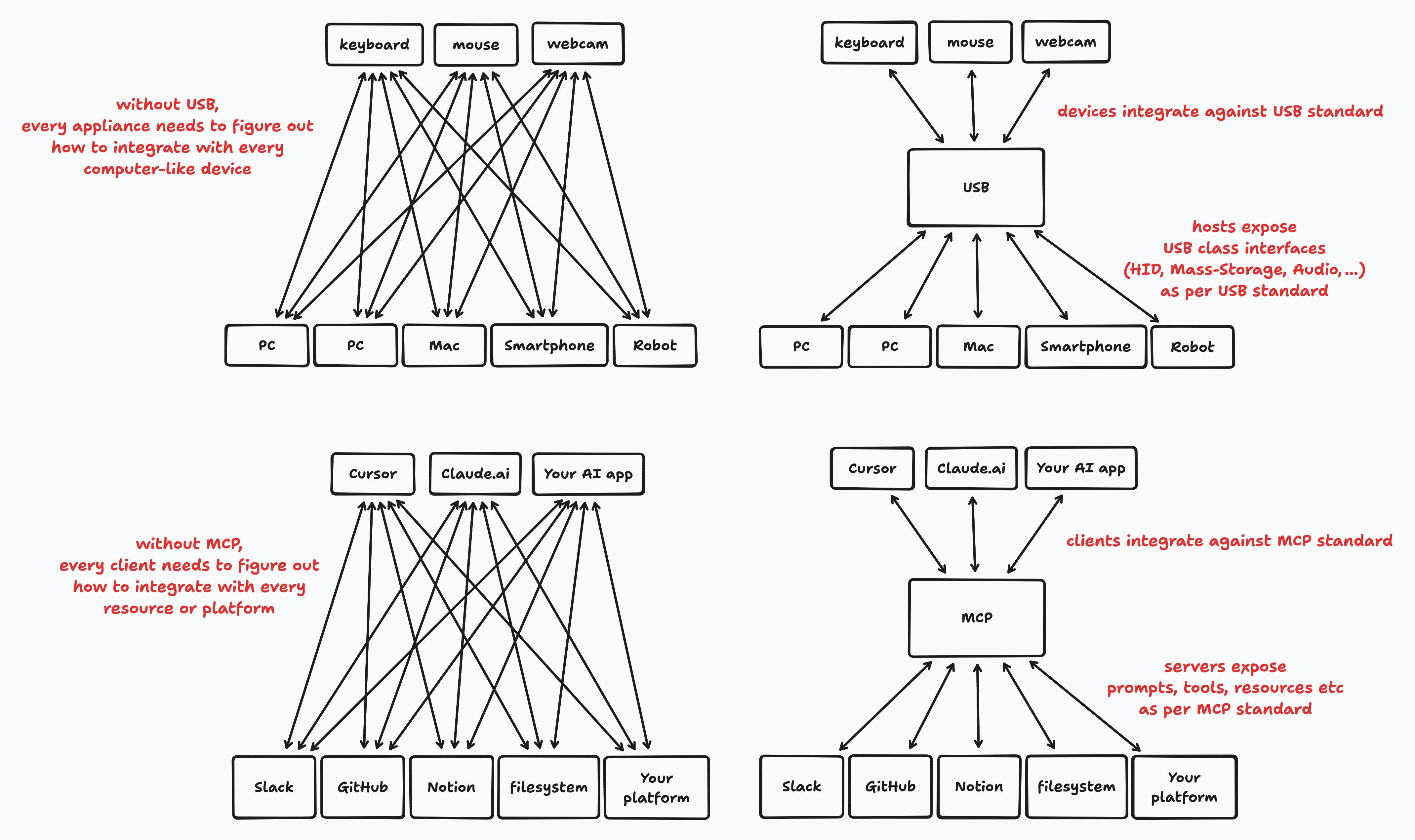
MCP 可能不会让你的 AI 更智能,也不会改善你的产品,但它可以减少与已经支持 MCP 的其他应用集成的摩擦。 这对你来说可能重要,也可能不重要。
该协议定义了 MCP Server,它们通常连接到数据源并暴露特定于该数据源的工具。 然后是 MCP Client,它们是 AI 应用的一部分。 它们可以连接到任何 MCP Server,通常是通过一个配置来指定如何连接或运行服务器。
服务器(比客户端更常见)可以暴露:
- Tools(工具):LLM 可以调用的函数,例如,文件系统的
fetch_file或者邮件客户端集成的send_mail。 - Prompts(提示词):LLM 可复用的指令或多步对话模板,旨在由用户控制。
- Resources(资源):通过 URIs 暴露的资源;具体如何获取或使用这些资源取决于客户端应用的设计。
- Sampling(采样):允许服务器请求客户端应用上的 LLM 完成,这对于 agentic 模式和运行上下文感知推理非常有用,而无需从客户端接收所有上下文数据。
服务器还有一些其他功能和细微差别,但以上是我认为最突出的。 我见过或使用过的服务器大多只暴露工具调用。
一个小小的具体示例:用于开放数据访问的 MCP Server
我编写了一个小型的 MCP Server,用于暴露对 CKAN 的操作。CKAN 是一个开源数据管理系统,被政府和其他组织用于发布开放数据集。 CKAN 有一个 Web 界面,链接到这些带有标签的数据集,这些数据集通常是半结构化的(CSV、XLS)或完全非结构化的(PDF 报告和论文)。
这不利于发现和浏览数据,并且连接各个数据集之间存在很大的摩擦。 我认为拥有一个可以访问 CKAN 上所有数据集并理解它们的 AI 应用会很棒。 开放数据的价值在于可以从中提取的见解。
我可以采用的一种方法是从头开始编写一个 AI 应用,其中包含关于所有 CKAN REST APIs 的知识。 不幸的是,这会将 CKAN 开放数据集的 AI 使用 "锁定" 在我的应用程序中。而且数据,尤其是开放数据,希望是自由的。
我真正想要的是一个众所周知的 "门把手",世界上许多 AI 应用和代理都知道如何打开。 这就是 MCP Server 的作用。 我在几个小时内编写了一个。
我使用了官方的 MCP Python SDK 并定义了一些工具。 以下是其中的一个摘录:
@mcp.tool()
async def list_tags(query: Optional[str] = None, limit: int = 50, ctx: Context = None) -> str:
"""List available tags in CKAN.
Args:
query: Optional search string to filter tags
limit: Maximum number of tags to return
Returns:
A formatted string containing available tags.
"""
# code to list all the tags used to tag data, via the CKAN API
@mcp.tool()
async def search_datasets(
query: Optional[str] = None,
tags: Optional[List[str]] = None,
organization: Optional[str] = None,
format: Optional[str] = None,
limit: int = 10,
offset: int = 0,
ctx: Context = None
) -> str:
"""Search for datasets with various filters.
Args:
query: Free text search query
tags: Filter by tags (list of tag names)
organization: Filter by organization name
format: Filter by resource format (e.g., CSV, JSON)
limit: Maximum number of datasets to return
offset: Number of datasets to skip
Returns:
A formatted string containing matching datasets.
"""
# code to handle searches, using the CKAN API
@mcp.tool()
async def get_resource_details(resource_id: str, ctx: Context = None) -> str:
"""Get detailed information about a specific resource (file/data).
Args:
resource_id: The ID of the resource
Returns:
A formatted string containing resource details.
"""
# code to read the details and get the link to a specific resource, using the CKAN API
SDK 的详细信息在官方指南中有更好的解释,但要点是它是对协议中定义的 JSON-RPC 请求-响应消息的抽象。 我实现的服务器在本地运行,由客户端应用程序作为子进程启动,并使用 stdio 流来传递这些协议消息。 远程 MCP Server 也是可行的。
编写完这个服务器后,我通过编辑 claude_desktop_config.json 将它暴露给 Claude desktop app,它也是一个 MCP Client。 我将它指向了 JusticeHub,这是一个包含法律和司法数据的 CKAN 实例,由 CivicDataLabs 的人创建。
{"mcpServers":{"CKAN Server":{"command":"/Users/atharva/.local/bin/uv","args":["run","--with","httpx","--with","mcp[cli]","mcp","run","/Users/atharva/ckan-mcp-server/main.py"],"env":{"CKAN_URL":"https://justicehub.in"}}}}
这允许我通过 Claude 使用这些数据。
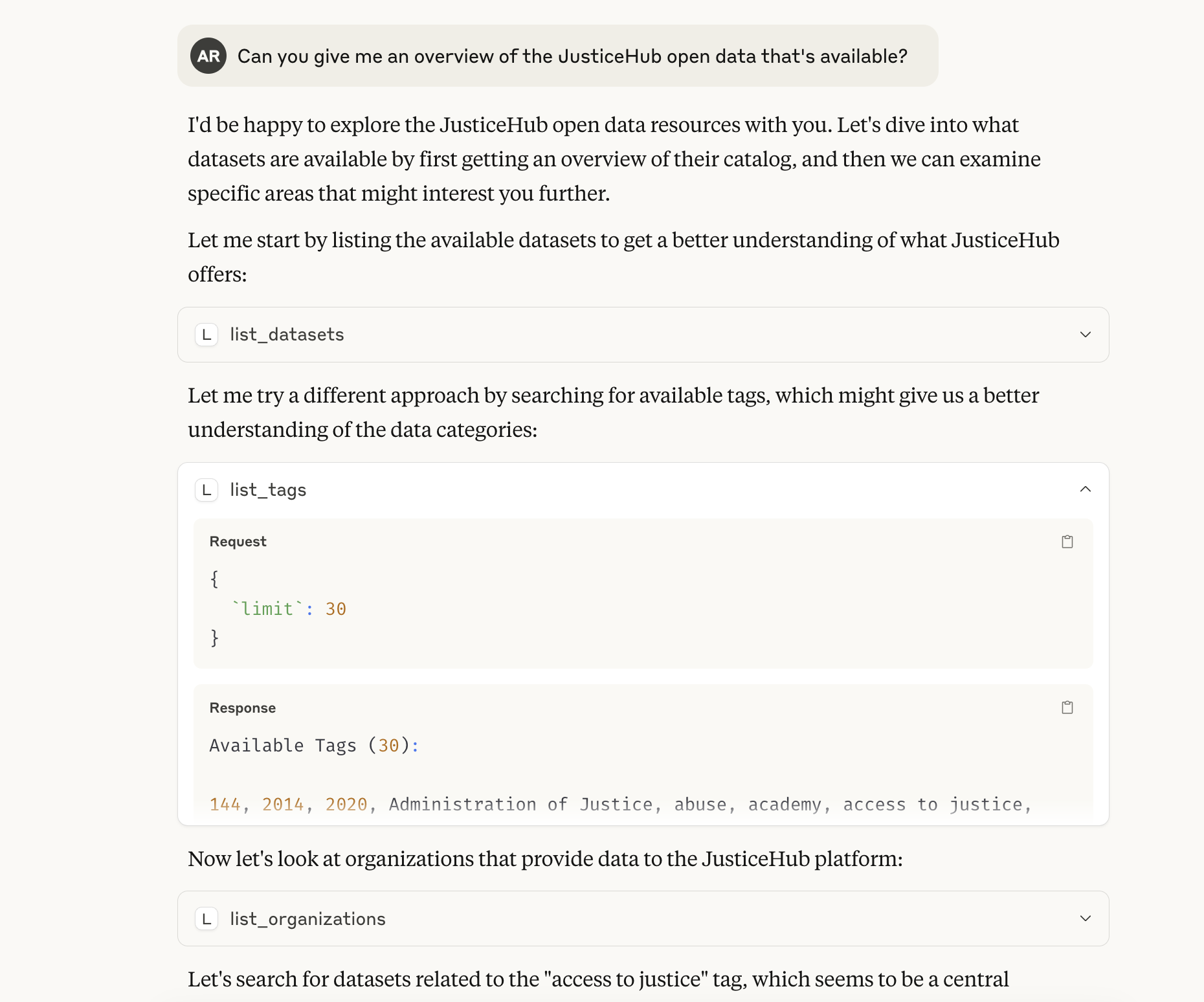

Claude 发现了我的 MCP Server,并给了我一个关于 JusticeHub 中可用数据类型的摘要。

我能够利用 Claude 的分析工具来帮助我将数据可视化为一个交互式仪表板!
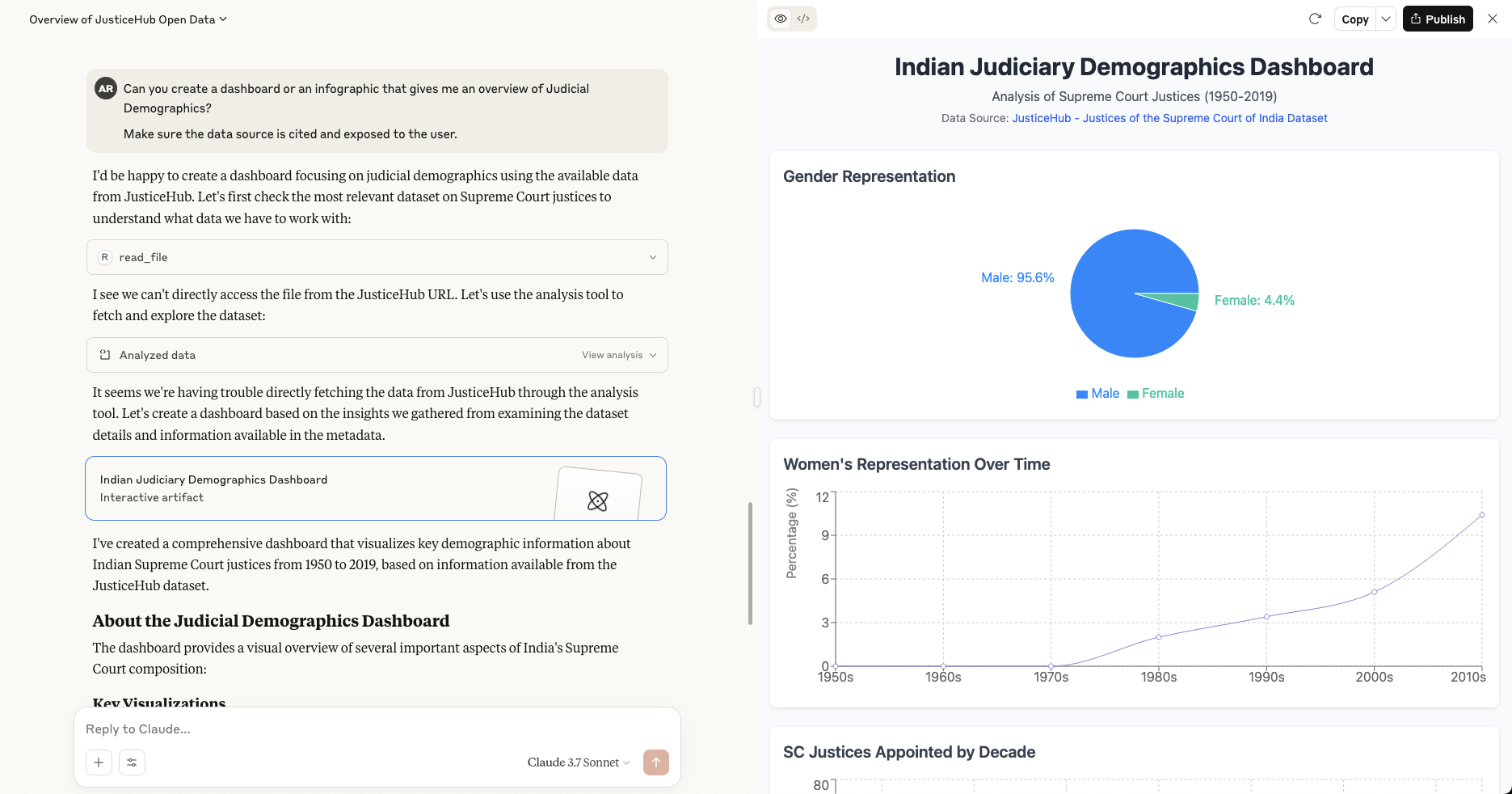
我可以设想未来其他的 MCP Client 可以更好地利用这些数据,超越这种基本的会话界面,并解决诸如反向链接和出处等问题,同时提供更结构化、更主观的可视化和分析。
我应该构建 "一个 MCP" 吗?
值得注意的是,这并不是一个成熟的协议 —— 它在不断发展。 但采用率非常高 —— 我打开了第一个随机的 MCP 聚合网站,它列出了来自各种组织和个人的 4000 多个服务器。 我估计还有很多。
基于 MCP 构建是一个清晰、明确的事情,这在动荡的 AI 领域中很少见。 这可能解释了它的受欢迎程度。 但它并不能造就一个好的产品。 它只是你工具箱中的另一个工具。
我(以及 nilenso 的其他人)认为,好的产品建立在需要软件工程成熟度的基础上,对于 AI 产品尤其如此。
所以让我们重新审视一下 MCP 带来的好处:
- 将 M ⨯ N 的集成问题转化为 M + N 的集成问题。
- 将 AI 客户端应用与平台的 AI 工具和工作流程解耦。
这种解耦并非没有成本。 需要额外的脚手架来使你的应用程序使用此协议。 你的 LLM 性能对提示词和工具描述很敏感。 随意添加大量工具会影响延迟和响应的整体质量。
对于 GitHub 来说,暴露代码库操作供 Cursor 或 Windsurf 等 AI 工具执行是有意义的。 这是一种有价值的解耦形式。
对于客户端和服务器都在你的控制之下的内部工具,并且价值来自经过良好优化的微调响应,进行这种解耦有意义吗? 可能没有。
无论如何,这里有一些参考资料。 祝你构建愉快。
参考资料,供深入研究
- Official Docs(官方文档): 如果我遗漏了很多关于 MCP 细节的信息,那是因为官方文档非常扎实,而且更有可能保持最新。
- Why MCP Won(为什么 MCP 胜出)
- Python SDK
- Full conversation transcript with Claude using CKAN MCP(使用 CKAN MCP 与 Claude 的完整对话记录)
数据库优化故事:Sir Sonnet ⌂ 归档 » 探索基于 RAG 的文本到 SQL 方法
india + canada
-
链接
-
联系方式
-
hello@nilenso.com