KumoRFM:用于关系数据 In-Context Learning 的基础模型
介绍 KumoRFM:用于关系数据 In-Context Learning 的基础模型
2025 年 5 月 20 日



 Matthias Fey, Vid Kocijan, Federico Lopez, Jure Leskovec
Matthias Fey, Vid Kocijan, Federico Lopez, Jure Leskovec

基础模型 (FMs) 已经完全占领了自然语言和图像等非结构化数据领域,在各种任务中都取得了显著的性能提升,而几乎不需要特定于任务的训练。 然而,结构化和半结构化的关系数据(代表了一些最有价值的信息资产)在很大程度上错过了这波 AI 浪潮。 为了在关系数据上使用 AI,从业者仍然使用传统的机器学习方法,并构建特定于任务和数据集的模型,这些模型需要大量的开发和调整时间。
我们推出了 KumoRFM,这是一个 Relational Foundation Model (RFM),它能够在关系数据库上进行准确的预测,涵盖广泛的预测任务,而无需数据或特定于任务的训练。 KumoRFM 将 in-context learning 的原理扩展到多表关系图设置。 该模型采用了一种表不变的编码方案和一个新颖的 Relational Graph Transformer,以在跨表的任意多模态数据中进行推理。
通过在 RelBench 基准测试上的广泛评估,涵盖了七个领域的 30 个预测任务,我们表明,平均而言,KumoRFM 的性能优于事实上的特征工程黄金标准以及端到端监督深度学习方法,在三种不同的任务类型中高出 2% 到 8%。 当在特定任务上进行微调时,KumoRFM 可以将其性能平均提高 10% 到 30%。 最重要的是,KumoRFM 比依赖于监督训练的传统方法快几个数量级。
Relational Foundation Models (RFMs)
关系数据通常以结构化表的形式存储在数据仓库中,代表用户记录、交易历史、供应链交互、产品目录、财务账簿和健康记录等实体。 此数据通常用于预测性问题,例如:“给定的交易是否为欺诈?”、“用户接下来可能与哪个项目互动?”、“用户会停止服务吗?”或“下个季度产品的销量是多少?”
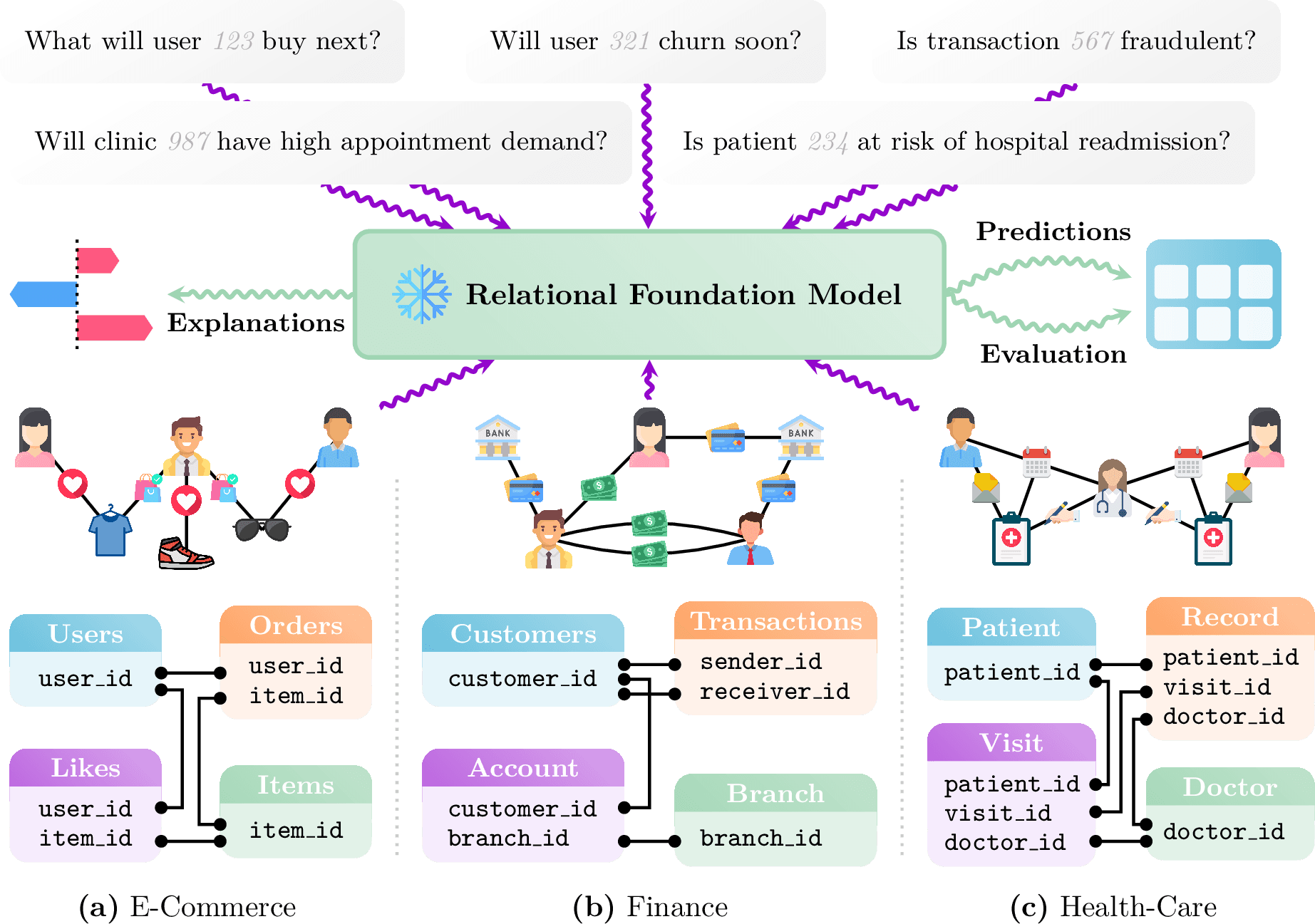
Relational Foundation Models 的关键能力。
为关系数据创建基础模型提出了独特的挑战。 这样的模型需要有效地学习跨越具有任意数量的表和列的复杂数据库模式,并处理列类型的固有异构性,这些列类型通常具有不同的语义含义。 必须解决几个悬而未决的问题:
- 关系数据的基础模型应该能够做什么?
- 它可以推广到它从未训练过的新数据库和任务吗?
- 它可以从几个 in-context 示例中提供准确的预测吗?
- 需要什么架构设计来处理关系复杂性?
- 需要什么数据才能有效地训练这样的模型?
什么是 KumoRFM?
KumoRFM 是一个为结构化、关系数据上的预测任务构建的基础模型,它借鉴了关系数据库上的表示学习和结构化数据的新兴基础模型领域这两个关键研究领域。
KumoRFM 接受以领域特定语言编写的查询作为输入,该语言称为 Predictive Query Language (PQL),它在语法上与 SQL 类似,但侧重于定义预测问题而不是数据操作运算。

从预测查询到任务类型的映射。 聚合方案和目标列的语义类型唯一地确定了底层机器学习任务。
每个 PQL 查询定义要预测的目标变量、应进行预测的实体集以及任何过滤器或聚合函数(例如,FIRST、COUNT、SUM、LIST_DISTINCT)。 支持的任务包括回归、二元分类、多类和多标签分类以及链接预测。 提交查询后,KumoRFM 会从底层关系数据库中检索相关数据,并自动生成上下文示例——标记的子图,用于捕获与预测任务相关的关系和历史模式。 然后,模型使用这些子图来推理当前查询。
该系统不需要特定于任务的训练。 相反,它通过从数据库中存储的历史数据中进行采样,从而在推理时应用 in-context learning。 这使得它可以在不重新训练底层模型的情况下处理新的数据集或任务。
KumoRFM 内部原理:架构和设计
KumoRFM 通过在内部将关系数据库转换为时态异构图来对关系数据库进行操作。 数据库中的每个表都被视为不同的节点类型,表中的行成为节点。 外键关系定义节点之间的边。 每个节点都可以携带多模态信息,例如数值、类别、时间戳、文本或向量嵌入。
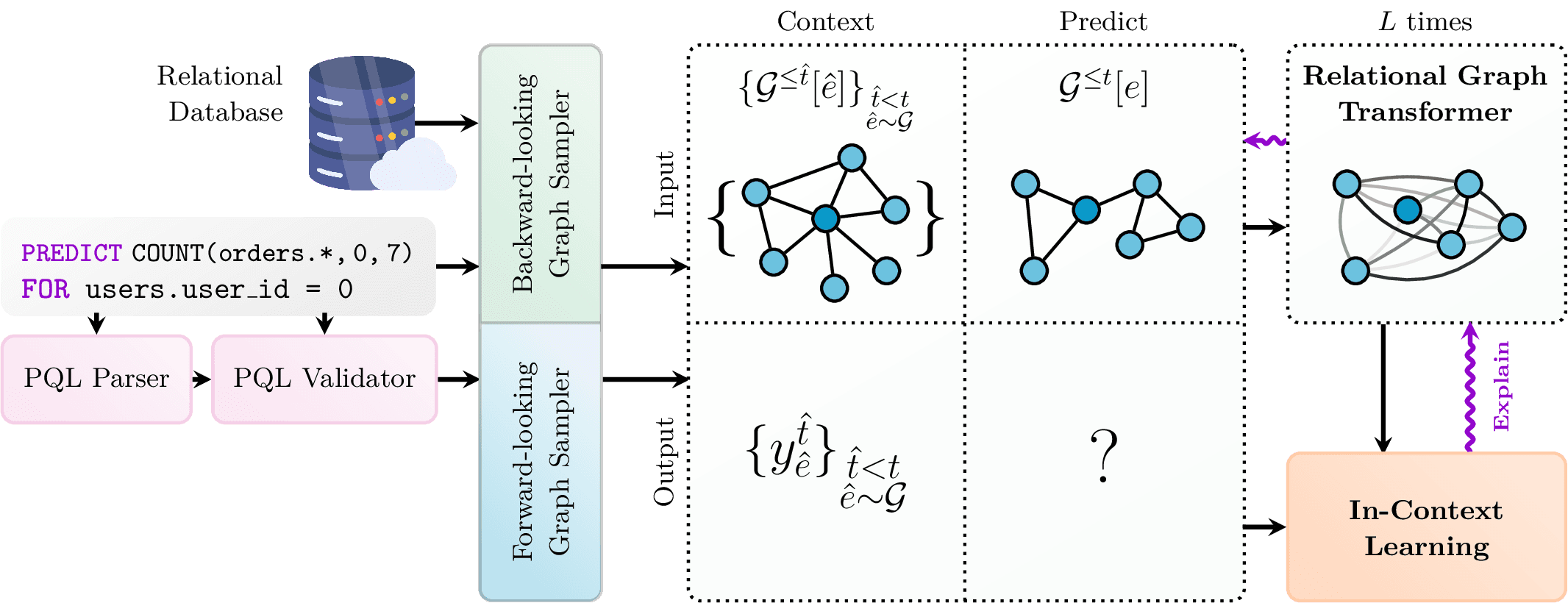
KumoRFM 架构概述。
该模型架构包含几个关键组件:
- 一个强大的实时 in-context 标签生成器,它可以动态地为任何时间点的任何实体管理特定于任务的上下文标签。
- 一个新颖的预训练 Relational Foundation Model,它可以无缝集成表宽度不变列编码器并执行表级注意力机制。 在这里,每个表中的每个单元格都基于列的语义类型(例如,数值、类别、时间戳)转换为密集向量表示。 之后,Relational Graph Transformer 使用节点类型、时间信息、结构邻近度(例如,距锚节点的跳跃距离)和本地子图模式的位置编码在图中执行注意力。 这一步使得模型能够整合相关表中的信息。
- 对于每个预测,KumoRFM 都会采样一组上下文示例——具有已知标签的历史子图——并将它们与测试子图一起编码。 in-context learning 模块使用这些示例来调节模型的预测,而无需任何监督训练要求。
- 一个全面的 可解释性模块,它利用分析和基于梯度的技术来提供全局数据级别以及单个实体的解释。
- 对于生产规模的部署或高吞吐量任务,KumoRFM 支持 微调。 在这些情况下,预训练模型可以专门用于特定的查询或数据集,从而将 in-context 推理机制替换为专用的监督管道。
这种架构使模型能够在任意关系模式上工作,处理数据异构性,并支持探索性和运营用例,而无需手动特征工程或自定义模型开发。
结论
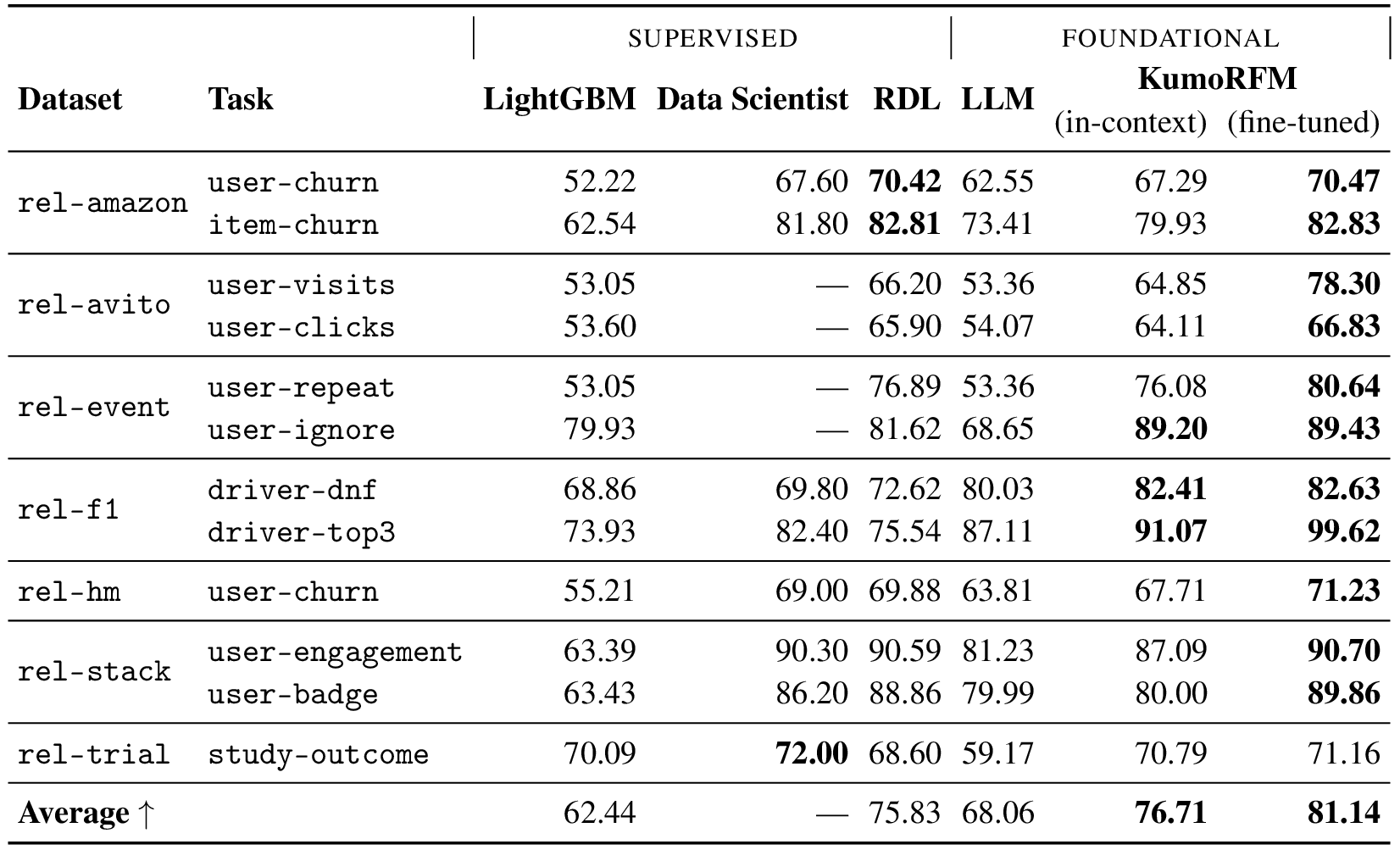
RelBench 中实体分类任务的测试结果 (AUROC)。 越高越好。 KumoRFM in-context 从 in-context 提供的示例中进行预测。 该模型没有在这些任务或数据集上进行训练。 KumoRFM fine-tuned 在每个特定任务上进行了微调。
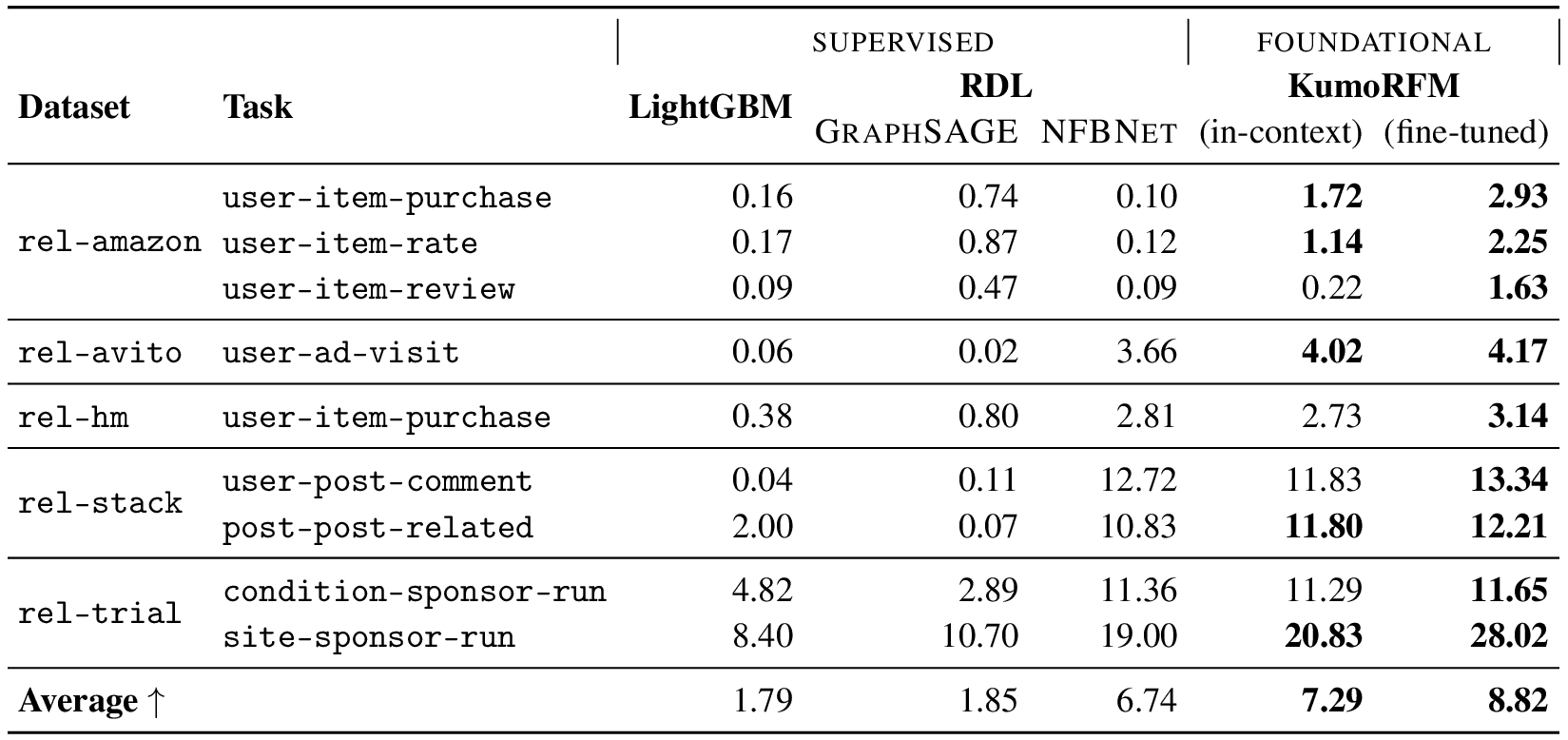
RelBench 中推荐任务的测试结果 (MAP@k)。 越高越好。 KumoRFM in-context 从 in-context 提供的示例中进行预测。 该模型没有在这些任务或数据集上进行训练。 KumoRFM fine-tuned 在每个特定任务上进行了微调。
KumoRFM 将预训练、in-context learning 和关系图推理集成到一个统一的结构化数据基础模型中。 基准测试结果揭示了几个关键发现:KumoRFM 实现了与专家设计的解决方案相当或更好的结果。 值得注意的是,即使没有特定于任务的训练,KumoRFM 的 in-context 功能也证明了与监督方法相比具有竞争力的性能。 当进行微调时,该模型在电子商务、社交、医疗和体育领域的多个分类、回归和推荐任务上建立了新的性能基准。 这些结果证明了基础模型在关系数据预测建模中的有效性。
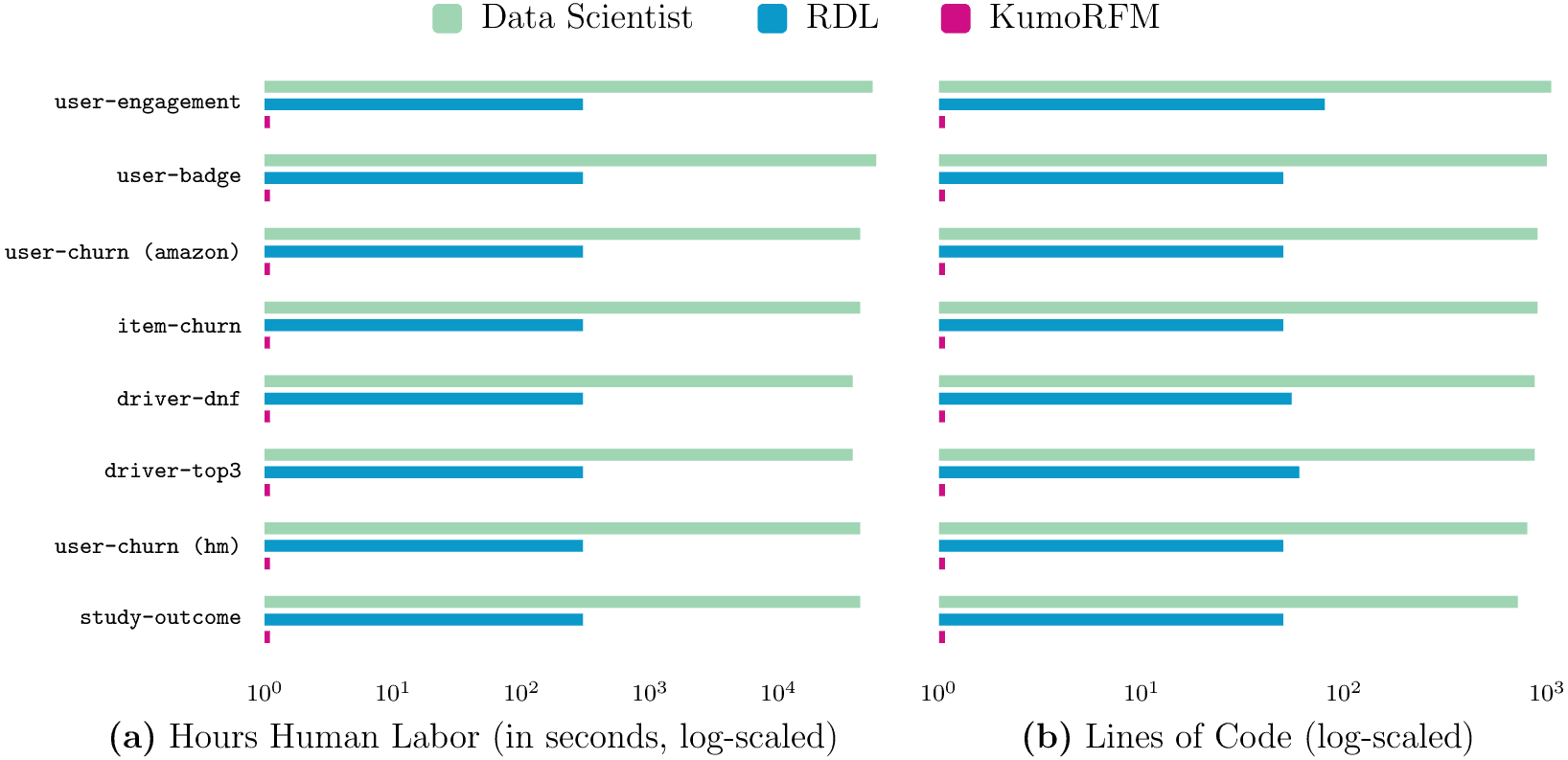
(a) 人工时和 (b) 代码行数 (LoC) 中首次预测的时间,在节点级分类任务上进行了说明。 与 Data Scientist 和 RDL 基线相比,KumoRFM 快几个数量级(≈1 秒 vs. ≈30 分钟 vs. ≈12.3 小时),并且需要零代码才能获得准确的预测(1 LoC vs. ≈56 LoC vs. ≈878 LoC)。
最重要的是,KumoRFM 比依赖于监督训练的传统方法快几个数量级,并提供了一个零代码解决方案,可以随时查询 任何 实体和 任何 目标。 这些结果突出了关系基础模型的核心价值主张:以最小的努力实现实时预测,为新一代的预测系统铺平道路,这些系统可以进行堆叠、查询和操作,以推动更快、更智能的业务决策。
要了解有关 KumoRFM 的更多信息,您可以在此处查看完整的白皮书。